By: C S Nakul Kalyan; CCRI, Asia University Taiwan
Abstract
A powerful combination of AI-driven Voice Cloning and video manipulation, lip sync Deepfakes allows for the production of unbelievable life-like videos in which people seem to say things that they never said. These manipulations are hard to find because, they are created by just changing only the mouth and jaw areas to match the modified sounds, where such technologies present a high risk of mis- using data. Detection methods that finds the time difference between audio and video to overcome this, where one approach transcribes Speech using lip reading and audio-to-text Conversion and compares the output to find the forgery, and the other method focuses on finding the Phoneme-viseme mismatches where the spoken sound does not match the mouth shape. These techniques can find the deepfake content even when small alterations have been made. This multimodel approach uses combined techniques which it will detect the lip sync deepfakes that are growing in misuse of the synthetic Data.
Key Words
Lip Sync Deepfakes, Voice Cloning, Video Manipulation, Phoneme-viseme Mis- match.
Introduction
The Modern Technology, like computer vision, graphics, and machine learning, has enabled the possibilities of creating deepfakes in which people seems to do things that they never did. The lip sync deepfakes Modifies only the mouth and jaw moments where it aligns with the manipulated audio, where the artificial voices has been cloned with advanced text to speech (TTS) and Voice conversion (VC) Systems.
Even though the deepfakes have been used for Entertainment Purposes, they cause a serious threat when they are misused, like fraud or political manipulation
and which it give a big impact [4], as using deepfakes in political management leads to changing the whole public opinion on them [3]. The traditional detection methods struggle with the lip-sync Deepfakes due to the small modifications.
To overcome these issues, a recent study highlights the interaction between phonemes (sounds) and visemes (mouth shape) [1] , as mentioned in (Figure 1)
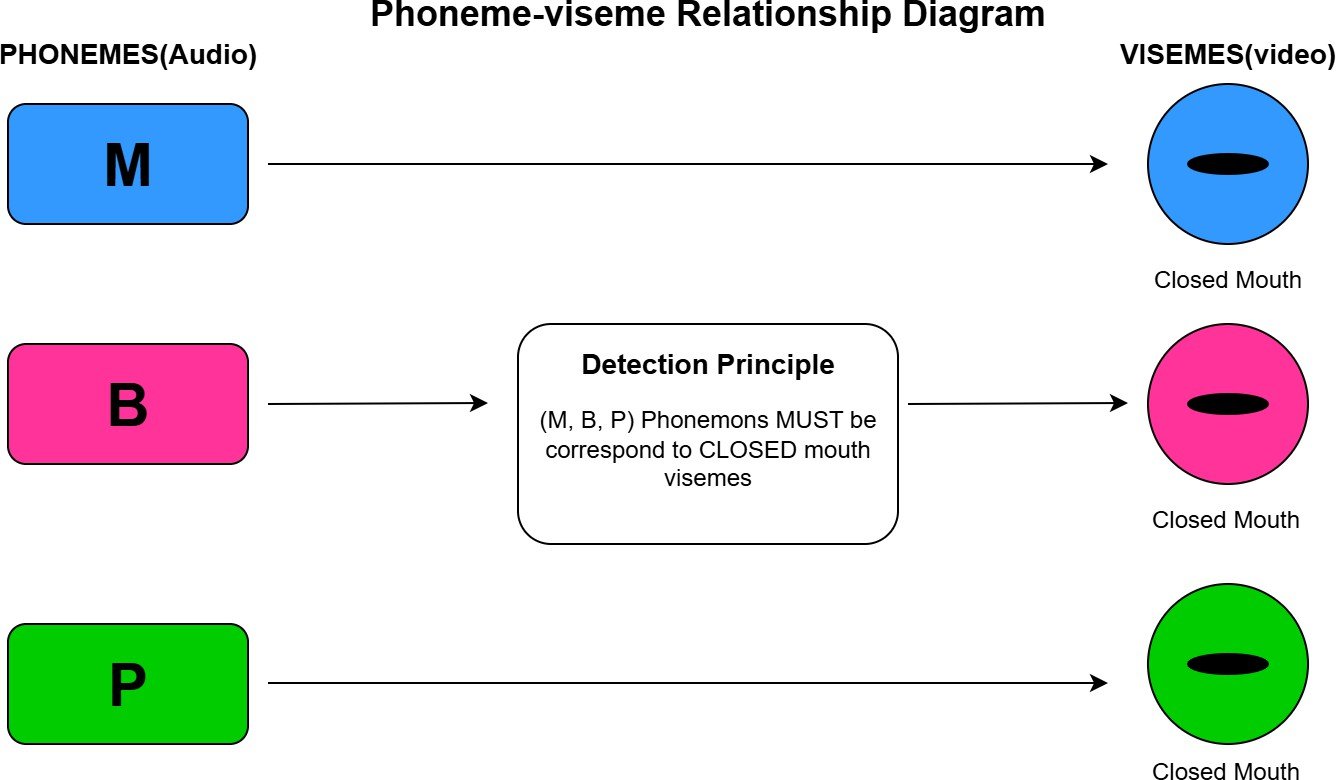
and other technique like TTS to voice conversion can serve as cues for de- tection. The detection framework have been proposed to not only analyse the audio and video separately, but they introduced an ”sync-stream” which finds the mismatches between them and increases the detection accuracy [5]. In this article, we can get to know about the lip-sync deepfakes [2], their challenges, and the proposed methods to overcome those challenges.
Methodology
This Method detects lip-sync Deepfakes by testing the Visuals of the mouth pronunciation of phonemes(M, B, P), which require a completely closed mouth [1], and the methodology will perform the following steps to detect the Deepfakes as mentioned as (Figure 2).
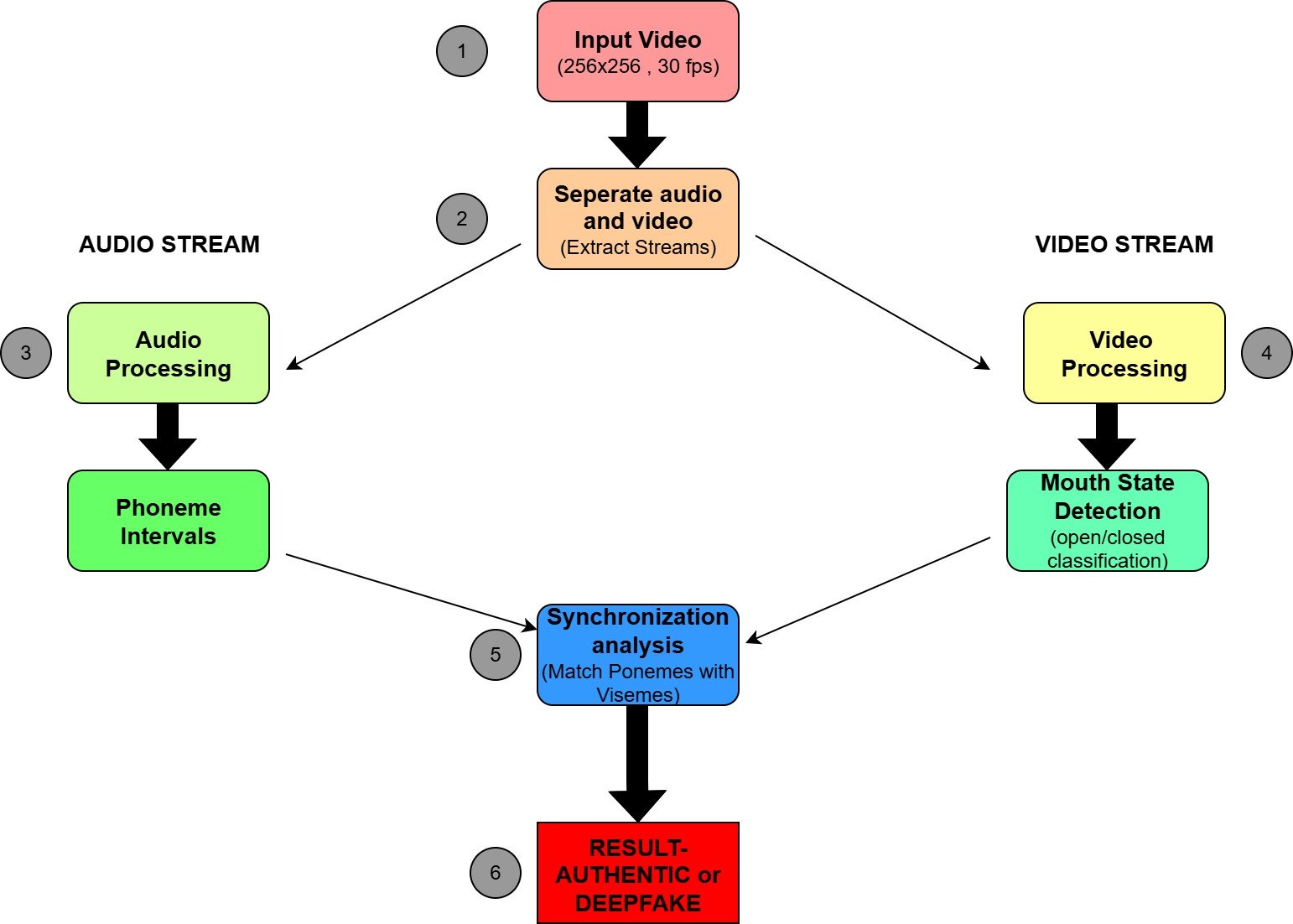
Dataset Preparation
The video categories that are used here are Audio-to-Video(A2V), Short Text- to-Video(T2V-S), Long Text-to-Video(T2V-L), along with the real-world Deep- fake data, which are from YouTube and Instagram, where each Video is aligned and Standardized to 256×256 pixels at 30 FPS.
Phoneme Extraction and alignment
Here the audio files is generated through Google’s Speech-to-Text API, where the Phoneme alignment is done by using Penn Phonetics Lab Forced Aligner(P2FA) [1], which focuses on finding the Time intervals for the phonemes.
Viseme Detection approaches
This detection approach is used to Determine if the mouth is closed during the (M, B, P) phoneme intervals [1], where the methods to determine are as follows:
Manual Inspection
This method is usually performed by humans, where they will check whether at least one frame is a closed mouth during the (M, B, P) intervals [1].
Profile Based Analysis
The Grayscale vertical intensity profiles from the lip region(50×50 Pixels) will be extracted and compared with the reference of the closed-mouth using Similarity metric [1].
CNN-Based Classification
A Deep learning model is trained on over 15,000 labeled Frames, in which it is used to classify the individual frames as ”mouth open” or ”mouth closed,” and the output of the MBP segment is determined on the basis of the confidence levels of the frames [1] as mentioned in (Table 1).
Table 1: Comparison of Deepfake detection Datasets
DETECTION METHOD | INPUT REQUIREMENTS | APPLICATIONS |
Manual Inspection Profile-Based Analysis CNN-Based Classification | Video Frames Lip Region(50×50 pixels) 15,000 + Frames | High-Stake verification Balanced detection for moderate volumes Large-scale Automation Detection |
Audio-Video synchronization Check
This alignment is performed by adjusting the timing of the audio within 1 second to match the MBP phonemes with the corresponding closed-mouth Frames [2] [3], which ensures the precision of sync in the Audio and video [4].
Conclusion
We have discused a technique for detecting lip-sync deepfakes by finding mis- matches between the phonemes and visemes, which particularly focuses on the MBP phonemes that require a full-mouth closure. These conflicts often go unno- ticed in the manipulated videos in which this method makes the detection more accurate. The manual verifications can be used in the high-stakes scenario and the automated approaches will be useful for the large-scale detections. This method gives importance to the M, B, and P sounds in which it is used to im- prove the accuracy in detecting deepfakes. Though the limitations in labelled datasets produce challenges, the future developments in unsupervised learning could overcome the challenges and enhance the detection performance.
References
- Shruti Agarwal, Hany Farid, Ohad Fried, and Maneesh Agrawala. Detect- ing deep-fake videos from phoneme-viseme mismatches. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition work- shops, pages 660–661, 2020.
- Matyas Bohacek and Hany Farid. Lost in translation: Lip-sync deepfake detection from audio-video mismatch. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4315–4323, 2024.
- Muhammad Javed, Zhaohui Zhang, Fida Hussain Dahri, Asif Ali Laghari, Martin Krajˇc´ık, and Ahmad Almadhor. Audio–visual synchronization and lip movement analysis for real-time deepfake detection. International Jour- nal of Computational Intelligence Systems, 18(1):170, 2025.
- Weifeng Liu, Tianyi She, Jiawei Liu, Boheng Li, Dongyu Yao, and Run Wang. Lips are lying: Spotting the temporal inconsistency between audio and visual in lip-syncing deepfakes. Advances in Neural Information Pro- cessing Systems, 37:91131–91155, 2024.
- Yipin Zhou and Ser-Nam Lim. Joint audio-visual deepfake detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 14800–14809, 2021.
- Goyal, S., Kumar, S., Singh, S. K., Sarin, S., Priyanshu, Gupta, B. B., … & Colace, F. (2024). Synergistic application of neuro-fuzzy mechanisms in advanced neural networks for real-time stream data flux mitigation. Soft Computing, 28(20), 12425-12437.
- Gupta, B. B., Gaurav, A., Chui, K. T., & Arya, V. (2024, January). Deep learning-based facial emotion detection in the metaverse. In 2024 IEEE International Conference on Consumer Electronics (ICCE) (pp. 1-6). IEEE.
- Li, M., Ahmadiadli, Y., & Zhang, X. P. (2025). A survey on speech deepfake detection. ACM Computing Surveys, 57(7), 1-38.
- Kumar, A., Singh, D., Jain, R., Jain, D. K., Gan, C., & Zhao, X. (2025). Advances in DeepFake detection algorithms: Exploring fusion techniques in single and multi-modal approach. Information Fusion, 102993.
- Ahmed, M. M., Darwish, A., & Hassanien, A. E. (2025). Avatar facial emotion recognition based on machine learning techniques. In Human-Centered Metaverse (pp. 29-50). Morgan Kaufmann.
Cite As
Kalyan C.S.N. (2025) Lip Sync Deepfakes: Manipulating Speech Through Visual Illusion, Insights2Techinfo, pp.1