By: C S Nakul Kalyan, CCRI, Asia University, Taiwan
Abstract
We can notice that an enormous range of video content is being shared on the internet every day, where techniques such as Deepfake video Re-enactment have been raised. A full-body re-enactment involves altering or mimicking the entire body movement of a person using neural networks, which is rapidly evolving in deepfake technology. These methods can be applied in education, virtual reality, and entertainment purposes, but on the other hand, they have a serious risk when these technologies are misused. In this article, we can explore the current full-body re-enactment techniques driven by deep learning, which particularly focuses on the neural network architecture so that it can enable the photo- realistic control over human movements. Here we can see a learning based approach that contains a multi-frame network in which is used to detect the re-enactment-based manipulations under different compression levels. Here we will know the reenactment generation and detection methods to maintain the originality in digital media.
Keywords
Full-Body Reenactment, photo-realistic Synthesis, Deep Learning, neural net- works, Deepfake Technology
Introduction
The advancement of Deep learning has transformed multimedia synthesis, in which it can be used to generate manipulated media known as Deepfakes [2]. The early deepfake research focused on the facial re-enactment [4], where due to the advancements of the technology, the manipulation capabilities has been expanded to the full human body, which is known as full-body re-enactment [1]. Full-body re-enactment will animate a target person will mimicking the body movements of the target, which is done by a single image and a video source of the target [3]. These re-enactment systems use neural networks, including human parsing, face embedding etc, to get high quality video outputs [2].
These technologies produce good opportunities in entertainment, virtual re- ality, and content creation, were they also raise a serious concern about the ability to make alterations of a person’s identity and actions, which leads to misuse of the visual evidence in journalism, criminal justice, and public safety [5]. To overcome this forgery, the study has begun to generate new datasets and create new detection algorithms which is specifically for full-body motion deepfakes. In this article, we will focus on the techniques, challenges, and im- plementations of the full-body re-enactment.
Proposed Methodology
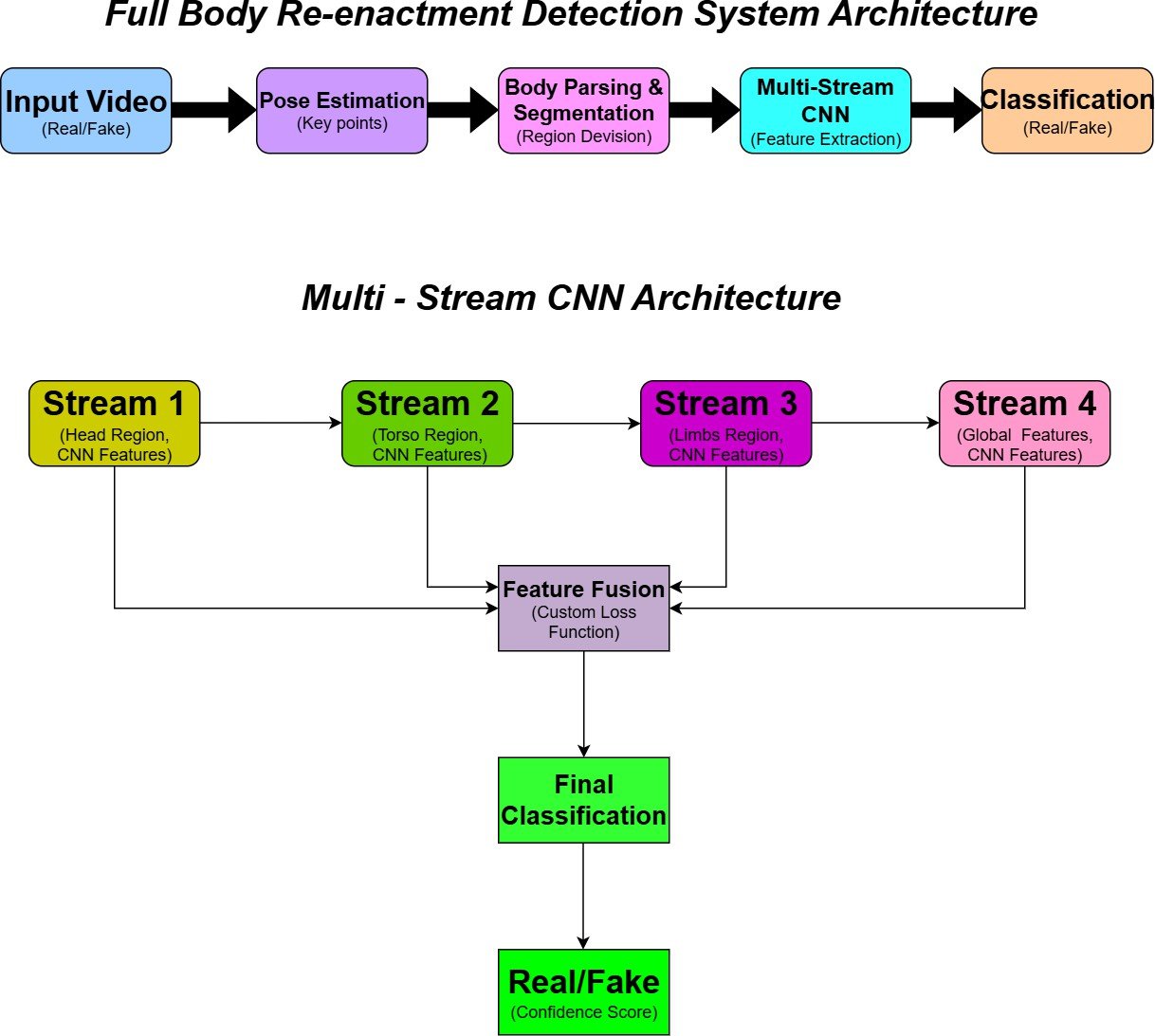
This methodology gives insights into the detection of full-body re-enactment deepfakes using deep learning algorithms, where the methodology is divided into two different components, which is 1) generating deepfakes with re-enacting techniques [2] and 2) deepfake detection using a neural network [1] as shown in (Figure 1).
Re-enactment-based Deepfake Generation
The generation of full-body Re-enactment is done by transferring the patterns of the movements from a video source into a Target person, where it is represented by a static or a small video [3]. The process involves several modules such as:
Pose estimation
In this module, the full-body pose Key Points were extracted using the pose detection models from the source video [2]. These key points include joint locations such as arms, legs, and head, which are used to replicate the movement [3].
Parsing and segmentation
Here the human body parsing techniques are implemented to divide the human body into meaningful parts like head, limbs, etc., to start the manipulation process [1].
Motion Transfer and Synthesis
By utilizing the neural rendering techniques, the extracted movement is applied to the parsed regions of the target image [3].
Visual Realism
Here the process of combining the face embeddings, body structure, and texture mapping is done to achieve the Photo-realistic quality [2]. The advanced gen- erators make sure that the movements which is re-enacted will appear natural and consistent with the background [3].
Re-enactment-based Deepfake Detection
A detection framework based on Deep learning has been developed to counter the spread of such manipulations [1]. This model is mainly built to focus on the visual and structural artifacts that are introduced during the full-body re- enactment [4]. This process involves different ways to detect deepfakes, such as:
Multi-stream Network architecture
The proposed detection model uses a Multi-stream -Convolution neural net- work, where each stream will process the different aspects of the manipulated video. This network architecture helps in detecting inconsistencies such as the unnatural limb movements, distorted joints, or bending errors.
Learning Regional Artifacts
Each regional stream is trained to focus on the different spatial patterns or specific abnormality across the body parts, where this network learns to differ- entiate between real and re-enacted movements [1].
Custom Loss function
It is a novel less function which is designed to balance the learning across the different streams and makes sure that no specific region dominates the training [1].
Compression Robustness
Here the model is evaluated under 3 levels of compression which is (none, easy and hard) where it is used to test its resilience [1]. The real world deepfakes are often shared in compressed formats in which the robustness which is produced under these conditions is critical.
Dataset Utilization
The dataset which is publicly available like FaceForencis is used to train and validate the model [4], where this dataset contains variety of manipulated videos in which the videos which are generated through re-enactment is also included.
Performance and Evaluation
The accuracy achieved by the proposed system in classifying re-enactment videos are: 99.6 percent for uncompressed videos 99.10 percent for easy compression 91.20 percent for hard compression as shown in (Table 1).
Table 1: Detection accuracy under different compression levels
COMPRESSION LEVEL | ACCURACY PERCENTAGE | DESCRIPTION |
None (Uncompressed) | 99.6 | Original video quality |
Easy Compression | 99.1 | Moderate Compression (Social media) |
Hard Compression | 91.2 | Heavy Compression (messaging apps) |
Conclusion
Here we have seen about the advantages and challenges about the full-body re-enactment which is done using neural networks, which can generate and de- tect the human movement manipulations. the highlight of our findings are high visual realism and movement fidelity and also ensuring the inclusive by accom- modate diverse body types, genders, and age groups and also we have analyzed the advanced animation methods such as human appearances and movements in a more detailed manner where it result in visual quality and it detects the
realistic motion replication. on the detection part we have reviewed both deep learning based and feature based approaches which are used to identify the deepfake videos. the CNN based detectors are good in quality and data rich environments, where the handcraft method such as LDP-TOP offers robustness in low data and compressed data scenarios. these approaches can be used for a hybrid detection strategy which could perform in various operating conditions. as the full body re-enactment gets more complex, the upcoming studies should focus on the methods to overcome adversarial attacks where the detection mod- els can handle a wide range of real-world deepfakes.
References
- Omran Alamayreh, Carmelo Fascella, Sara Mandelli, Benedetta Tondi, Paolo Bestagini, and Mauro Barni. Just dance: detection of human body reenactment fake videos. EURASIP Journal on Image and Video Processing, 2024(1):21, 2024.
- Ramamurthy Dhanyalakshmi, Claudiu-Ionut Popirlan, and Duraisamy Jude Hemanth. A survey on deep learning based reenactment methods for deep- fake applications. IET Image Processing, 18(14):4433–4460, 2024.
- Oran Gafni, Oron Ashual, and Lior Wolf. Single-shot freestyle dance reen- actment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 882–891, 2021.
- Prabhat Kumar, Mayank Vatsa, and Richa Singh. Detecting face2face facial reenactment in videos. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2589–2597, 2020.
- Laetitia A Renier, Kumar Shubham, Rahil Satyanarayan Vijay, Swasti Shreya Mishra, Emmanuelle P Kleinlogel, Dinesh Babu Jayagopi, and Marianne Schmid Mast. A deepfake-based study on facial expressive- ness and social outcomes. Scientific Reports, 14(1):3642, 2024.
- Gaurav, A., Gupta, B. B., & Chui, K. T. (2022). Edge computing-based DDoS attack detection for intelligent transportation systems. In Cyber Security, Privacy and Networking: Proceedings of ICSPN 2021 (pp. 175-184). Singapore: Springer Nature Singapore.
- Sai, K. M., Gupta, B. B., Hsu, C. H., & Peraković, D. (2021, December). Lightweight Intrusion Detection System In IoT Networks Using Raspberry pi 3b+. In SysCom (pp. 43-51).
- Keesari, T., Goyal, M. K., Gupta, B., Kumar, N., Roy, A., Sinha, U. K., … & Goyal, R. K. (2021). Big data and environmental sustainability based integrated framework for isotope hydrology applications in India. Environmental Technology & Innovation, 24, 101889.
- Gupta, B. B., & Gupta, D. (Eds.). (2020). Handbook of Research on Multimedia Cyber Security. IGI Global.
- Ivanenko, Y. P., Poppele, R. E., & Lacquaniti, F. (2009). Distributed neural networks for controlling human locomotion: lessons from normal and SCI subjects. Brain research bulletin, 78(1), 13-21.
- Bataineh, M., Marler, T., Abdel-Malek, K., & Arora, J. (2016). Neural network for dynamic human motion prediction. Expert Systems with Applications, 48, 26-34.
Cite As
Kalyan C S N (2025) Full Body Re-enactment: Controlling Human Motion with Neural Networks, Insights2Techinfo, pp.1