By: C S Nakul Kalyan, CCRI, Asia University, Taiwan
Abstract
With the growing advancements of digital technology, the creation of fake celebrity interviews has increased and has become more common, where the fake content will easily become viral, and it can mislead the public. To find such fake content, we need to analyze both textual and audio data to find the difference between the original and deepfake content. In this paper, we will go through the multimodal approaches, which include text, audio, and video signals, to find the fake interviews. We will also discuss the creation of automated algorithms that assess the content authenticity, identify speech and video anomalies, and identify false assertions. While using these technologies, we can prevent the spread of viral misinformation while maintaining the public discourse’s integrity.
Keywords
Fake Celebrity Interviews, Fabricated Fame, Viral Deception, Multi-model analysis, Text and audio analysis, deepfake technology, Artificial intelligence.
Introduction
In the growth of digital media, fake content has become more and more prevalent, which makes fake celebrity interviews and edited fake statements viral, misleading the public [2]. The processes of manual fact-checking, which lead to an effective measure of finding misinformation and deepfakes it are time- consuming [3]. This situation created a big demand for automated tools that can detect deepfake content while consuming less time and producing accurate results, mainly in situations of various modes such as text, audio, and video cues. By using human resources, such as personal skills or achievements, pro- duces challenges which has the same issues in digital media verifications. The traditional interview techniques are respectful to human biases and inefficiencies, such as judgments made by appearances, which lead to the inconsistent assessments of talented individuals [5]. Technologies such as Natural language processing, facial recognition systems have made the simplification work easier, as they can detect the inconsistencies and verify that the content is applicant- provided information. This article goes through the detection of fabricated celebrity interviews with evaluating the text, audio, and video contents [1]. With these advancements, automated systems can easily find the fake and mis- leading content, and it will reduce the spread of fake statements. This proposed method will be useful for social media platforms and other fast checkers to dif- ferentiate between the original and deepfake contents that use digitally edited interviews and reduce the manual efforts [4].
Proposed Methodology
The Proposed method for detecting Fake Celebrity Interviews contains a multi- modal framework that works with text, audio, and video cues. This system combines the Natural Language Processing, speech analysis, and emotion recognition systems, which use these technologies to identify the deepfake content [3] Which as shown in Figure 1. The process includes:
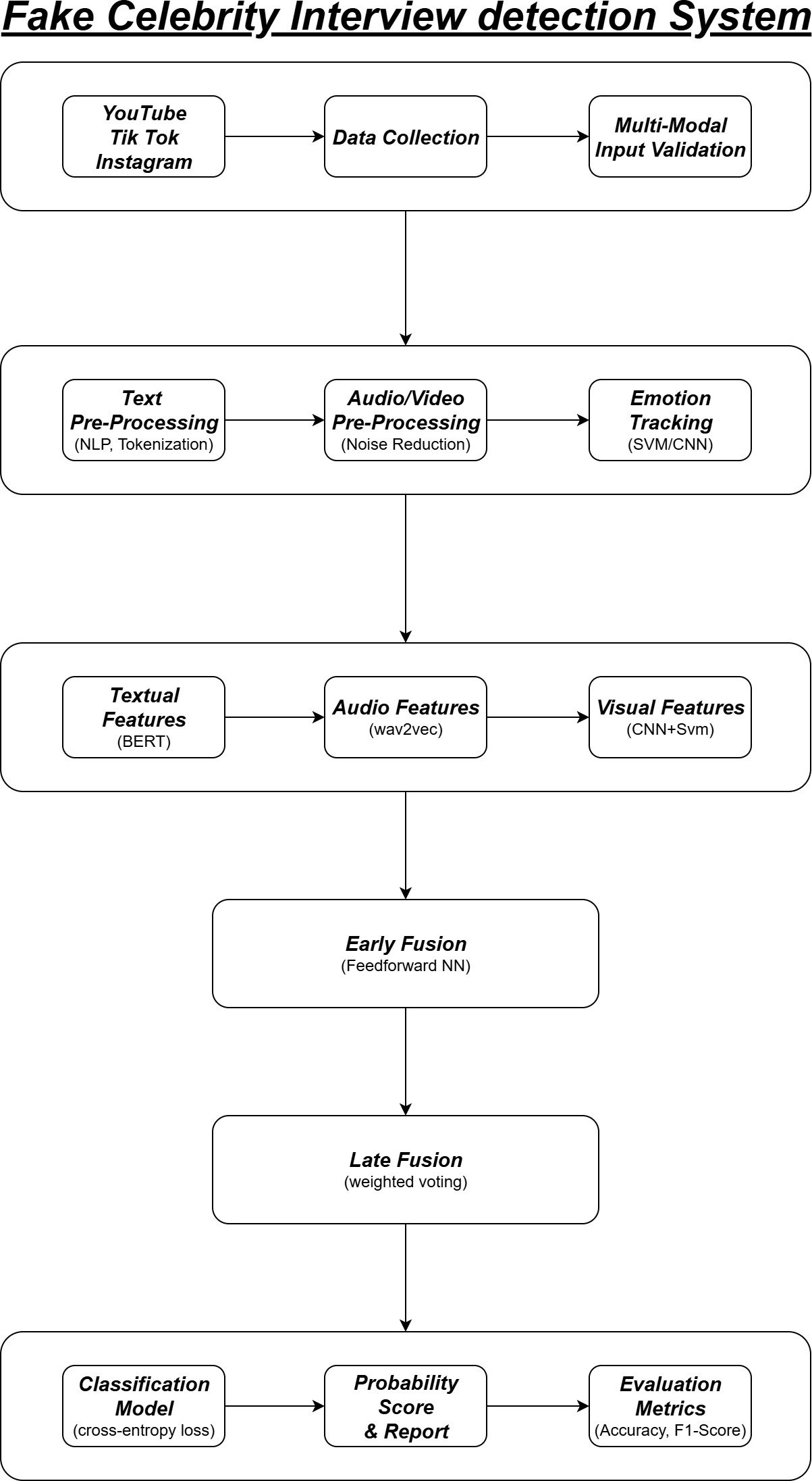
Data collection
The Process of data collection is as follows:
Source Aquisition
From platforms like YouTube, TikTok, and Instagram, the datasets of the celebrity interview videos and transcripts have been collected and saved from the above-mentioned sources [2].
Authenticity Labelling
The authenticity Labeling will be used to classify weather the video clips are original interviews or AI-generated, deepfake videos [5].
Multi-modal Inputs
The multi-model input makes sure that the samples have both textual transcripts and audio/video signals, as in the databases, which ensures the samples are not manipulated [3].
Pre-processing
The pre-processing is divided into 3 types such as:
Text Pre-Processing
It will clean the transcripts, such as removing the filters, normalize the slang, and punctuation, which will apply the NLP Tokenization and named-entity recognition to detect based on the claims which is made by the celebrities [1].
Audio/video Pre-processing
To remove the background distractions, the process of noise reduction is being done, and to detect the lip-sync and emotional manipulations, the facial features such as eyes, lips, and jawline is also being extracted [3].
Emotion and expression Tracking
The expression tracking is used to detect unnatural facial expressions in the deepfake video by using the SVM/CNN-based emotional recognition system [4].
Feature Extraction
The feature extraction will be done separately for the different features, such as text, audio, and video, and the extraction process is done as:
Textual Features
It uses the BERT or DistilRoBERT for sentence embedding, where it identifies the unusual statements, such as the fabricated texts, which is present in the samples [1].
Audio features
It uses wav2vec 2.0/Hubert to extract the unwanted or latent speech embed- dings, in which it will find the tone and pauses in the voice to catch the robotic or mismatched voice in the audio [3].
visual Features
It uses the CNN+SVM models to classify the emotions and find the facial mis- matching, where it is used to detect the inconsistencies, such as frame glitches, etc [4]. The whole Multi-model and feature extraction, and future strategies are shown in Figure 2.
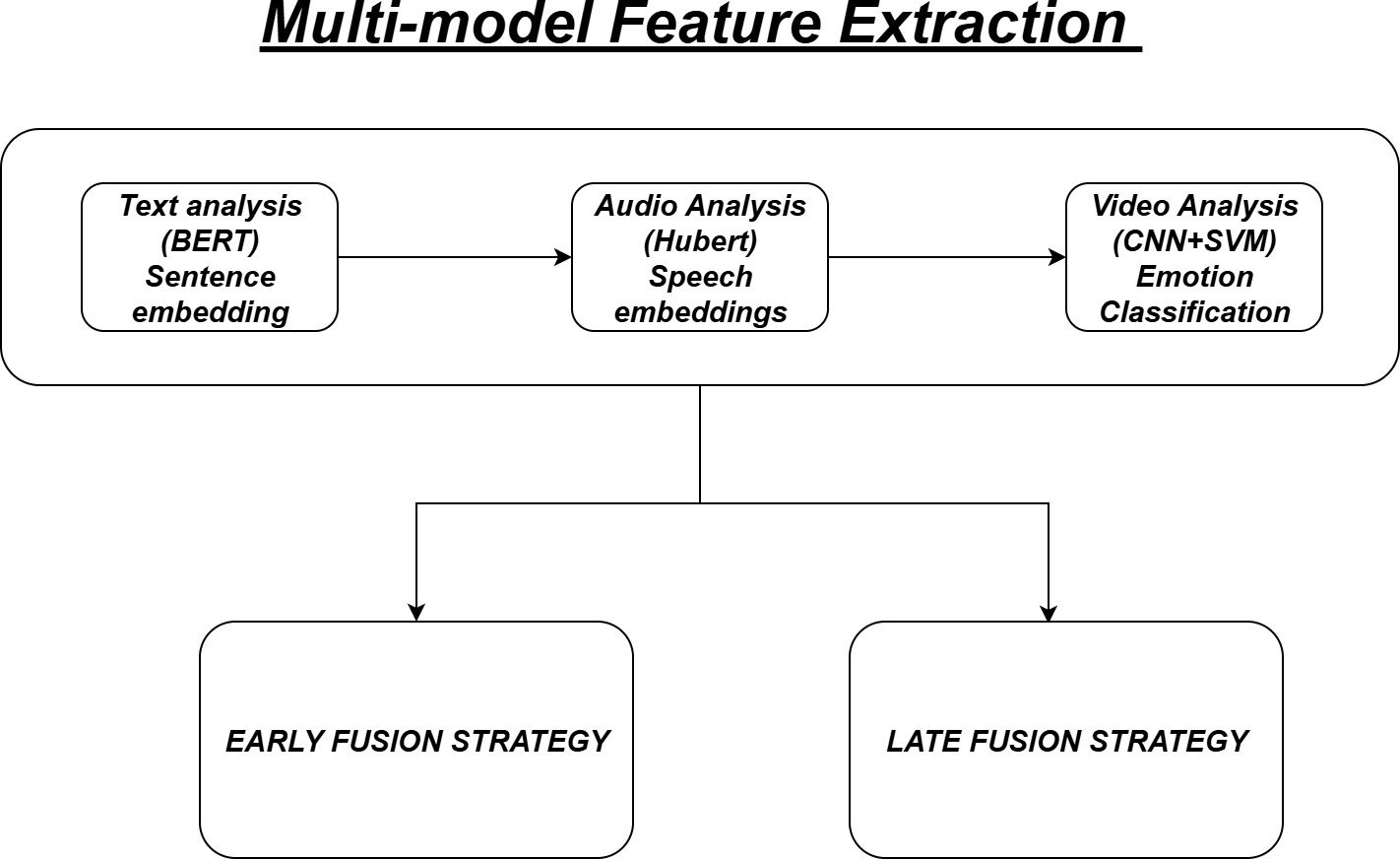
Multi-model Fusion
To increase and maximize the detection accuracy, two fusion strategies are implemented, such as:
Early fusion
In early fusion, the Text, audio, and video embeddings are added to a single feature vector in which is classified using a feedforward neural network.
Late fusion
In the late fusion, each modality is classified individually, which is done by the learning approaches that predict using the weighted majority voting technique.
Classification Model
Here, a multi-model framework has been trained and used to find the differ- ences between the original and manipulated interviews. to find the difference between the actual and false cases, the classification model is been added with cross-entropy loss and fine-tuned balanced data sampling procedures. A parallel emotion consistency model is used to verify the face expressions and vocal tones with the content of the sample in order to determine if any altered content is present there [4].
Output and Evaluation
The Model produces the fake interview probability score after analyzing each sample. Along with the probability score, a structured report has been generated with the details of emotion mismatch accuracy and audio-text synchronization results. The evaluation metrics, such as Accuracy, precision, recall, and F1- score, have been used to provide the results [1] as shown in Table 1.
Table 1: Multi-model Framework Components and Technologies
Component | Modality | Method | Purpose |
Text Analysis | Textual | BERT | Semantic Understanding |
Speech Processing | Audio | Hubert | Voice Authenticity |
Visual Analysis | Video | CNN+SVM | Facial Verification |
Emotion Tracking | Multi-modal | SVM/CNN | Expression Consistency |
Early Fusion | Combined | FFNN | Feature Integration |
Late Fusion | Individual | Weighted majority voting | Ensemble decision |
Conclusion
In this article, we have gone through a multi-model framework, which will be used to check the text, audio, and video signals to detect the fabricated celebrity interviews. The method shows good reliability compared with other methods, which contain the emotional consistency verification, and audio-text synchronization. This method offers a way to protect media by the lessons from the earlier work on political speech verification and HR chatbot-based deception detection. The future considerations will be focused on improving the ability of the model to identify fake celebrities in online environments.
References
- Diaa Salama AbdElminaam, Noha ElMasry, Youssef Talaat, Mohamed Adel, Ahmed Hisham, Kareem Atef, Abdelrahman Mohamed, and Mohamed Akram. Hr-chat bot: Designing and building effective interview chat-bots for fake cv detection. In 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), pages 403–408. IEEE, 2021.
- Elisabetta Ferrari. Sincerely fake: Exploring user-generated political fakes and networked publics. Social Media+ Society, 6(4):2056305120963824, 2020.
- Petar Ivanov, Ivan Koychev, Momchil Hardalov, and Preslav Nakov. De- tecting check-worthy claims in political debates, speeches, and interviews using audio data. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12011–12015. IEEE, 2024.
- John Twomey, Sarah Foley, Sarah Robinson, Michael Quayle, Matthew Pe- ter Aylett, Conor Linehan, and Gillian Murphy. ” what do you expect? you’re part of the internet”: Analyzing celebrities’ experiences as usees of deepfake technology. arXiv preprint arXiv:2507.13065, 2025.
- Mika Westerlund. The emergence of deepfake technology: A review. Tech- nology innovation management review, 9(11), 2019.
- Agrawal, D. P., Gupta, B. B., Yamaguchi, S., & Psannis, K. E. (2018). Recent Advances in Mobile Cloud Computing. Wireless Communications and Mobile Computing, 2018.
- Goyal, S., Kumar, S., Singh, S. K., Sarin, S., Priyanshu, Gupta, B. B., … & Colace, F. (2024). Synergistic application of neuro-fuzzy mechanisms in advanced neural networks for real-time stream data flux mitigation. Soft Computing, 28(20), 12425-12437.
- Panigrahi, R., Bele, N., Panigrahi, P. K., & Gupta, B. B. (2024). Features level sentiment mining in enterprise systems from informal text corpus using machine learning techniques. Enterprise Information Systems, 18(5), 2328186.
- Driessens, O. (2015). Expanding celebrity studies’ research agenda: theoretical opportunities and methodological challenges in interviewing celebrities. Celebrity studies, 6(2), 192-205.
- Ruchatz, J. (2014). Interview-Authentizität für die literarische Celebrity: Das Autoreninterview in der Gattungsgeschichte des Interviews. In Echt inszeniert (pp. 45-61). Brill Fink.
- RUCHATZ, J. Interview-Authentizität für die literarische Celebrity.
Cite As
Kalyan C S N (2025) Fake Celebrity Interviews: Fabricated Fame and Viral Deception, Insights2Techinfo, pp.1