By: C S Nakul Kalyan; Asia University
Abstract
In this study, we will go through the generation of synthetic data by using the deepfake technology, which is done to develop the training of artificial intelligence (AI) systems. This method utilizes Generative Adversarial Networks (GANs), Deep Convolutional GANs (DCGANs), Autoencoders, and Lip synchronization models, such as Wav2Lip, to generate realistic images, audio, and video data. The data set has been constructed from benchmark corpora and techniques for data standardization and includes procedures such as face swap- ping, attribute manipulation, and cross-modal integration. Quality assessment has been achieved through measures such as Frechet Inception Distance (FID), Inception Score (IS), and Structural Similarity Index (SSIM), and with human review and cross-model validation. To make sure that these technologies are not being misused, this method includes ethical frameworks such as watermarking, metadata tagging, and the usage of detection algorithms such as CNN, RNN, and EfficientNet architectures.
Keywords
Synthetic Data Generation, Deepfake detection, generative Adversarial Net- works (GANs), Deep Convolutional GANs (DCGANs), Frechet Inception Distance (FID), Inception Score (IS).
Introduction
Generating synthetic data has been developed as an essential strategy for dealing with data shortage, imbalance in data, and privacy concerns in using Artificial Intelligence (AI). Deepfake technology will provide an advanced mechanism for creating realistic synthetic audio and video data [4]. The deep-learning architectures such as Generative Adversarial Networks (GANs), Deep Convolutional GANs (DCGANs), and auto-encoders will be used to create good-quality, realistic images, videos, and voice. Deepfakes techniques are effective for training datasets, improve the robustness of the model, and can be applied in computer vision, Natural Language Processing, and multi-modal learning [5]. To increase the accuracy of the generation techniques, the standard metrics such as Fr´echet inception Distance (FID), Inception Score (IS), and Structural Similarity Index (SSIM) are used to increase the realism and consistency. To detect the misuses that are made by these technologies, the detection models have been integrated based on Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Efficient ensures that the manipulated data is used responsibly and the detection mechanism can be able to find the differences between the real and deepfake information [2][3]. In this article, we will go through the methodology for creating and evaluating synthetic datasets with deepfake technologies, which provides both the technical performance and precautions to enable the security for the applications of AI.
Proposed Methodology
This Method Proposes a synthetic data generation framework by using deep- fakes for fueling the AI with high-quality Fake inputs. This is a multi-modal framework that combines generative models, augmentation strategies, and evaluation mechanisms to ensure the data is real and the data is being used ethically. The framework has been explained as follows in Figure 1:
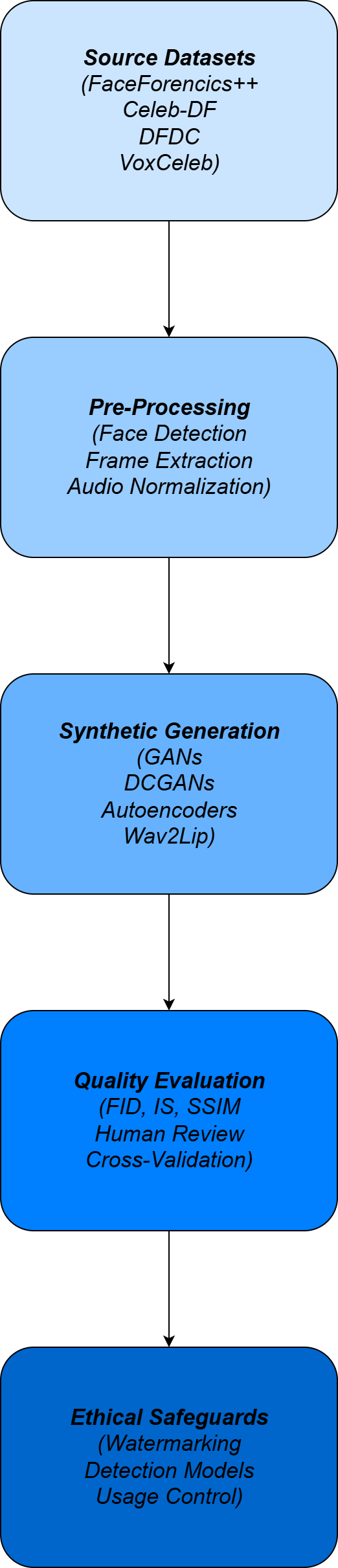
Dataset Construction and Collection
Source Datasets
The proposed system is built upon the comprehensive datasets, which is publicly available, such as FaceForencies++, Celeb-DF, and DFDC datasets have been used and datasets such as VoxCeleb and LRS2/LRS3 have been used for audio- video data. These datasets cover a wide range of speakers, expressions, lighting conditions, and various environments, which ensures the necessary of various data is present to generate reliable synthetic data.
Pre-processing
The Data which is collected will be preprocessed for standardization. Archi- tectures such as MTCNN and Mediapipe has been used to perform the face detection and alignment process in which will be used to locate the face regions. The Frame extraction will be used to convert the videos into consistent images, where the audio normalization reduces the background noise and adjusts the sampling rates. The Processing and augmentation methods have been shown in Table 1 below:
Table 1: Preprocessing and Augmentation Methods
Process | Purpose | Tools/Techniques |
Face Detection & Alignment | Standardizing input images/videos | MTCNN, Mediapipe |
Frame Extraction | Converting videos to frame sequences | OpenCV |
Audio Normalization | Cleaning and standardizing audio inputs | Librosa |
Attribute Manipulation | Modifying age, emotion, or expression | GAN-based editing |
Cross-Modal Augmentation | Combining synthetic audio with visuals | GAN + TTS + Wav2Lip |
Synthetic Data Generation
The overview of deepfake generation techniques is shown in Table 2 below: Table 2: Overview of Deepfake Generation Techniques
Technique | Description | Applications | Reference Models |
GANs | Generator–discriminator framework for creating realistic synthetic data | Face generation, attribute modification | StyleGAN, ProGAN |
DCGANs | Convolutional GANs specialized for image generation | High-resolution image synthesis | DCGAN |
Autoencoders | Encode–decode framework for reconstruction and transformation | Face swapping, reenactment | Variational Autoencoder (VAE) |
Lip-Sync Models | Synchronize audio with lip movements | Audio-visual data generation | Wav2Lip |
This is a multi-modal Framework in where it combines generative models, augmentation strategies, and evaluation metrics such as shown in Figure 2 be- low:
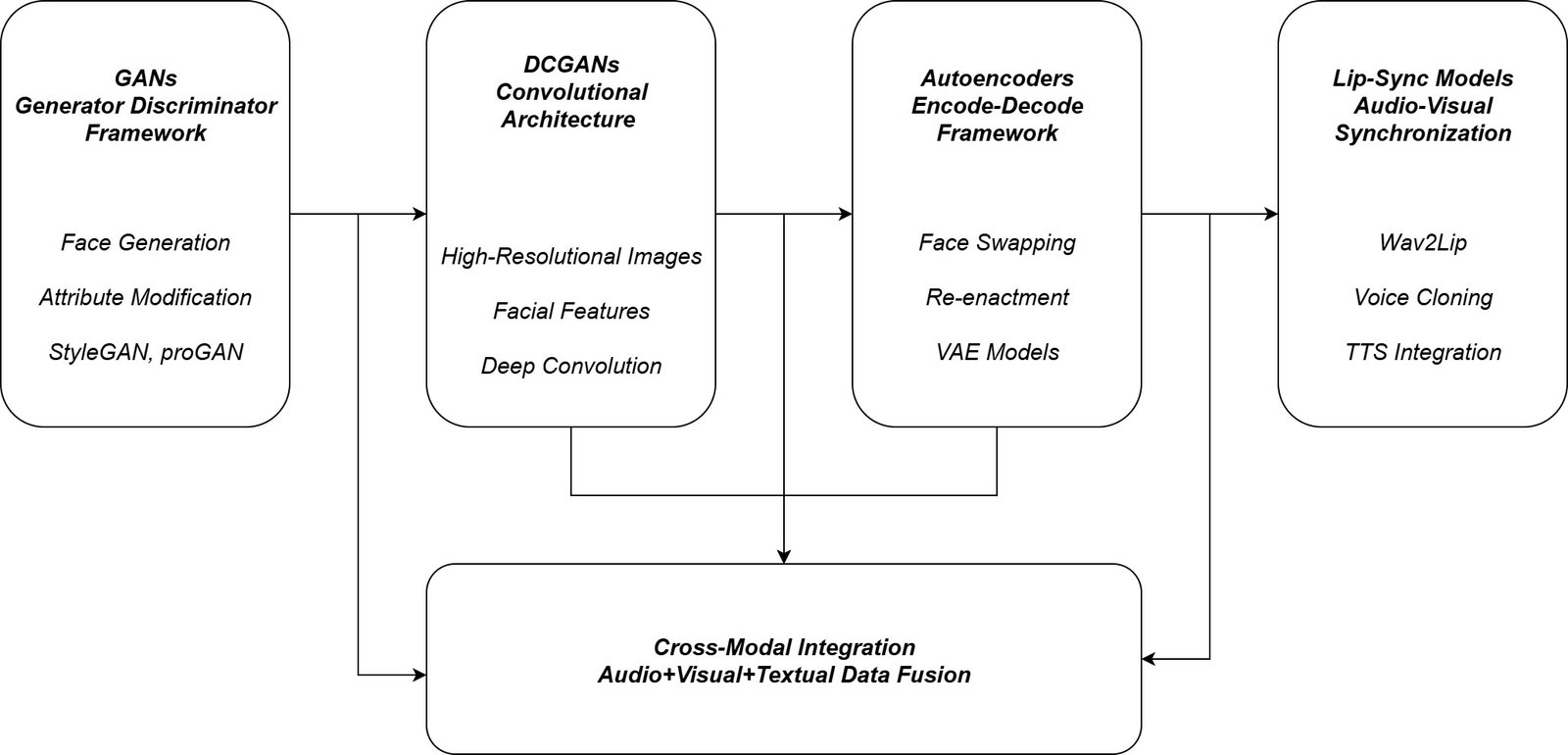
Figure 2: Multi-Modal Synthetic Data Generation Architecture
Image and Video Generation
For the Creation of Visual deepfakes, Generative Adversarial Networks (GANs) are the main backbone for creating them, and DCGANs are used to create the realistic facial images [4], where the auto-encoders are used to support the face- swapping and re-enactment process, which can be used for identity transfer and expression modification. The Lip synchronized videos are generated by tools such as Wav2Lip and reenactment GANs, which will generate the synthetic videos by altering the mouth movement with the manipulated audio.
Audio Synthesis
The techniques, such as Text-to-Speech (TTS) and Voice Cloning models, have been used to perform speech or audio synthesis [3]. These models has the capacity to produce speech in multiple languages while maintaining the speaker identity with them. To train AI systems in multilingual situations, cross-lingual synthesis is used to increase the robustness and diversity of the dataset, which can be used to train the systems.
Feature Variation and Augmentation
The data which is generated undergoes the augmentation process in which it is done to avoid over-fitting and to improve the generalization of the content. The variation and augmentation that is done are shown below:
Attribute Manipulation:
The attribute manipulation, alters the age, emotion, or the facial attributes in the data while keeping the core identity.
Environmental Variation:
The Environmental variation changes the lightning, resolution, or back- ground to provide real world simulations for the model to boost the accuracy.
Cross-Modal Augmentation:
The cross-modal augmentation combines the manipulated speech with the lip movements in the videos, which creates graphics to produce the synchronized multi-modal datasets. This ensures that the data set has the rare case scenarios, which will not be represented in real data.
Quality Evaluation of Synthetic Data
Quantitative Metrics
The quality of the generated data is assessed using:
Frechet Inception Distance (FID):
The Fr´echet Inception Distance will be used to measure the similarity between the real and fake distributions of the data that is generated.
Inception Score (IS):
The inception score evaluates only the real content that is generated, and it will have a note on how much real content is generated and the no of fake content is generated.
Structural Similarity Index (SSIM):
The structural similarity index ensures that every frame has equal frame- level uniformity in the video sequences.
Human Evaluation
The Human evaluators will check the generated content on the basis of natural- ness, realism, and deepfake detectability, where this report gives the subjective validation, which goes beyond the numerical benchmarks.
Cross-Model Testing
Here the manipulated datasets have been assessed by training the AI detection and classification models, which will help to improve the model accuracy and robustness of synthetic data in the AI training process.
Ethical Safeguards
Due to the emerging threats of using deepfakes [6], some precautions are built into this framework, such as:
Watermarking and Metadata Tagging:
The watermarking and metadata tagging are used to differentiate the manipulated samples from the real content.
Usage Restrictions:
The usage restrictions ensure that the deepfakes datasets are only being applied in research purposes and the AI Training environment, with the official authority given to them to use the datasets.
Parallel Detection models:
The models, such as CNNs, RNNs, and EfficientNet-based have been used to detect the potential misuse of generated samples [1][2].
Classification of Generated Data
There are three classification types, which are shown below:
Fully Synthetic:
The fully synthetic data is the complete deepfake data which is been generated by the Generative Adversarial Network (GANs), where there won’t be any real content.
Partially Synthetic:
The Partially Synthetic data is the face-swapped, lip-sync, or other re- enacted deepfakes, which have been combined with the real data. So here, the fake and the real data will be merged, which makes it a partial synthetic dataset.
Augmented Real:
The augmented real are the original data where only small alterations have been made, such as lightning adjustments or changes of expressions, etc.
Evaluation Metrics
Standard Metrics
The Standard evaluation metrics will assess the model’s performance by using Accuracy, Precision, Recall, and F1-score, where it ensures that the results are statistically reliable.
Realism Metrics
To detect the Realism from the sample, two metrics have been used, such as:
Lip-sync Error Rate (LSER):
The Lip-sync Error rate is being used to measure the accuracy of alignment between the generated audio and video. So it will assess the lip-sync movements to determine whether the content is real or fabricated.
Perceptual Realism Score (PRS):
The Perceptual Realism score makes sure that the content that is viewed by humans is real.
Robustness Testing
Robustness of the model has been tested based on multiple scenarios, such as:
Video Lengths:
The video lengths, which range from 15 seconds to 5 minutes, have been tested for robustness by using specific metrics.
Resolution Levels:
The resolution levels from the low-quality (240p) to high-definition(1080p) have been tested for robustness.
Multilingual Settings:
The multilingual settings make sure that the tonal and non-tonal languages have been tested for robustness.
Conclusion
This article has produced a structured method to create synthetic media by using deepfakes, by integrating advanced generative models such as generative models, augmentation strategies, and evaluation metrics to build scalable and realistic datasets. In this framework, we can see that approaches such as GANs, DCGANs, Autoencoders, and Lip-sync models can generate high-quality syn- thetic inputs to improve AI training and to improve robustness. The quality of the generated content has been assessed using FID, IS, and, SSIM, where they support the cross-model validation. The precautionary measures, such as watermarking and detecting deepfakes, have been done based on using models such as CNN, RNN, and EfficientNet, which reduces the misuse of these deep- fake technologies. Therefore, the proposed method provides a controlled way of fueling AI development while maintaining ethical and responsible practices.
References
- Xinghe Fu, Benzun Fu, Shen Chen, Taiping Yao, Yiting Wang, Shouhong Ding, Xiubo Liang, and Xi Li. Faces blind your eyes: Unveiling the content- irrelevant synthetic artifacts for deepfake detection. IEEE Transactions on Image Processing, 2025.
- Priyanshu Hirpara, Hardi Valangar, Vishwa Kachhadiya, and Uttam Chauhan. Deepfake detection: Demodulate synthetic videos using deep learning models. In 2025 12th International Conference on Computing for Sustainable Global Development (INDIACom), pages 01–06. IEEE, 2025.
- Eshika Jain and Amanveer Singh. Deepfake voice detection using convolu- tional neural networks: A comprehensive approach to identifying synthetic audio. In 2024 International Conference on Communication, Control, and Intelligent Systems (CCIS), pages 1–5. IEEE, 2024.
- Ayushi Mishra, Aadi Bharwaj, Aditya Kumar Yadav, Khushi Batra, and Nidhi Mishra. Deepfakes-generating synthetic images, and detecting artifi- cially generated fake visuals using deep learning. In 2024 14th International Conference on Cloud Computing, Data Science & Engineering (Confluence), pages 587–592. IEEE, 2024.
- Satyareddy Ogireddy and Gauri Mathur. Deepfake detection in the age of synthetic media: A systematic review. In 2025 International Conference on Networks and Cryptology (NETCRYPT), pages 1759–1763. IEEE, 2025.
- Shivansh Uppal, Vinayak Banga, Sakshi Neeraj, and Abhishek Singhal. A comprehensive study on mitigating synthetic identity threats using deep- fake detection mechanisms. In 2024 14th International Conference on Cloud Computing, Data Science & Engineering (Confluence), pages 750– 755. IEEE, 2024.
- Al-Ayyoub, M., AlZu’bi, S., Jararweh, Y., Shehab, M. A., & Gupta, B. B. (2018). Accelerating 3D medical volume segmentation using GPUs. Multimedia Tools and Applications, 77(4), 4939-4958.
- Gupta, S., & Gupta, B. B. (2015, May). PHP-sensor: a prototype method to discover workflow violation and XSS vulnerabilities in PHP web applications. In Proceedings of the 12th ACM international conference on computing frontiers (pp. 1-8).
- Gupta, S., & Gupta, B. B. (2018). XSS-secure as a service for the platforms of online social network-based multimedia web applications in cloud. Multimedia Tools and Applications, 77(4), 4829-4861.
Cite As
Kalyan C S N (2025) Synthetic Data Generation Using Deepfakes: Fueling AI with Fake Inputs, Insights2Techinfo, pp.1