By: Akshat Gaurav, Asia University, Taiwan
Abstract
When the data used to train a model is corrupted, artificial intelligence becomes prone to data poisoning attack. Poisoning attacks contaminate the training data to cause systematic misbehavior, performance degradation, or the installation of backdoors that only activate after experiencing a specific trigger. This article puts together the most recent research on poisoning threats, attack modes, real-world contexts (especially in the IoT realm and other security-critical domains), and defence strategies. We explore the effects of poisoning on accuracy, detectability, and trust in various AI applications, including vision systems and intrusion detection. We also look at strategies for detection, forensic and resilience. Data sanitization has limitations. So, there is a need for end-to-end defenses in the future. This themes shows the wide range of poisoning considerations and stresses the diverse efforts needed to develop robust and trustworthy AI ecosystems.
Introduction
When training data is deliberately manipulated, it leads to the development of models which behave undesirably. This is what data poisoning essentially is. Unlike perturbations designed for evasion at test time, poisoning attacks exploit the data-generation pipeline itself. Thus, they aim to corrupt the model right from the start [1], [2]. Hackers can do this by creating mismatched records, building inputs, or hiding backdoors when training occurs. This will cause less accuracy, bias inference or secret misclassification after seeing a certain signal [1], [2]. A significant type of poisoning involves choosing labels or samples that confuse learning, while keeping nominal performance on benign data; it is referred to as clean-label poisoning in the literature [1]. At the same time, backdoor or Trojan-like poisoning seeks to train a model to react similarly to specific triggers. This can impact security-critical AI systems without apparent deterioration on usual inputs [3], [4].
Centralized and distributed training environments may face threat landscapes. In scenarios like IoT and edge, where different devices feed into a data stream that is aggregated for either central or federated learning, poisoning can propagate through large pipelines with less effective input validation. This amplification increases the potential harm. Defensive research has thus expanded to the front-end data pipeline and the learning process itself, including attempts to sanitize inputs, detect abnormal training patterns, and forensically attribute poisonous signals in high complexity models [1], [2]. Although several defenses have been proposed, they face serious difficulties. For instance, it is shown that data sanitization methods can be evaded using sophisticated poisoning techniques. Another example is the challenge of real-time detection in resource-constrained environments, which is an open problem.
The article presents a survey of the collection of data-poisoning attacks, the working mechanisms of these attacks as well as the catalog of defense strategies that are currently being developed. According to [5], [6], poisoning can impair performance and erode trust across a range of domains, from CNNs in computer vision to neural networks in IoT security infrastructures. Also effective defenses must be integrated and cross-layer, covering the data, model, and deployment contexts. This synthesis is informed by select studies illustrating (i) attack types such as (a) conducted black-box poisoning utilizing conditioned generative models (e.g., image classifiers), (b) label-flipping for individual-target poisoning in binary and multiclass scenarios, and (c) poisoning directed at multiple targets, (ii) empirical observations relative to degradation thresholds, (iii) detection and forensic techniques, and (iv) domain-specific consequences (security and resilience) on deployed systems [5], [2], [1], [4].
Threat Landscape and Attack Vectors Attack Surfaces.
Data poisoning takes advantage of weak points in the learning process. These weak points include data collection, labeling and annotation processes, and model training workflows. In an IoT-enabled ecosystem and distributed learning environment, risk exposure increases as data is collected from numerous devices and it is mostly aggregated before learning takes place with limited oversight [5, 3]. The unification of different data sources and federated architectures increases the attack surface. Therefore, stronger defenses will need to work at the data governance, communication, and aggregation levels [5], [3].
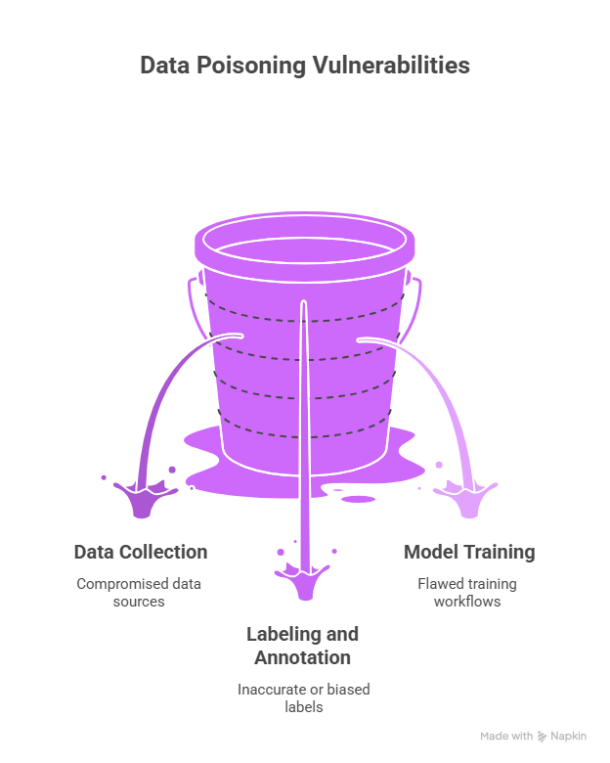
Attack Goals.
Poisoning attacks are typically designed to (a) degrade overall predictive accuracy, (b) bias model outputs in undesirable ways, or (c) implant covert backdoors that activate under specific stimuli. Degradation can be global or targeted, depending on the attacker’s objectives and poisoning strategy. Empirical work shows that when the proportion of poisoned data is significant, model performance and detection capabilities can deteriorate substantially, emphasizing the practical risk even under imperfect data curation [2], [6]. Backdoors represent a particularly pernicious class because they enable attacker-controlled behavior without widespread impairment during normal operation, posing a security risk for mission-critical AI systems [3], [4].
Attack Techniques
A spectrum of poisoning methods has emerged in the literature: (i) poisonous-label attacks, where attackers inject mislabeled examples to misguide learning in black-box settings with limited knowledge about the target model; (ii) data-poisoning attacks designed to bypass data sanitization defenses, underscoring the fragility of sanitizers under adaptive adversaries [6]; (iii) backdoor or Trojan-style poisoning, where concealed triggers cause deliberate misclassification; and (iv) GAN-based poisoning techniques that generate poisoned samples or labels to confound the learner even under constrained access [2], [1], [4]. Notably, multi-target poisoning demonstrates that a single poisoning strategy can undermine multiple classes, increasing the potential impact [4]. Some attacks operate in real-time or near real-time settings, highlighting the need for rapid detection and remediation pipelines [6]. GAN-enabled approaches illustrate how attackers can craft sophisticated poisoned samples that are difficult to distinguish from benign data [1].
Attack Impacts
Poisoning can reduce a model’s reliability by degrading its accuracy and weakening its detection abilities, thus harming an IoT, security, and safety-sensitive system. For example, experiments show that the performance starts to drop faster as the poisoning rates increase. The performance starts to degrade when the amount of poisoned data crosses a threshold (for instance order of tens of percent of training data) [2], [6]. Poisoned models can allow for clever evasion and impairment of operability in defense systems in security-relevant environments such as intrusion detection, mobile AI, and edge AI, showing the realistic relevance of poisoning and its effect in the wild as opposed to showy academia [3], [4]. The linked threats reduced reliability, weakened resilience, and hidden manipulation pose several risks to trust in AI systems in risk critical environments [5], [3].
Defenses, Forensics, and Resilience Data Sanitization and Its Limitations
Data sanitization, a common first line of defense, aims to purge anomalous training points before model fitting. However, adaptive attackers have been shown to bypass sanitization schemes by exploiting weaknesses in distance-based, loss-based, or spectral detectors [6], indicating a cat-and-mouse dynamic between attackers and sanitizers. This finding motivates a shift toward more robust, multi-layer defenses that do not rely solely on anomaly filtering in the input space [1].
Detection, Forensics, and Meta-Classification
Besides sanitization, recent work proposes real-time detection approaches and forensic analyses that examine internal model behavior to expose latent indicators of manipulation. Techniques includes anomalies-aware monitoring, model inversion, topical and attribution-based techniques which aim to identify deviations of the learned encodings or decision paths [6], [3]. Semi-supervised meta-classifiers have emerged as a promising technique for using both labeled and unlabeled signals for training to detect neural trojans and the related backdoor phenomena [3]. Checks in input space are less robust than forensic analysis framework which integrates structural, geometric, statistical and interpretability cues to identify poisoning (similar to Box 4).
Domain-Specific Defenses and Ecosystem-Level Considerations.
In an IoT and federated setup, defenses need to consider distributed data sources and model updates and privacy. We can make use of attention-based aggregation and anomaly detection in federated architectures to reduce the impact of poisoning attacks in the context of IoT where centralized data collection is not possible or is not desired [5], [3]. The purposes of forensic and detection-oriented approaches are particularly important for high-stake systems where verification and accountability after-the-fact are essential. An example of such systems is usingML-based intrusion detection systems for security testing of the system [7]. As the various models highlight, the ecosystem-level resilience necessitates data governance, secured aggregation, and continual monitoring during the ML life cycle [5], [3].
Open Challenges and Future Directions
- Integrated data governance and integrity assurance: Ensuring high-quality, provenance-verified training data across centralized and decentralized pipelines remains essential, particularly in IoT and federated settings [5], [3].
- Robust, multi-layer defenses: The limitations of data sanitization in isolation motivate defense stacks that combine anomaly detection, forensic analysis, and resilient training pipelines to withstand adaptive poisoning [1], [6].
- Domain-specific resilience: Tailoring detection and mitigation to target domains (e.g., intrusion detection, medical imaging, or autonomous systems) will require context-aware strategies and empirical benchmarking under realistic threat models [5], [3].
- Forensic auditing and accountability: Developing standardized forensic workflows that can attribute poisoning signals to data sources or learning steps will be crucial for trust and compliance in high-stakes applications [3].
- Evaluation benchmarks and threat models: Continued work is needed to converge on common, reproducible benchmarks that capture the diversity of poisoning techniques (poisonous-label, backdoor, multi-target, GAN-based) and deployment settings [2], [4].
Conclusion
Data poisoning is a threat to AI models that probably not many people are aware of. It deteriorates performance under the radar while introducing secret behaviours that undermine trust and safety. The studies reveal that there are many ways of poisoning. Some samples might not be accurately labeled. The other options are multi-target approaches, backdoor triggers, and GAN-facilitated schemes. Real-world systems can suffer even in the case of moderate poisoning rates. Their accuracy and detection capabilities would get deteriorated. As defences evolve, they are transitioning away from purely input-space sanitisation and towards layered detection and forensic capabilities combined with resilience across devices. This evolution is particularly evident in the IoT and federated learning. As systems become more integrated with intelligence, researchers have to advance holistic instrument that cover data governance, learning pipeline to make them secure, and evaluation competence in order to make data poisoning detectable and it will be mitigated systematically. The answer lies in interdisciplinarity getting together data integrity, robust machine learning, security engineering, and governance. We can convert data poisoning from an accidental risk into an engineering problem.
References
- H. Liu, D. Li, & Y. Li, “Poisonous label attack: black-box data poisoning attack with enhanced conditional dcgan”, Neural Processing Letters, vol. 53, no. 6, p. 4117-4142, 2021. https://doi.org/10.1007/s11063-021-10584-w
- C. Dunn, N. Moustafa, & B. Turnbull, “Robustness evaluations of sustainable machine learning models against data poisoning attacks in the internet of things”, Sustainability, vol. 12, no. 16, p. 6434, 2020. https://doi.org/10.3390/su12166434
- U. Butt, O. Hussien, K. Hasanaj, K. Shaalan, B. Hassan, & H. Al-Khateeb, “Predicting the impact of data poisoning attacks in blockchain-enabled supply chain networks”, Algorithms, vol. 16, no. 12, p. 549, 2023. https://doi.org/10.3390/a16120549
- O. Mengara, “A backdoor approach with inverted labels using dirty label-flipping attacks”, Ieee Access, vol. 13, p. 124225-124233, 2025. https://doi.org/10.1109/access.2024.3382839
- Z. Wang, B. Wang, C. Zhang, Y. Liu, & J. Guo, “Defending against poisoning attacks in aerial image semantic segmentation with robust invariant feature enhancement”, Remote Sensing, vol. 15, no. 12, p. 3157, 2023. https://doi.org/10.3390/rs15123157
- P. Koh, J. Steinhardt, & P. Liang, “Stronger data poisoning attacks break data sanitization defenses”, Machine Learning, vol. 111, no. 1, p. 1-47, 2021. https://doi.org/10.1007/s10994-021-06119-y
- N. Allheeib, “Securing machine learning against data poisoning attacks”, International Journal of Data Warehousing and Mining, vol. 20, no. 1, p. 1-21, 2024. https://doi.org/10.4018/ijdwm.358335
- G. Monkam, J. Yan, & N. Bastian, “A forensic analysis framework for machine learning model poisoning detection”, Security and Privacy, vol. 8, no. 5, 2025. https://doi.org/10.1002/spy2.70079
Cite As
Gaurav A. (2025) Data Poisoning: The Silent Killer of AI Models, Insights2Techinfo, pp.1