By: Rekarius, Asia University
Abstract
Phishing is a form of cyberattack aimed at gaining access to a victim’s personal information by employing deception and disguising techniques. Various efforts and detection techniques have been proposed, traditional approaches typically rely on machine learning models combined with handcrafted, specialized feature engineering. More recent efforts have shifted toward fully automated, featureless strategies using deep learning in an end-to-end manner. In this study, we conducted a review of phishing detection methodologies employing state-of-the-art transformer-based approaches, specifically multimodal BERT integrated with external features and BERT-PhishFinder utilizing ensemble pooling.
Keywords: Phishing Detection, Transformer-Based
Introduction
phishing refers to a set of cyberattacks where deception and disguising techniques are employed by an attacker to gain access to the victim’s sensitive information on the Internet [4]. Phishing attacks may occur on any platform that enables communication or the exchange of links and files, such as email, SMS, fraudulent websites, and other similar channels. According to the latest annual report from the FBI’s Inter- net Crime Complaint Center (IC3), phishing/spoofing ranked as the top cybercrime type in 2024 by number of complaints, accounting for 22.5% of 859,532 com- plaints and resulting in economic losses of $70,013,036 [2]. Various techniques are employed to enhance the performance of classification for phishing detection. the short-lived and ever- changing nature of phishing websites makes it difficult to establish widely accepted benchmark datasets for fair evaluation across different methods. The majority of existing approaches collect their own datasets from various sources within specific collection windows, resulting in results that are often dataset-dependent and far from generalizable, not to mention explore phishing new behaviors [3]. To address these gaps, several studies have proposed Transformer-based approaches, such as fine-tuned BERT-based multimodal approach and the BERT-PhishFinder model, which are reviewed in this short article.
Method
Fine-tuned BERT multimodal approach
The approach employed in this [5] study is described in this section.
Dataset
The effectiveness of phishing detection systems is highly influenced by the quality and relevance of the datasets used for model training and evaluation. However, due to the short-lived nature of phishing websites, the availability of benchmark datasets remains very limited. Many recent studies attempt to maintain a certain level of transparency by continuously collecting datasets from specific sources within a defined period for experimental purposes, as well as reporting dataset statistics and feature details. Nevertheless, limited access to raw data often hinders replication and restricts further exploration. To address these limitations, this study combines publicly available datasets with a self-compiled dataset to support experimental analysis.
-
- Open-Source Dataset
The open-source datasets that were collected, along with their details, are presented in Table 1.
Table 1: Datasets
Dataset Name Sample Size Sample Source Domain Diversity
Accuracy
Feature ExtractiboynURL
Total | Phishing | Legitimate | Phishing | Legitimate | Phishing | Legitimate length | |||
Vrbanek2020 full | Manually | ||||||||
(without URLs) | 88,647 | 30,647 | 58,000 | PhishTank | Alexa | N/A | N/A | Extracted: 111 | 86.13% |
Hannousse2021 | 11,430 | 5,715 | 5,715 | PhishTank and OpenPhish | Alexa and Yandex | 47.0% | 69.5% | Manually Extracted: 87 | 60.59% |
GramBedding2022 | 800,000 | 400,000 | 400,000 | PhishTank and OpenPhish | Alexa and Majestic Million | 29.7% | 69.9% | N/A | 65.15% |
PhishTank, | |||||||||
OpenPhish and | Manually | ||||||||
PhishSLL2024 | 235,795 | 100,945 | 134,850 | MalwareWorld | DomCop | 43.1% | 98.0% | Extracted: 49 | 82.54% |
TAMAL2024 (without URLs) | 247,950 | 119,409 | 128,541 | PhishStorm and OpenPhish | PhishStorm and DomCop | N/A | N/A | OFVA Algorithm: 41 | 70.38% |
Manually | |||||||||
PhishMail | 8,937 | 8,937 | N/A | Phishing Email | N/A | 38.1% | N/A | Extracted: 11 | N/A |
-
- PhishMail
PhishMail is a dataset compiled from malicious emails collected between January 2024 and April 2025. The dataset contains 8,937 phishing URL samples, most of which are written in Japanese and im- personate popular brands such as Amazon, PayPay, Yamato Transport, and various banks. A distinctive characteristic of this dataset is the use of Unicode homographs for domain obfuscation.
Proposed Fine-Tuned BERT Model
Fine-tuned BERT (Bidirectional Encoder Representations from Transformers) approach for phishing URLs detection, where a general subword-level token-pattern, WordPiece Tokenization is employed. It is designed to efficiently handle large vocabularies and OOV words by breaking down previously unseen words into smaller, more manageable known subword units. For instance, “unhappiness” could be split into “un”, “##happiness”, where “##” indicates that the subword is a continuation of a word, helping the model efficiently handle a wide range of vocabulary. In addition to token optimization, their approach adopts the concept of fine-tuning, where a model is first pre-trained on extensive unsupervised corpora and then adapted to specific NLP tasks using a limited amount of annotated data.
In their case, they fine-tuned a 12-layer Base BERT model (another Large BERT model has 24 layers) with labeled phishing URLs to directly process URL strings. they add one feed-forward neural network layer with SoftMax activation function to give the prediction output. The model was fine-tuned using a learning rate of 1e-5, batch size of 16, and a maximum sequence length of 200. Fine-tuning was conducted for 3 epochs with the AdamW optimizer and cross-entropy loss. All layers of the model were updated during training. Furthermore, to enhance the interpretability of the prediction results, we utilize explainable AI tools such as the Captum and LIME to elucidate the phishing predictions made by our model. This model also serves as the primary NLP component in our multimodal fusion frame- work.
Proposed Multimodal Approach
Although the URL itself can reveal potential phishing characteristics, external features such as WHOIS records and DNS responses provide additional contextual information beyond the URL string, thereby enhancing detection robustness. The authors propose a multimodal approach that integrates a fine- tuned BERT model as the primary component for processing raw URL strings, complemented by flexible external features. The outputs from both branches are subsequently combined through decision-level fusion to generate the final prediction.
-
- External Features
External features such as WHOIS and DNS records provide additional context for phishing detection, including information on domain creation and expiration dates, registrar details, IP addresses, MX servers, and DNSSEC configurations. As public Internet resources, this information is openly accessible through standard protocols at no cost. In this study, a set of 11 external features was constructed,
consisting of three WHOIS features, seven DNS features, and the count of non-ASCII characters in the URL. The analysis indicates that features related to domain age and the number of servers (NS/MX) play the most significant role in distinguishing legitimate domains from phishing domains.
Table 2: Feature importance ranking of external features on Hannousse2021 and Balanced PhishMail datasets.
# | Hannousse2021 | Balanced PhishMail | ||
Feature Name | Cumulative Accuracy | Feature Name | Cumulative Accuracy | |
1 | a days | 80.59 | a days | 87.19 |
2 | qty mx server | 82.17 | non ascii count | 88.53 |
3 | a ttl | 82.95 | qty nameserver | 94.35 |
4 | mx ttl | 83.74 | days to e | 95.36 |
5 | days to e | 83.96 | a ttl | 94.52 |
6 | ipv4 count | 84.62 | qty mx server | 96.42 |
7 | qty nameserver | 85.23 | ipv4 count | 95.69 |
8 | ipv6 count | 84.27 | mx ttl | 94.35 |
9 | aaaa ttl | 84.97 | dnssec signed | 95.52 |
10 | dnssec signed | 85.23 | ipv6 count | 96.03 |
11 | non ascii count | 85.49 | aaaa ttl | 94.85 |
Table 2 shows that temporal features (domain activation and expiration), as well as the number of name servers and MX servers, are the most important indicators for distinguishing phishing domains from legitimate ones. In the Balanced PhishMail dataset, the non-ASCII character count also appears highly discriminative, highlighting the growing trend of Unicode-based obfuscation in phishing URLs. Meanwhile, features related to IPv6 and DNSSEC exhibit relatively limited impact due to their sparsity.
-
- Fusion Strategy
Decision-level multimodal fusion treats each model as an independent expert and leverages their outputs rather than their internal representations, offering greater flexibility and making it well-suited for combining heterogeneous models. Mainstream implementations of decision-level fusion include majority voting and the use of a trainable meta-classifier that learns to integrate the outputs from each model, which is called stacking. Voting can be categorized into hard voting and soft voting, where the former selects the majority class and the latter averages prediction probabilities. Stacking allows the use of either linear or non-linear models as meta-classifiers.
-
- Multimodal Generalization Test
The cross-dataset generalization capability of the proposed multimodal approach was validated using the PhishMail dataset and the specially constructed Balanced PhishMail dataset. For the two balanced small-scale datasets, namely Hannousse2021 and Balanced PhishMail, two sets of prediction probabilities were obtained from the URL string and the external features, each generated by an independent model. Subsequently, 10-fold cross-validation was performed to compare the effectiveness of Random Forest (RF) stacking and Logistic Regression (LR) stacking, with the superior strategy selected as the meta-classifier and evaluated on the test set.
BERT-PhishFinder
The model employed in this [1] study is described in this section. ”BERT- PhishFinder” is made up three important components, the initial tokenization of input URLs, the subsequent training process entailing feature extraction, and the ingenious application of the ”BERT-PhishFinder” model to automatically classify unknown webpage URLs.
- Input Tokenization and Encoding
For tokenization, they employ the DistilBertTokenizer to split the input URL into individual tokens such as words or sub-words, following language-specific rules and conventions. This tolprocess generates a vocabulary of unique tokens that can be encoded into numerical representations. Specifically, we utilize the ”distilbert-base-uncased” variant, which is a smaller and faster version of DistilBERT trained on uncased text, making it suitable for various natural language processing tasks while maintaining good performance. For example, to tokenize the input URL ”https://www.example.com” in our model, it would typically be divided into the following tokens: [”https”, ”:”, ”/”, ”/”, ”www”, ”.”, ”example”, ”.”, ”com”]. DistilBERT’s tokenizer would handle the tokenization process, splitting the URL into separate tokens based on language-specific rules and conventions.
Regarding segmentation, as URLs do not consist of multiple sentences or segments, segment embed- ding are not applicable in our model. However, we still include the ”CLS” and ”SEP” tokens to mark the beginning and end of the input sequence. The ”CLS” token is useful for tasks like text classifi- cation, as its corresponding hidden state can be used for making predictions. The ”SEP” token helps in delineating boundaries between segments or sentences, although not applicable in URL text. To capture the sequential nature of URL text and understand dependencies between tokens, we leverage position embedding. These embedding encode the relative or absolute position of each token within the input sequence.
- Feature Extraction
Let X represent the input URL sequence with individual tokens denoted as xi where i ranges from 1 to N, the sequence length. DistilBERT integrates task- specific layers to customize the model for downstream tasks. Its transformer layers yield sequence outputs O = [o1, o2, . . ., oN ] with oi representing the contextualized representation for token xi. To obtain the final output, we follow a sequential approach, augmenting the sequence output from the transformer layers:
A = [a1, a2, . . ., aN ], where each ai is the result of applying spa- tial dropout to oi, enhancing robustness through regularization.
The spatial dropout layer introduces regularization by randomly deactivating channels in oi, promoting feature generalization. Additionally, they employ a combination of global average pooling Pavg and global max pooling Pmax to capture diverse aspects of the input sequence, incorporating both overall con- text and salient features, yielding concatenated vectors C =
[c1, c2, . . ., cN ], where ci is the concatenation of Pavg and Pmax for ai. It is important to note that while our approach builds upon the capabilities of DistilBERT, the specific adaptations and enhancements implemented in our model, ”BERT-PhishFinder”, contribute to its superior performance in classifying URLs as legitimate or potentially phishing.
- Phishing URL Detection
The feature vectors C = [c1, c2, . . ., cN ] previously obtained during the feature extraction phase are subsequently input into eight parallel dense layers, denoted as D = [d1, d2, . . ., dN ] each consisting of 64 units and employing ReLU activation. Following each dense layer di, an additional dense layer di is introduced, with a single unit and sigmoid activation, enhancing discriminative capability. The outputs F = [f1, f2, . . ., fN ] from these final dense layers are combined using average pooling denoted as Pfinal, which results in a single representative output:
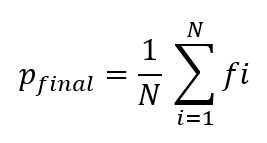
The aggregated output through Pfinal represents the consensus of individual dense layer outputs and serves as the classification decision for binary classification in phishing URL detection. This meticulous design aims to introduce variability and lever- age ensemble learning principles. Each dense layer di captures distinct patterns, and their outputs fi collectively enhance the overall model performance.
- Model Training
They used the Keras framework with a Tensorflow backend. The training procedure for ”BERT- PhishFinder” follows a systematic and well-defined process. It commences with meticulous data prepa- ration, which involves breaking down URLs into smaller units, known as tokens, and encoding them along with their corresponding labels. Utilizing the principles of transfer learning, we employ a pre-existing language model to distill meaningful representations from URLs. The model is initialized with pre-trained DistilBERT weights and then fine- tuned across multiple epochs, aided by the binary crossentropy loss function and the backpropagation technique. they incorporate regularization mechanism such as dropout and weight decay to sefeguard against overfitting. Rigorous validation ensures the meticulous tuning of model parameters, and a set of evaluation metrics comprehensively gauges the model’s effectiveness on previously unseen data. This training process hinges upon precise data preparation, strategic fine-tuning, and deliberate hyperparameter adjustments to achieve dependable and accurate predictions.
- Datasets Description
They have used five publicly available real-world URL datasets and compiled the relevant information regarding the sources and statistics of these datasets in Table 3.

Figure 1: Overview of the BERT-PhishFinder model architecture, illustrating its key components, including tokenization, embedding layers, transformer blocks, and classification layers used for phishing URL detection.
Table 3: Summary of phishing and legitimate URL datasets
Dataset | URL label | Instances | Total Instances | Sources |
DS1 | Phishing | 37,175 | 73,575 | PhishTank, Yandex |
Legitimate | 36,400 | |||
DS2 | Phishing | 40,668 | 126,077 | PhishTank, Alexa, and Common-crawl |
Legitimate | 85,409 | |||
DS3 | Phishing | 40,668 | 82,888 | PhishTank, Common-crawl |
Legitimate | 42,220 | |||
DS4 | Phishing | 40,668 | 83,857 | PhishTank and Alexa |
Legitimate | 43,189 | |||
DS5 | Phishing | 156,422 | 549,346 | – |
Legitimate | 392,924 |
Conclusion
In the comparative evaluation of phishing detection existing models. “BERT-PhishFinder” using a unified 5-fold cross-validation approach across five benchmark datasets. BERT-PhishFinder consistently outperformed the other models across the key evaluation metrics—accuracy, precision, recall, and F1- score—demonstrating substantial improvements. The fine-tuned BERT multimodal approach yields promising results; however, it faces several challenges, such as the lack of real-time evaluation, frequent unavailability of external data, and the high cost or latency of API queries.
References
- Ali Aljofey, Saifullahi Aminu Bello, Jian Lu, and Chen Xu. Bert-phishfinder: A robust model for accurate phishing url detection with optimized distilbert. IEEE Transactions on Dependable and Secure Computing, 2025.
- Internet Crime Complaint Center (IC3). Internet crime complaint center (ic3), 2025. Accessed: May 2025.
- Bhawna Sharma and Parvinder Singh. An improved anti-phishing model utilizing tf-idf and adaboost. Concurrency and Computation: Practice and Experience, 34(26):e7287, 2022.
- Gaurav Varshney, Rahul Kumawat, Vijay Varadharajan, Uday Tupakula, and Chandranshu Gupta. Anti-phishing: A comprehensive perspective. Expert Systems with Applications, 238:122199, 2024.
- Yi Wei, Masaya Nakayama, and Yuji Sekiya. Enhancing generalization in phishing url detection via a fine-tuned bert-based multimodal approach. IEEE Access, (99):1–1, 2025.
- Hoseinpoor, S., Chamani, J., Saberi, M., Iranshahi, M., Amiri-Tehranizadeh, Z., & Shakour, N. (2024). PPARG modulation by bioactive compounds from Salvia officinalis and Glycyrrhiza glabra in type 2 diabetes management: A in silico study. Innovation and Emerging Technologies, 11, 2450003.
- Jin, B., & Xu, X. (2024). Machine learning brent crude oil price forecasts. Innovation and Emerging Technologies, 11, 2450013.
- Liu, L., Hasikin, K., Jiang, Y., Xia, K., & Lai, K. W. (2025). BrainAdaptNet: A few-shot learning model for brain tumor segmentation in low-quality MRI. Innovation and Emerging Technologies, 12, 2550023.
- Ma, Y., Li, X., Hu, S., Liu, S., & Cheong, K. H. (2025). Trustworthy AI in education: Framework, cases, and governance strategies. Innovation and Emerging Technologies, 12, 2550026.
Cite As
Rekarius (2025) Improving Generalization in Phishing URL Detection: A Review of Multimodal BERT and BERT-PhishFinder Models, Insights2Techinfo, pp.1