By: Rekarius, CCRI, Asia University, Taiwan
Abstract
Phishing is a method used by phisher to trap potential victims to input their personal and financial data on the fake webpage created by phisher. platforms like email, SMS, instant chats are used to spread the fake webpage url. This paper represents a comparative analysis of machine learning based phishing de- tection and discusses some machine learning algorithms for identifying phishing. Based on 2 research papers, the results show that the random forest algorithm outperforms the other proposed algorithms.
Keywords phishing detection, machine learning, machine learning algorithms
Introduction
Phishing, a widespread and dangerous cyber-attack method, continues to pose significant threats in today’s digital world [3]. Phishing is a method used by phisher to trap potential victims to input their personal and financial data on the fake webpage created by phisher. platforms like email, SMS, instant chats are used to spread the fake webpage url. Falling victim to phishing attacks can have severe consequences, including identity theft, financial fraud, and repu- tational damage [1]. Machine learning (ML) algorithms, a subset of AI, offer the potential to detect and classify phishing attacks by analyzing patterns and indicators of fraudulent activity based on historical data [2]. The objective of this research paper is to compare the effectiveness of ML classification models in detecting phishing. This paper is ordered as follows. Section III represents Methodology. Section V Conclusion.
Methodology
Paper 1
In this [5] research, five machine learning algorithms have been used for detecting website phishing.
Decision Tree
The decision tree is one of the most widely used and practical inductive induc- tion techniques. The instances in the decision tree are categorized by sorting them according to feature values. A feature in an instance to be categorized corresponds to a node in the tree. Each tree branch indicates a value that the node can forecast.
Random Forest
Another common decision tree is the Random Forest (RF), which may be used for both classification and regression. RF is a collection of decision trees that have been trained separately on a set of training datasets. The classification information is then decided by a vote of all the trained participants.
K-Nearest Neighbour
The K-Nearest Neighbour (kNN) approach is a non-parametric supervised ma- chine method that has been effectively applied to a variety of real-world classi- fication and regression problems. The kNN algorithm assumes that cases in a training dataset are generally found near other instances with comparable char- acteristics. To put it another way, the class of the k nearest neighbor instances is used to detect any instance’s categorization choice.
Gaussian Naive Bayes
Naive Bayes can be extended to real-valued attributes by assuming a Gaussian distribution, which is the most frequent assumption. Because we only need to estimate the mean and standard deviation from our training data, the Gaussian (or Normal) distribution is the simplest to deal with.
XGBoost
The gradient boosted trees algorithm is implemented in XGBoost, a popular and efficient open-source implementation. The process for detecting phishing websites using supervised machine learning classifiers is shown in the diagram. To detect the phishing website, five steps must be completed, as shown in Fig. 4: dataset collection, feature extraction, feature selection, machine learning classifier training, and machine learning classifier evaluation. We have used hold out method. We have chosen 80dataset for the validation process. The purpose
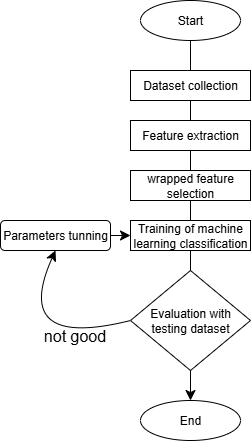
of using hold out method is to minimize the biased results. We choose random state 42. The expected outcomes have been achieved by utilizing the confusion matrix. Table 1 shows the overall results of the five algorithms.
Table 1: Performance of Various Machine Learning Models
Models | Accuracy (%) | Sensitivity (%) | Specificity (%) | F1 score (%) | AUC |
Decision Tree | 93.57 | 93.76 | 93.73 | 93.64 | 0.94 |
Random Forest | 97.0 | 96.41 | 97.49 | 96.99 | 0.99 |
K-Nearest Neighbors | 83.33 | 83.77 | 81.00 | 82.22 | 0.90 |
Gaussian Na¨ıve Bayes | 74.02 | 83.39 | 68.54 | 70.30 | 0.81 |
XGBoost | 94.79 | 96.41 | 94.73 | 94.73 | 0.99 |
Paper 2
In this [3] research study, their main objective was to identify the most effective machine-learning model for detecting phishing domains. To achieve this, we con- ducted experiments with seven distinct machine-learning techniques: Logistic Regression (LR), k-Nearest Neighbors (KNN), Support Vector Machine (SVM), Naive Bayes (NB), Decision Tree (DT), Random Forest (RF), and Gradient Boosting.
The Dataset
The research utilized a dataset obtained from the UCI machine-learning repos- itory, which can be accessed at [4]. The dataset contains 11,055 records, and each sample within the dataset is composed of 31 website parameters.
Dataset Representation
The dataset utilized in this research incorporates novel features that have been experimentally introduced [4], including the assignment of new rules to cer- tain well-known parameters. The dataset comprises 30 parameters, which are listed below: ’having IP Address’, ’URL Length’, ’Shortening Service’, ’hav- ing At Symbol’, ’double slash redirecting’, ’Prefix Suffix’, ’having Sub Domain’, ’SSLfinal State’, ’Domain registration length’, ’Favicon’, ’port’, ’HTTPS token’, ’Request URL’, ’URL of Anchor’, ’Links in tags’, ’SFH’, ’Submitting to email’, ’Abnormal URL’, ’Redirect’, ’on mouseover’, ’RightClick’, ’popUpWindow’,’Iframe’, ’age of domain’, ’DNSRecord’, ’web traffic’, ’Page Rank’, ’Google Index’, ’Links pointing to page’, ’Statistical report’.
Visualizing the Dataset
To gain further insights into the dataset and understand the relationship between its features, They generated a heatmap to visualize the pairwise correlations among the 30 parameters used in the research.
The Ten-fold Cross-validation Method
The ten-fold cross-validation method involves ten iterations with different data splits for training and testing, yielding a robust estimate of the model’s abilities. This approach mitigates bias and variance issues, providing a comprehensive evaluation of generalization to unseen data.
The Evaluation Metrics
The evaluation metrics are essential tools for assessing the performance of machine learning models. They provide quantitative measures of the model’s accuracy, precision, recall, and F1-score. They present the experimental results of their comparative study in Table 2
Table 2: Performance Comparison of Machine Learning Classifiers
Classifier | Accuracy | F1 score | Recall | Precision |
Gradient Boost | 97.2% | 96.9% | 97% | 96.8% |
Random Forest | 97.1% | 97.3% | 97.4% | 97.2% |
Decision Tree | 96.3% | 96.7% | 96.7% | 96.6% |
K-Nearest Neighbors | 95.6% | 96.2% | 96.8% | 95.7% |
Support Vector Machine | 93.9% | 95% | 96.4% | 93.7% |
Logistic Regression | 92.7% | 93.8% | 95% | 92.7% |
Na¨ıve Bayes Classifier | 60.1% | 45.3% | 29.3% | 99.2% |
References
- Zainab Alkhalil, Chaminda Hewage, Liqaa Nawaf, and Imtiaz Khan. Phish- ing attacks: A recent comprehensive study and a new anatomy. Frontiers in Computer Science, 3:563060, 2021.
- D. Gavrilut and I. Zaporojan. The use of machine learning algorithms for phishing detection. In 2019 International Conference on Innovations in Intelligent Systems and Applications (INISTA), pages 1–5, 2019.
- Kamal Omari. Comparative study of machine learning algorithms for phish- ing website detection. International Journal of Advanced Computer Science and Applications, 14(9), 2023.
- UCI Machine Learning Repository. Phishing Websites Data Set. https://archive.ics.uci.edu/ml/datasets/phishing+websites.
- Md Milon Uddin, Kazi Arfatul Islam, Muntasir Mamun, Vivek Kumar Ti- wari, and Jounsup Park. A comparative analysis of machine learning-based website phishing detection using url information. In 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), pages 220–224. IEEE, 2022.
- Gupta, B. B., Misra, M., & Joshi, R. C. (2012). An ISP level solution to combat DDoS attacks using combined statistical based approach. arXiv preprint arXiv:1203.2400.
- Jain, A. K., & Gupta, B. B. (2018). Rule-based framework for detection of smishing messages in mobile environment. Procedia Computer Science, 125, 617-623.
- Chhabra, M., Gupta, B., & Almomani, A. (2013). A novel solution to handle DDOS attack in MANET. Journal of Information Security Vol. 4 No. 3 (2013) , Article ID: 34631 , 15 pages
- Gupta, B. B., Gupta, S., Gangwar, S., Kumar, M., & Meena, P. K. (2015). Cross-site scripting (XSS) abuse and defense: exploitation on several testing bed environments and its defense. Journal of Information Privacy and Security, 11(2), 118-136.
- Khonji, M., Iraqi, Y., & Jones, A. (2013). Phishing detection: a literature survey. IEEE Communications Surveys & Tutorials, 15(4), 2091-2121.
- Aleroud, A., & Zhou, L. (2017). Phishing environments, techniques, and countermeasures: A survey. Computers & Security, 68, 160-196.
- Dhamija, R., Tygar, J. D., & Hearst, M. (2006, April). Why phishing works. In Proceedings of the SIGCHI conference on Human Factors in computing systems (pp. 581-590).
Cite As
Rekarius (2025) A Comparative Performance Analysis of Machine Learning Algorithms for Phishing Detection, Insights2Techinfo, pp.1