By: Rekarius, CCRI, Asia University, Taiwan
Abstract
Imagine receiving an email purporting to be from a particular entity, such as a bank. You are told in the email to confirm your account using a verification link they send, which takes you to a website that looks a lot like a certain bank’s website. You submit your credentials or personal information to the form they give without raising any red flags. Phishing attackers will gather the personal data you have entered and use it to get access to your account and perpetrate a number of crimes. An example of how phishing attacks might occur is this. This paper discusses real-time phishing detection using deep learning methods by web browser extension.
Keywords Real-Time Phishing Detection, Deep Learning, Web Browser Extension
Introduction
Phishing attacks are social engineering attacks that reach users by sending a fake message via social media or email [1]. Imagine getting an email purport- ing to be from a particular entity, like a bank. You are told in the email to confirm your account using a verification link they send, which takes you to a website that looks a lot to a certain bank’s website. You submit your credentials or personal information into the form they give without raising any red flags. Phishing attackers will gather the personal data you have entered and use it to get access to your account and perpetrate a number of crimes. One example of how phishing attacks might happen is this.This study discusses a real-time phishing detection strategy that combines Deep Learning (DL) models with software extensions. The objective is to clas- sify URLs as benign or harmful before users visit them.
Methodology
Paper 1
In this research [3], They developed a software extension that is installed on web devices using a deep learning model.
Proposed Algorithm
The CNN model was selected as the primary model due to its superior accuracy compared to models like LR, DT, RF, SVM, and CNN-LSTM. The processing method in conjunction with the DL model incorporates computational techniques for identifying URL connections as either benign or phishing. The web browser installs the extension software, which was created with the Java programming tool. The steps of identifying URL process as malicious or benign shown in figure 1.
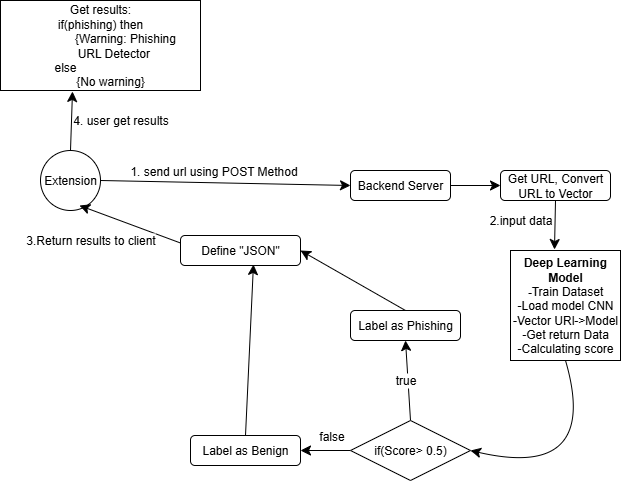
Software Extension
The software extension’s two primary functions are to submit input data to the server and receive server results. The Chromium kernel-equipped web browser, such as Microsoft Edge and Google Chrome, has the extension installed.
Processing algorithm combined with the DL model
After the extension receives the data, the results are processed, computed (for example, in steps 1–9), and then sent back to the extension.
Backend server or cloud server:
-
- Use a CNN to train the dataset with input parameters
- Receive URL data in JSON format
- Load the tokenizer term encryption function.
- Convert the data type between URL and tokenizer to vectorizer
- Load the DL model previously trained on the dataset.
- Classify the URL and make the prediction.
- The URL link is separated word by word using the tokenizer character dictionary. Then, the data are converted to a vector and fed into the trained model to predict the results.
- Process prediction probability:
If (Score < 0.5) Label:phishing else Label:benign
-
- Return the data to the extension in JSON format.
CNN, LSTM, CNN-LSTM models
CNN
Convolutional, pooling, and fully connected (FC) layers are the three pri- mary layers of CNN. The different features are extracted from the input data using the convolutional layer, which is the first layer. The convolutional layer sends the output to the following layer once features have been extracted. The pooling layer, also known as the down sampling layer, uses the max pooling and average pooling functions to lower the input’s dimensionality. In a CNN archi- tecture, the FC layer is often placed before the output layer. Prior to reaching the FC layer, the input data from the earlier layers is flattened. The FC layer, which is made up of weights and biases, is used to completely link the neurons in two distinct layers.
LSTM
An enhanced form of the recurrent neural network (RNN) is called an LSTM. The RNN’s short-term memory constraint means that it can only learn states that are close by. In order to address this issue, LSTM has been researched.
CNN-LSTM
The three primary parameters of the suggested CNN model are also used by the CNN-LSTM model layer. The LSTM model is introduced prior to the first dense layer, which is followed by the dropout layer, and the data output results (second dense layer) after that. There are 6,890,370 parameters in total after the CNN-LSTM combination model has been trained on the dataset.
Paper 2
This Research [2] proposed PhishingRTDS, a real-time detection system to detect and block phishing sites. PhishingRTDS blends URL-based and hybrid techniques. Because it necessitates accessing the suspicious webpage, it is a hybrid approach. Because it exclusively extracts URLs from HTML and JavaScript, it is also URL-based.
Data Extraction
The container was used to open the URL and explore its content. Start by opening the suspicious website and grabbing all of its JavaScript and HTML content. Since IFrame is used in BiTB attacks, we suggest deleting all URLs within the site. In order to scrape every URL within the webpage, we employ three techniques: frame sources like JFrame, Inline Frame (IFrame), and Frame URL regular expression and href attribute. Next, we determine whether or not URLs are present in the webpage’s con- tents. If there are no URLs in the webpage contents, the original URL is sent to the DL model for categorization. If not, the URLs and their webpage locations are stored in a dictionary D.
Deep Learning Model
The model has three parts: data preprocessing, feature extraction, attention layer, and classification. We explain these parts in detail as follows:
Data Preprocessing
They propose splitting URLs into character-level features as part of our data preprocessing pipeline. Character-level features can help models extract URL patterns with fewer dimensions. To do this, They first split the URL into characters. Next, we create a dictionary that contains all possible characters that can appear in a URL. They then assign a unique number to each character in the dictionary. Finally, They use this dictionary to convert each URL’s character into its corresponding number. They then use the embedding layer to convert the input into a dense vector. This allows the model to learn the embedding for all the URL characters.
Attention layer
They use Bahdanau Attention mechanism to make the model focus on the important part of the input data. The attention layer contains two parts: attention weight and context vector. The alignment model calculates the attention weight using the input value of the current hidden state layer and the previously hidden state layers. Then, they use the softmax function to normalize the weight vector between 0 and 1. Finally, they use equation to generate the context vector. The context vector is the weighted sum of the attention layer and hidden encoder state value.
Classification
They proceed to a fully connected layer once the characteristics have been extracted use a Sigmoid classification function. Binary cross-entropy is then employed as our loss function. Lastly, the Adam function is employed as an optimizer.
Decision Strategy
Single Phishing Strategy SPhS aims to protect users from a webpage con- taining a phishing URL. Therefore, they search the list to see if it contains at least one URL classified as Phishing, then it returns 0. If the list does not contain 0, then PhishingVM classifies the original webpage as benign. The user can be shielded from potential attacks via SPhS. Its drawback, meanwhile, is relying on the DL model’s categorization abilities. SPhS will raise FN even though the DL model has a lower FN value and a good accuracy. Even though this webpage is harmless, it would be flagged as phishing if the model’s forecast of any of the URLs on it were incorrect.
Mean Sum Strategy MSS aims to protect users from wrongful blocking of a benign web- page [2]. So, it searches the list, and if the label is 1, it adds one to the sum variables. In addition, it gets the length of the list len. By comparing the likelihood of phishing URLs against innocuous URLs, MSS can lower FN. It does, however, assume that all URLs are equally effective. The original URL, for instance, looks similar to social media URLs that are appended to the footer of the webpage. Consequently, it makes little difference if 60% of the other URLs are safe if the originating URL is phishing.
Weighted Average Strategy
WeAS’s goal is to differentiate between URLs based on their posi- tion. For example, the URL attached to the frame (JFrame or IFrame) is more important than the social media URL (in a webpage footer), and the original URL is more important than any other URL. Therefore, they assign weight to each URL based on its essentials. Then, they use equa- tion (10) to get the weighted average of the prediction list. Then, they use a threshold to classify if the webpage is phishing or benign. WeAS inputs are the list of collected URLs with their position D and a threshold. First, WeAS gets the length of the collected URL. Then, each URL is passed to the DL model for prediction. Then, it adds weight to the URLs using the weighted list. Then, it uses equation (10) to calculate the weighted average. Finally, they use the threshold to classify whether the webpage is phishing or benign.
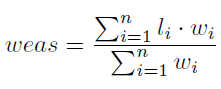
WeAS inputs are the list of collected URLs with their position D and a threshold. First, WeAS gets the length of the collected URL. Then, each URL is passed to the DL model for prediction. Then, it adds weight to the URLs using the weighted list. Then, it uses equation (10) to calculate the weighted average. Finally, we use the threshold to classify whether the webpage is phishing or benign.
Cloud server
After designing the system locally, we were aware of two possible issues. First, the system may become slower due to the network overhead brought on by connecting the browser and the container. Second, since each device would require its own container, it would be challenging to use the system across several devices. they uploaded the container to the cloud in order to address these issues. server. This made it possible for the system to function flawlessly across a variety of devices and operating systems (OS). Additionally, the cloud server made sure that the system was constantly accessible. The process begins when a user visits a website, and the URL is passed through a sequence of steps in the browser extension. The URL is then passed to a cloud server, where the system opens the webpage and classifies it within an isolation system to determine if it is potentially harmful, classifying it as Phishing or benign. The classification result is then sent back to the browser extension. Proposed methods performance shown in Table 1.
Table 1: Performance comparison of different decision strategies
Memory | Speed | Memory | Speed | Memory | Speed | ||||
SPhS strategy | 471.48 | 0.04 | 472.52 | 1.35 | 471.42 | 260.22 | |||
MSS strategy | 472.52 | 0.04 | 473.19 | 1.44 | 472.52 | 271.51 | |||
WeAS strategy | 472.46 | 0.04 | 473.51 | 1.44 | 472.46 | 271.577 |
Decision Strategy Small (1 URL) Medium (61 URL) Large (21832 URL)
Conclusion
In paper 1, a malicious URL detection method using an extension was designed to help internet users identify whether a URL is legitimate or malicious. The extension was evaluated using six ML and DL algorithms that were trained and tested on the dataset using the CM method with evaluation criteria of accuracy, prediction, and recall. The CNN algorithm overtook the remaining algorithms, LR, DT, RF, SVM, and CNN- LSTM, with the highest accuracy of 98.4% at a ratio of 8:2 is best for training and testing data, respectively. In paper 2, PhishingRTDS is a phishing detection system using DL. It protects users from three types of phishing attacks: TinyURL, BiTB, and Regular URL-based attacks. It also protects users from mistakenly downloading malicious software. It contains three parts: browser extension, Docker container, and DL model. First, it uses a browser extension to get the original URL from tiny URLs. Then, it uses the Docker container to open suspicious URLs and scrape all required features from HTML and JavaScript. Next, it uses a BiLSTM and an attention mechanism DL model trained to classify a URL, whether Phishing or benign. Finally, it uses one of three methods to classify a webpage based on the collected URLs in its HTML and JavaScript.
References
- Sultan Asiri, Yang Xiao, Saleh Alzahrani, Shuhui Li, and Tieshan Li. A survey of intelligent detection designs of html url phishing attacks. IEEe Access, 11:6421–6443, 2023.
- Sultan Asiri, Yang Xiao, Saleh Alzahrani, and Tieshan Li. Phishingrtds: A real-time detection system for phishing attacks using a deep learning model. Computers & Security, 141:103843, 2024.
- Dam Minh Linh, Ha Duy Hung, Han Minh Chau, Quang Sy Vu, and Thanh- Nam Tran. Real-time phishing detection using deep learning methods by extensions. International Journal of Electrical and Computer Engineering (IJECE), 14(3):3021–3035, 2024.
- Gupta, B. B., Gaurav, A., Chui, K. T., & Arya, V. (2024, January). Deep learning-based facial emotion detection in the metaverse. In 2024 IEEE International Conference on Consumer Electronics (ICCE) (pp. 1-6). IEEE.
- Gaurav, A., Gupta, B. B., & Chui, K. T. (2022). Edge computing-based DDoS attack detection for intelligent transportation systems. In Cyber Security, Privacy and Networking: Proceedings of ICSPN 2021 (pp. 175-184). Singapore: Springer Nature Singapore.
- Sai, K. M., Gupta, B. B., Hsu, C. H., & Peraković, D. (2021, December). Lightweight Intrusion Detection System In IoT Networks Using Raspberry pi 3b+. In SysCom (pp. 43-51).
- Aggarwal, A., Rajadesingan, A., & Kumaraguru, P. (2012, October). PhishAri: Automatic realtime phishing detection on twitter. In 2012 eCrime Researchers Summit (pp. 1-12). IEEE.
- Liew, S. W., Sani, N. F. M., Abdullah, M. T., Yaakob, R., & Sharum, M. Y. (2019). An effective security alert mechanism for real-time phishing tweet detection on Twitter. Computers & security, 83, 201-207.
- Sadique, F., Kaul, R., Badsha, S., & Sengupta, S. (2020, January). An automated framework for real-time phishing URL detection. In 2020 10th Annual Computing and Communication Workshop and Conference (CCWC) (pp. 0335-0341). IEEE.
- Ahmed, A. A., & Abdullah, N. A. (2016, October). Real time detection of phishing websites. In 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON) (pp. 1-6). IEEE.
Cite As
Rekarius (2025) Real-Time phishing detection system using Deep Learning approach by extensions, Insights2Techinfo, pp.1