By: Reka Rius, CCRI, Asia University, Taiwan
Abstract
Telegram is an instant messaging application with a large user base that can be a target for cybercrime, such as spam containing malicious links. This ar- ticle, using a literature review, compiles five machine learning algorithms that can be used to detect spam on Telegram. The dataset used was obtained from Kaggle. The dataset contains 20,000 messages, which can be classified as spam or malicious (70-30%). Five machine learning models were applied: Extreme Gradient Boosting (XGB), Light Gradient Boosting Machine (LGBM), Cat- Boosting, Support Vector Machine (SVM), and K-Nearest Neighbors (KNN). Simulation results show that the SVM algorithm performs very well, achiev- ing 94% accuracy, while the KNN algorithm performs the lowest, with 73% accuracy.
Keywords Spam, Telegram, Extreme Gradient Boosting, Light Gradient Boosting Machine, CatBoosting, Support Vector Machine, K-Nearest Neigh- bors.
Introduction
Continuously receiving messages from unknown sources can be mentally drain- ing and may interfere with users ability to notice or focus on important com- munications. In addition, these messages often contain harmful phishing links. Unfortunately, few platforms particularly messaging applications are equipped with dedicated spam filtering systems, despite the critical importance of such tools in preventing potential harm or losses. Consequently, the modern world faces the challenge of monitoring incoming text streams in social networks and messengers [4]. In this article, five machine learning algorithms used to de- tecting the spam on the telegram platform are analyzed: Extreme Gradient Boosting, Light Gradient Boosting Machine, CatBoosting Ensemble Method, Support Vector Machine, and K-Nearest Neighbors.
Literature analysis
Machine Learning Algorithms
Machine learning (ML) is a branch of mathematics, computing and statistics which deals with the design of algorithms that can learn [2]. Five (5) different ML algorithms were employed in this study which include XGB, LGBM, Cat- Boosting Ensemble Method, Support Vector Machine, and K-Nearest Neighbor.
Materials and Methods
Dataset Description
The Telegram spam dataset used in this study was obtained from Kaggle. The dataset contains 20,000 messages which can be classified into spam or ham (70- 30%) [3].
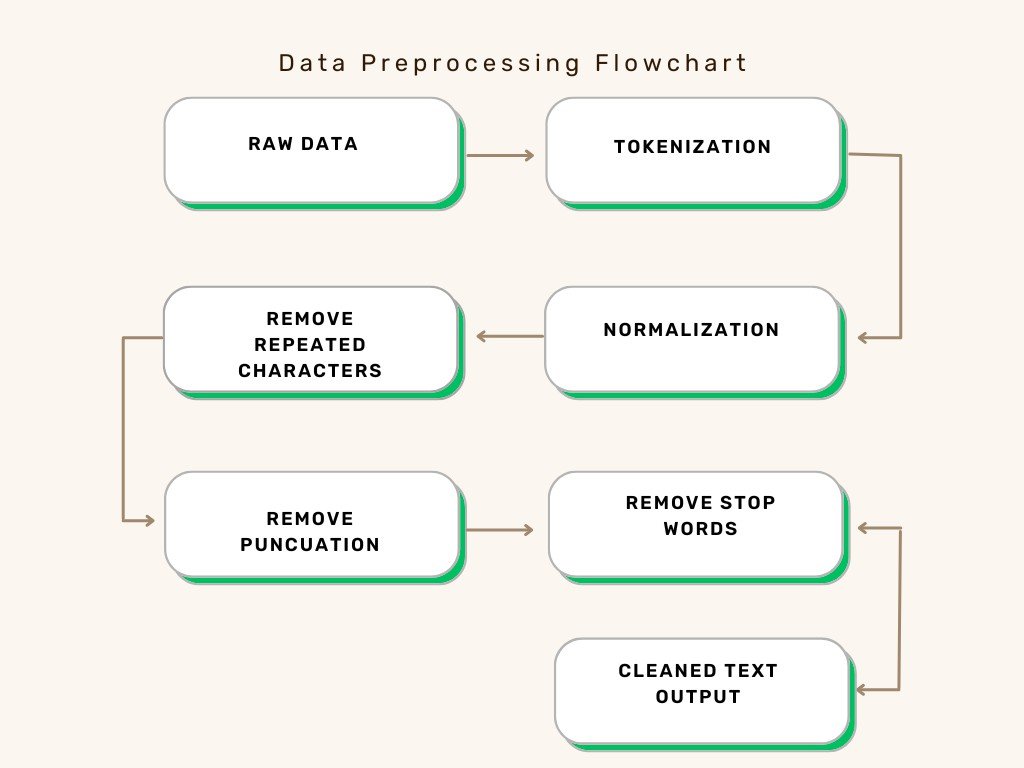
Data Preprocessing
Techniques were employed to remove noise from the dataset that could affect the system’s accuracy and perform data cleansing. The techniques include Tokeniza- tion, normalization, removing repeated chars, removing punctuations, removing stop words. Pre-processing cleans and normalises the text data to ensure that it is in a consistent format [3].
Feature Extraction
Extracting suitable features is the first step in employing machine learning al- gorithm for classification problems. This facilitates the identification of spam
contents and their transformation into numerical feature vectors. Content fea- tures that represent the text included in the Telegram messages were extracted. Language features are used, namely Term-Frequency-based (TFIDF). TFIDF is the most popular feature extraction technique. It normally transforms all sen- tences as a vector of term frequencies (TF) and assigns a score for each word in the text based on the number of times its occurrence and the probability it can be found in texts. The relative importance of a term in a document compared to other words in the corpus can be shown by TF-IDF [3].
Extreme Gradient Boosting
XGB is a tree-based ensemble algorithm which employs a gradient boosting machine learning technique for accomplishing regression and classification tasks. XGB uses level0algorithms to grow trees. It is different from the RF algorithm in the way it grows, orders, and combines the results. It employs a variety of algorithms for split finding. Trees grow in leaf-wise manner when histogram is used. The method works by bucketing features values into group of bins to construct features in histogram. The splitting is performed on the bins instead of on the features. The bucket bins are constructed before each tree is built. As a result, it speeds up the training which in turn reduces the computation complexity [1].
Light Gradient Boosting Machine (LGBM)
LightGBM is essentially an ensemble algorithm which combines the predictions of multiple decision trees by adding them together to make the final prediction that generalizes better [3].
CatBoosting Ensemble Method
The CatBoost algorithm, also known as categorical boosting, belongs to the gra- dient boosting family within the domain of machine learning. The method was specifically designed to effectively handle categorical data, making it suitable for both quantitative and qualitative variables [3].
Support Vector Machine
SVM algorithm is employed for both linear and nonlinear data classification. It uses a nonlinear mapping to convert the primary training set into an upper-level size. SVM explores for the linear optimal separating hyperplane in this new size as a decision border by which the tuples of one class from another are being split [3].
K-Nearest Neigbour (K-NN)
The k-NN algorithm is a classic classification model based on the principle of nearest learning examples in the feature space. It learns by analogy which
means the comparison of a provided test tuple with training tuples which are similar. These tuples must be the closest ones to the unknown tuple. A distance metric like Euclidean distance describes the “closeness”. To classify k-nearest neighbour, the tuple that is not known is selected as the most common class among its k- nearest neighbor [3].
Performence Metrics
The detailed results of the performance metrics are presented in the Table 1.
Table 1: Classifiers’ performance
Classifier | Precision | Recall | F-Measure | Accuracy |
XGBoost (spam) | 0.94 | 0.70 | 0.80 | 0.90 |
LGBM (spam) | 0.94 | 0.69 | 0.80 | 0.90 |
CatBoost (spam) | 0.94 | 0.69 | 0.80 | 0.90 |
SVM (spam) | 0.92 | 0.87 | 0.89 | 0.94 |
K-NN (spam) | 0.54 | 0.43 | 0.48 | 0.73 |
Conclusion
According to the performance metrics obtained, each algorithm can be sorted based on the performance shown in detecting spam, as follows: SVM, CatBoost, LGBM, and K-NN.
References
- Fatimah Alzamzami, Mohamad Hoda, and Abdulmotaleb El Saddik. Light gradient boosting machine for general sentiment classification on short texts: a comparative evaluation. IEEE access, 8:101840–101858, 2020.
- Emmanuel Gbenga Dada, David Opeoluwa Oyewola, and Joseph Hurcha Yakubu. Power consumption prediction in urban areas using machine learn- ing as a strategy towards smart cities. Arid Zone Journal of Basic and Applied Research (AJBAR), 1(1):11–24, 2022.
- Abubakar Hassan, Yusuf Ayuba, Mohammed Aji Wajiro, and Muham- mad Zaharadeen Ahmad. Machine learning algorithms for telegram spam filtering. FUDMA JOURNAL OF SCIENCES, 8(6):170–176, 2024.
- Sharifah Md Yasin and Iqbal Hadi Azmi. Email spam filtering technique: challenges and solutions. Journal of Theoretical and Applied Information Technology, 101(13):5130–5138, 2023.
- Arya, V., Gaurav, A., Gupta, B. B., Hsu, C. H., & Baghban, H. (2022, December). Detection of malicious node in vanets using digital twin. In International Conference on Big Data Intelligence and Computing (pp. 204-212). Singapore: Springer Nature Singapore.
- Lu, Y., Guo, Y., Liu, R. W., Chui, K. T., & Gupta, B. B. (2022). GradDT: Gradient-guided despeckling transformer for industrial imaging sensors. IEEE Transactions on Industrial Informatics, 19(2), 2238-2248.
- Sedik, A., Maleh, Y., El Banby, G. M., Khalaf, A. A., Abd El-Samie, F. E., Gupta, B. B., … & Abd El-Latif, A. A. (2022). AI-enabled digital forgery analysis and crucial interactions monitoring in smart communities. Technological Forecasting and Social Change, 177, 121555.
- Crawford, M., Khoshgoftaar, T. M., Prusa, J. D., Richter, A. N., & Al Najada, H. (2015). Survey of review spam detection using machine learning techniques. Journal of Big Data, 2(1), 23.
- Jindal, N., & Liu, B. (2007, May). Review spam detection. In Proceedings of the 16th international conference on World Wide Web (pp. 1189-1190).
- Markines, B., Cattuto, C., & Menczer, F. (2009, April). Social spam detection. In Proceedings of the 5th international workshop on adversarial information retrieval on the web (pp. 41-48).
Cite As
Rius R. (2025) Comparative Analysis Machine Learning Algorithms for Spam Detection on the Telegram Platform, Insights2Techinfo, pp.1