By: Rekarius, Asia University
Abstract
QR Phishing (Quishing) represents a variant of phishing attacks in which QR codes are exploited to embed malicious URLs that redirect users to fraudulent websites upon access. The rapid proliferation of QR codes across domains such as e-commerce, banking, and public services has amplified the risks associated with quishing. This paper provides a review of existing studie on detection systems for malicious URLs embedded in QR codes, with a particular focus on deep learning–based approach
KeywordsQR Phishing Detection, Quishing, Deep Learning
Introduction
The ability of QR codes to embed information that can be easily accessed through scanning with smartphones or dedicated readers makes them highly useful in facilitating various aspects of daily life. QR codes are often used for information sharing, marketing, and identification purposes [1]. The adoption of QR codes for payment systems in shopping, banking services, and social ser- vices has greatly enhanced convenience for users. However, this convenience can be considered a double-edged sword, as the use of QR codes also introduces potential cybersecurity risks, particularly phishing attacks. Cybercriminals can exploit QR codes by embedding malicious phishing URLs and distributing them across multiple platforms. Unsuspecting users may scan these codes without caution, thereby falling victim to phishing attempts. Therefore, a robust detection mechanism is required to enhance user confidence and ensure security in the use of QR codes. This paper presents a review of studies that investigate QR phishing detection using deep learning approach.
Methodology
- Lightweight DL Model
This study [2] implemented a lightweight DL model, using TensorFlow and Keras, based on a Convolutional Neural Network (CNN) architecture. This model employs multiple convolutional layers to extract features from QR code images, followed by dense layers for classification. Dropout layers with a rate of 99% were incorporated to prevent overfitting during training. The model achieved a remarkable test accuracy of 99%. This translates to a precision of 95% for cyberattack detection, signifying the model’s exceptional ability to accurately identify malicious QR codes.
-
- System Design
The framework for malicious QR code URL detection is structured into three distinct phases. The initial phase focuses on examining the URL for redirection to address the use of shortened or redirected URLs by redirecting them to the original website to facilitate evaluation through various features. The second phase performs classification based on four features. The final phase involves an evaluation based on the features.
figure 1 shows the design of the proposed system.
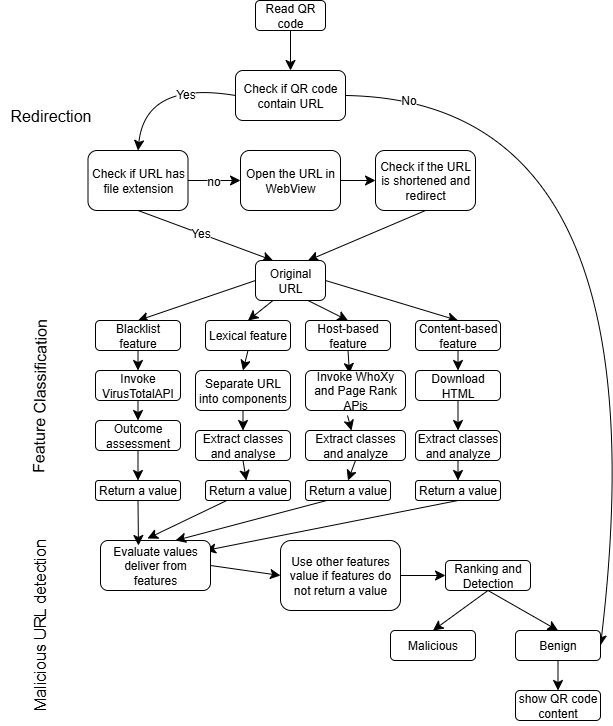
- URL Redirection
The Redirection Phase plays a crucial role in addressing obfuscation techniques, particularly the use of shortened URLs to evade detection. In this phase, the URL is redirected and processed through an algorithm specifically designed to identify obfuscated URLs. The primary objective is to evaluate the ex-tracted features once the URL has been redirected to its final destination. This approach aims to minimize the risk of misclassification resulting from features that incorrectly assess websites.
If the URL does not undergo redirection, the analysis begins by verifying whether the QR code contains textual content. In such cases, the application informs the user that the QR code is safe and displays its content. However, if the QR code contains a link, the algorithm examines whether the URL includes certain data formats or file extensions, such as IP addresses, executable files, or multimedia formats. If such elements are detected, the original URL is displayed, marking the conclusion of this phase and passing the URL to the subsequent stage.
Conversely, if the result is negative, the algorithm opens the URL within a WebView, a Chrome-based system component that enables applications to render online content on Android devices. Within the WebView, the algorithm verifies whether the URL is original or redirected. If redirected, the algorithm employs the override URL loading method by opening the original website in a second WebView, which redirects back to the first WebView until the original URL is displayed. The first WebView records the number of redirections, while the second displays the original URL. This phase ultimately restores the website to its original URL. If redirection occurs more than ten times, the final step presents the URL alongside its redirection history. At this point, the URL is ready to proceed to the next phase for feature processing.
- Feature Extraction and Classification
This phase initiates the classification and extraction of relevant information essential for effectively characterizing the URL. The classes are derived through parsing and analyzing various URL components. This study focuses solely on critical classes that contribute substantially to detecting malicious URLs. Critical classes are those that extract essential statistical information from a URL, aiding in distinguishing between malicious and benign websites. The identification of these classes is performed by the results obtained from detecting malicious URLs across various datasets. The classification phase is based on four primary features, blacklist, lexical, host-based, and content-based.
The URL from the previous phase serves as input for each feature where information is collected through API calls. URL parsing or HTML download- ing extracted information adheres to predefined values with classes categorized through numeric and binary values. Numerical values represent the class types that embed counting objects, while binary classes are defined by the presence of unique objects. This feature extraction and classification process is a crucial component of the overall framework, contributing significantly to the accurate detection of malicious URLs within the context of cyber-attacks involving QR codes.
- Detection of Malicious URLs
The malicious URL detection framework leverages the available data and their overall quantity. This framework is guided by a predefined static feature classification method as expressed in:
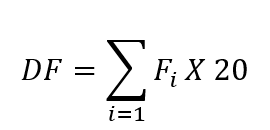
where F denotes the feature value, with i representing the number of features. The total value is then multiplied by 20 to determine the richness of each feature on a scale of 100. The resulting DF is compared against a threshold value of 200. If it surpasses this threshold, the URL is classified as malicious, otherwise, it is deemed benign. The feature evaluation method is outlined in the rule:
if any F i = -1 & other F i ≥ 3.5 or blacklist ≥ 3
Then, F is assigned the greatest feature value.
This method evaluates the values derived from features, checking if all of them contribute to the final calculation. If any feature fails to provide a value, the method employs alternative feature values based on specific conditions. is calculated using:
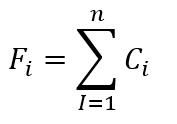
where denotes the value of the class and represents the number of the classes for a feature. Each class can assume values based on various comparisons and conditions. The predefined values are assigned within a range to conduct analyses and comparisons, yielding a conclusive result to address the drawbacks identified in existing secure QR code scanners. The feature evaluation method is applied in this phase to enhance the accuracy of malicious URL detection. This method critically evaluates the values attained during the feature classification phase. It ensures that all features, except the lexical feature that consistently returns a value, contribute to the final calculation if any feature fails to provide a value. This framework deploys alternative feature values when faced with scenarios like API failures or unexpected server downtime. This distinctive aspect involves robust calculations, allowing the framework to accurately detect malicious URLs even if certain features do not respond.
-
- Dataset
A substantial dataset was amassed, comprising 651,191 URLs with 428,103 classified as benign or safe, 96,457 as defacement URLs, 94,111 as phishing URLs, and 32,520 as malware URLs. This dataset was meticulously curated from five distinct sources: ISCX URL 2016, malware domain blacklist, Faizan git repository, phish tank, and phish storm. Given the diverse origins, URLs from various sources were compiled into separate data frames, culminating in a final merging process to retain only the URLs and their respective class types. The final dataset was separated into training (70%), validation (15%), and testing (15%) subsets. The training dataset was employed to train the classification model, the validation dataset was utilized to tune hyperparameters and choose models, and the testing dataset was engaged to perform the final evaluation.
-
- Result
Table I presents the model performance across different QR code types. It reveals high precision (0.95- 0.97) for both normal (Class 0) and phishing (Class 1) codes, indicating accurate identification.
Table 1: Classification Report
Class | Precision | Recall | F1-Score |
0 | 0.95 | 0.99 | 0.92 |
1 Phishing | 0.95 | 0.96 | 0.90 |
2 Malware | 0.97 | 0.94 | 0.94 |
Conclusion
This study aimed to address the critical issue of cyberattacks using QR codes by employing a lightweight DL model. A dataset, amassed from different sources, was augmented and used to train a lighweitght deep-learning model. The results were promising in terms of overall accuracy, especially in detecting normal instances. The proposed lightweight deep-learning model needs further refinement. To enhance its robustness to a variety of attack scenarios, hyperparameters must be optimized, different architectures must be explored, and advanced techniques must be investigated. Class imbalances may be contributing to challenges in detecting certain attack classes.
References
- Rongjun Chen, Hongxing Huang, Yongxing Yu, Jinchang Ren, Peixian Wang, Huimin Zhao, and Xu Lu. Rapid detection of multi-qr codes based on multistage stepwise discrimination and a compressed mobilenet. IEEE internet of things journal, 10(18):15966–15979, 2023.
- Mousa Sarkhi and Shailendra Mishra. Detection of qr code-based cyberat- tacks using a lightweight deep learning model. Engineering, Technology & Applied Science Research, 14(4):15209–15216, 2024.
- Lin, H., Zhang, X., Hong, Y., Zhong, J., Lin, Y., & Xu, D. (2025). Machine learning-based analysis of factors influencing hospitalization costs in thyroid cancer surgery patients. Innovation and Emerging Technologies, 12, 2550037.
- Chen, M. J., Hsu, Y. L., & Xu, J. L. (2025). Two-stage AI model for endometrial cancer staging: YOLOv4 localization and deep learning classification. Innovation and Emerging Technologies, 12, 2550034.
- Kumar, A., Dhanka, S., Singh, J., Ali Khan, A., & Maini, S. (2024). Hybrid machine learning techniques based on genetic algorithm for heart disease detection. Innovation and Emerging Technologies, 11, 2450008.
Cite As
Rekarius (2025) QR code Phishing URL Detection Based on Lightweight Deep Learning Model, Insights2Techinfo, pp.1