By: Reka Rius, CCRI, Asia University, Taiwan
Abstract
Spam classification is one of the important issues in the field of information security, and with the popularity of the Internet and the widespread use of email, spam has become one of the main factors affecting user experience and information security. This paper discusses the deep learning transformer model used in spam detection.
Keywords spam detection, deep learning, transfomer, distilbert
Introduction
Email is a popular communication mode. Individuals and organizations all over the world use email for both casual and formal correspondence and exchange significant amounts of data. As the number of email users continues to grow, spam emails are increasing in number, and attackers are becoming increasingly clever with their tricks [2]. Spam classification is one of the important issues in the field of information security, and with the popularity of the Internet and the widespread use of email, spam has become one of the main factors affecting user experience and information security [6]. This study focuses on a spam detection model based on BERT.
Method
The methods discussed in this study are derived from two papers:
Paper 1: BERT and Machine Learning Classifier Al- gorithms
BERT
BERT, one of the most popular transformer-based models, is an encoder stack of transformer structure and applies the bidirectional training of transformer to language modeling [1]. BERT architectures have extensive feedforward networks and attention heads [2]. It takes a classification (CLS) token and a sequence of words as input. Each layer uses self-attention and passes the result through a feedforward network to the next encoder. The output corresponding to the CLS token can be used for the classification task.
Feature extraction
Transfer learning uses the trained model to acquire knowledge for a specific application whereas pretrained models were usually trained using big datasets. In this study, a pretrained BERT model produces word embedding from email texts, and they are then used as features to represent the texts for further processing.
Classification
After the features were obtained on the email text using a pretrained BERT model, spam detection becomes a classification problem, and a classifier in ML is used to solve it via classifying the feature vectors into spam or ham categories. Supervised classifiers were first trained on the feature sets, and then the tuned classifiers were employed to classify the unknown samples. The metric results with average and standard deviation on dataset 1 are compared in Table 1 and the results on dataset 2 are compared in Table 2.
Table 1: Evaluation results for different machine learning algorithms on dataset 1
Algorithm | Precision | Recall | F1 score | AUC |
SVM | 0.9772 ± 0.0102 | 0.9769 ± 0.0102 | 0.9770 ± 0.0102 | 0.9964 ± 0.0028 |
Logistic Regression | 0.9786 ± 0.0081 | 0.9783 ± 0.0081 | 0.9784 ± 0.0081 | 0.9971 ± 0.0024 |
Random Forest | 0.9639 ± 0.0204 | 0.9634 ± 0.0204 | 0.9635 ± 0.0204 | 0.9946 ± 0.0006 |
KNN | 0.9654 ± 0.0308 | 0.9637 ± 0.0343 | 0.964 ± 0.034 | 0.9905 ± 0.0069 |
Table 2: Evaluation results for different machine learning algorithms on dataset
2
Algorithm | Precision | Recall | F1 score | AUC |
SVM | 0.9553 ± 0.0278 | 0.9656 ± 0.037 | 0.9596 ± 0.0127 | 0.9943 ± 0.0053 |
Logistic Regression | 0.9595 ± 0.0337 | 0.9600 ± 0.0338 | 0.9592 ± 0.0232 | 0.9950 ± 0.0045 |
Random forest | 0.9591 ± 0.0365 | 0.8692 ± 0.0296 | 0.9064 ± 0.0284 | 0.9847 ± 0.0137 |
KNN | 0.9372 ± 0.0545 | 0.9251 ± 0.0394 | 0.9307 ± 0.0437 | 0.9794 ± 0.0139 |
Paper 2: DistilBERT Deep Learning Algorithm
Dataset
The dataset used in this paper is selected from the open source spam dataset published by MIT, which contains more than 190,000+ emails labelled as spam and non-spam. Each email is represented by its text content and its correspond- ing tag.
Data Preprocessing
The data preprocessing process begins by defining three functions for text data preprocessing, namely text preprocessing, drop stopwords, and delete one characters.The text preprocessing function performs a number of processes on the text data, including converting the text to lowercase, removing the contents of square brackets, non-word characters, links, HTML tags, punctuation, line breaks and words containing numbers. Next, the drop stopwords function re- moves stop words from the text based on a collection of English stop words. Finally, the delete one characters function removes words of length 1 from the text to avoid interference with subsequent classifiers. Subsequently, in applying the preprocessing functions and label encoding functions to the dataset, the original dataset was first copied to a new dataset full data. Then, the complete preprocessing process for text data was achieved by applying the preprocessing function to each line of text data named text column in turn and storing the processing results in the new column preprocessed text. Finally, the label en- coder is used to encode the classification labels in the column named label and the encoding results are stored in the new column encoded label for use in the machine learning model.
DistilBERT
DistilBERT is a lightweight BERT-based model designed to reduce the size and computational cost of BERT models while maintaining high performance [3]. DistilBERT achieves this by using distillation techniques to extract knowl- edge from large, pre-trained language models, and then transfer this knowl- edge to smaller, faster models, thus achieving reduced performance while main- taining the computational resource requirements. Compared with the original BERT, DistilBERT employs several streamlining and optimisation strategies [4, 5]. Firstly, DistilBERT reduces the number of layers and hidden units of the Transformer encoder to reduce the number of parameters. Second, DistilBERT introduces a technique called ”knowledge distillation” to improve performance by allowing smaller models to learn how to reproduce the predictions of larger models. In addition, during pre- training and fine-tuning, DistilBERT employs a number of regularisation methods to further improve generalisation.
In principle, DistilBERT utilises a teacher-student network framework for knowledge distillation. A teacher-student network is a framework in which a
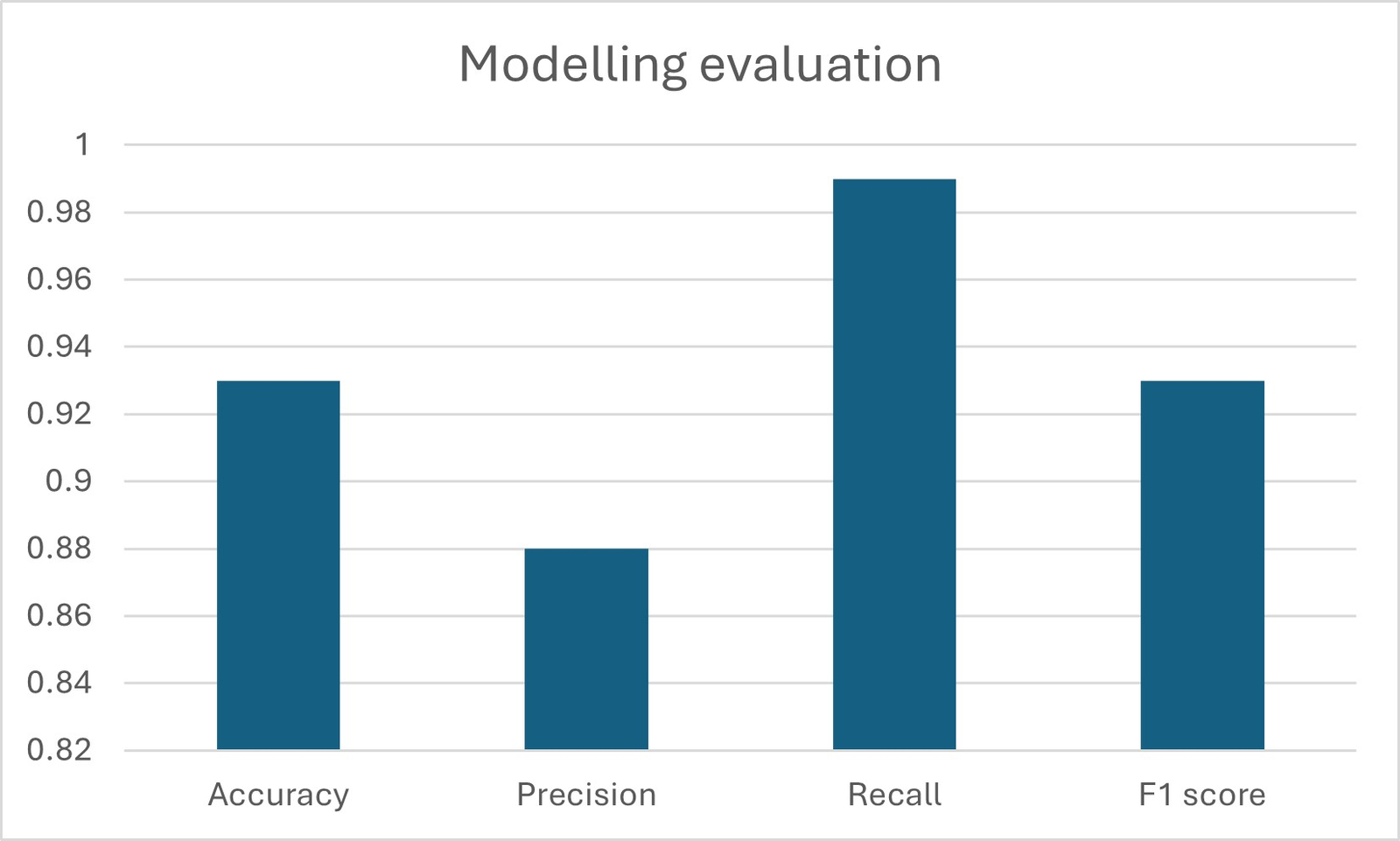
large teacher model (BERT) and a small student model (DistilBERT) partici- pate in training. During training, the teacher model generates soft labels, i.e., predictions in the form of probability distributions; while the student model at- tempts to learn the knowledge embedded in the teacher model by minimising the difference between the soft labels and its own predictions. In this way, although the student model is small, it can still acquire information from the rich rep- resentation space of the teacher model and gradually approach or even surpass the teacher model performance [7]. Overall, DistilBERT, as a lightweight and efficient language representation learning model, shows good performance in nat- ural language processing tasks. Through distillation techniques and structural optimisation, it reduces resource consumption while maintaining high accuracy, allowing more application scenarios to benefit from the powerful pre-trained lan- guage representation learning technique. The Accuracy, Precision, Recall and F1 scores of the model are shown in Figure 1.
Conclusion
During the application of DistilBERT model, a satisfactory classification accuracy of 93% was achieved. The model demonstrated good performance in distinguishing spam and non-spam emails, showing in the confusion matrix that most of the emails were correctly classified, but there were also a small number of spam emails that were misclassified as non-spam emails and non-spam emails that were misclassified as spam emails. The paper 1 experimental results demonstrate the logistic regression algorithm achieved the best classification performance in two publicly available datasets. To sum up, there is a promotion to use the BERT model and classifier in spam detection.
References
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume 1, pages 4171–4186. Association for Computational Linguistics, 2019.
- Yanhui Guo, Zelal Mustafaoglu, and Deepika Koundal. Spam detection using bidirectional transformers and machine learning classifier algorithms. journal of Computational and Cognitive Engineering, 2(1):5–9, 2023.
- Yanjie Li, Tianrui Liu, Dongxiao Jiang, and Tao Meng. Transfer-learning- based network traffic automatic generation framework. In 2021 6th Interna- tional Conference on Intelligent Computing and Signal Processing (ICSP), pages 851–854. IEEE, 2021.
- Tianrui Liu, Qi Cai, Changxin Xu, Bo Hong, Fanghao Ni, Yuxin Qiao, and Tsungwei Yang. Rumor detection with a novel graph neural network approach. arXiv preprint arXiv:2403.16206, 2024.
- Yuhong Mo, Hao Qin, Yushan Dong, Ziyi Zhu, and Zhenglin Li. Large language model (llm) ai text generation detection based on transformer deep learning algorithm. arXiv preprint arXiv:2405.06652, 2024.
- Pengyu Mu, Wenhao Zhang, and Yuhong Mo. Research on spatio-temporal patterns of traffic operation index hotspots based on big data mining tech- nology. Basic & Clinical Pharmacology & Toxicology, 128:111, 2021.
- Ao Xiang, Jingyu Zhang, Qin Yang, Liyang Wang, and Yu Cheng. Research on splicing image detection algorithms based on natural image statistical characteristics. arXiv preprint arXiv:2404.16296, 2024.
- Al-Ayyoub, M., AlZu’bi, S., Jararweh, Y., Shehab, M. A., & Gupta, B. B. (2018). Accelerating 3D medical volume segmentation using GPUs. Multimedia Tools and Applications, 77(4), 4939-4958.
- Gupta, S., & Gupta, B. B. (2015, May). PHP-sensor: a prototype method to discover workflow violation and XSS vulnerabilities in PHP web applications. In Proceedings of the 12th ACM international conference on computing frontiers (pp. 1-8).
- Gupta, S., & Gupta, B. B. (2018). XSS-secure as a service for the platforms of online social network-based multimedia web applications in cloud. Multimedia Tools and Applications, 77(4), 4829-4861.
- Liu, X., Lu, H., & Nayak, A. (2021). A spam transformer model for SMS spam detection. IEEE Access, 9, 80253-80263.
- Uddin, M. A., Islam, M. N., Maglaras, L., Janicke, H., & Sarker, I. H. (2025). Explainabledetector: Exploring transformer-based language modeling approach for sms spam detection with explainability analysis. Digital Communications and Networks.
- Ghourabi, A., & Alohaly, M. (2023). Enhancing spam message classification and detection using transformer-based embedding and ensemble learning. Sensors, 23(8), 3861.
Cite As
Rekarius (2025) A Review of Transformer-Based and Machine Learning Approaches for Spam Detection, Insights2Techinfo, pp.1