By: Rekarius, CCRI, Asia University, Taiwan
Abstract
Phishing attacks exploit human and technological vulnerabilities to steal sensitive information, posing a significant threat to online security. In recent years, cyber threats including malicious software, virus, spam, and phishing have grown aggressively via compromised Uniform Resource Locators (URLs). However, the current phishing URL detection solutions based on supervised learning use labeled data for training and classification, leading to the dependency on known attacking patterns. This study focuses on URLs phishing detection model built upon a transformer-based architecture. Results from various experiments showed that BERT-Medium outperformed other transformer-based models in detecting malicious URLs, achieving the highest performance accuracy of 98.55%.
Keywords URLs Phishing Detection, BERT, Transformer-Based Model, URLTran
Introduction
Accessing the Internet for communication, email, e-banking, e-commerce, e- learning, e-governance, and other productivities is almost impossible unless users interact with a specific website. However, because phishing websites resemble benign and not all online users have adequate insights and skills on how to discriminate between benign and phishing websites, they are duped into disclosing valuable information such as login credentials, ATM passcode, and details of credit card, bank account, and Social Security Number (SNN) to the carefully crafted phishing sites [2]. The phishing website attack success may result in losses in finances, productivity, reputability, credibility, continuity, and damage to national security [11]. Therefore, the development of cyberattack detection systems is essential for the security of sensitive and personal data, data exchanges, and online transactions [3]. This paper focuses on exploring the utilization of transformer-based architectures for detecting phishing URLs.
Related Work and Method
Over the past few years, transformer models have been utilized for phishing detection mainly via URL, email, and Short Message Service (SMS) [4].
- URLTran
For instance, a transformer- based model, named URLTran, was developed in [8] for phishing URL detection. Three variants of URLTran were used, including URLTran BERT, URLTran RoBERTa, and URLTran CustVoc. URL- Tran BERT and URLTran RoBERTa were implemented using the pre- training data from their respective publicly available vocabularies, while URLTran CustVoc was constructed using a domain-specific vocabulary. These three transformer models were then compared with DL architectures, such as URLNet [7] and Texception [10]. Results from the experiments revealed that transformer-based models provided higher detection accuracy than DL-based solutions.
URLTran Method Phishing URL Data
The datasets used for training, validation and testing were collected from Microsoft’s Edge and Internet Explorer production browsing telemetry during the summer of 2019. The schema for all three datasets is similar and consists of the browsing URL and a boolean determination of whether the URL has been identified as phishing or benign. The resulting training dataset had the total size of 1,039,413 records with 77,870 phishing URLs and 961,543 benign URLs. Of the 259,854 URLs in the validation set, 19,468 corresponded to phishing sites and 240,386 to benign sites. The test set used for evaluating the models con- sists of 1,784,155 records, of which 8,742 are phishing URLs and the remaining 1,775,413 are benign.
Architecture
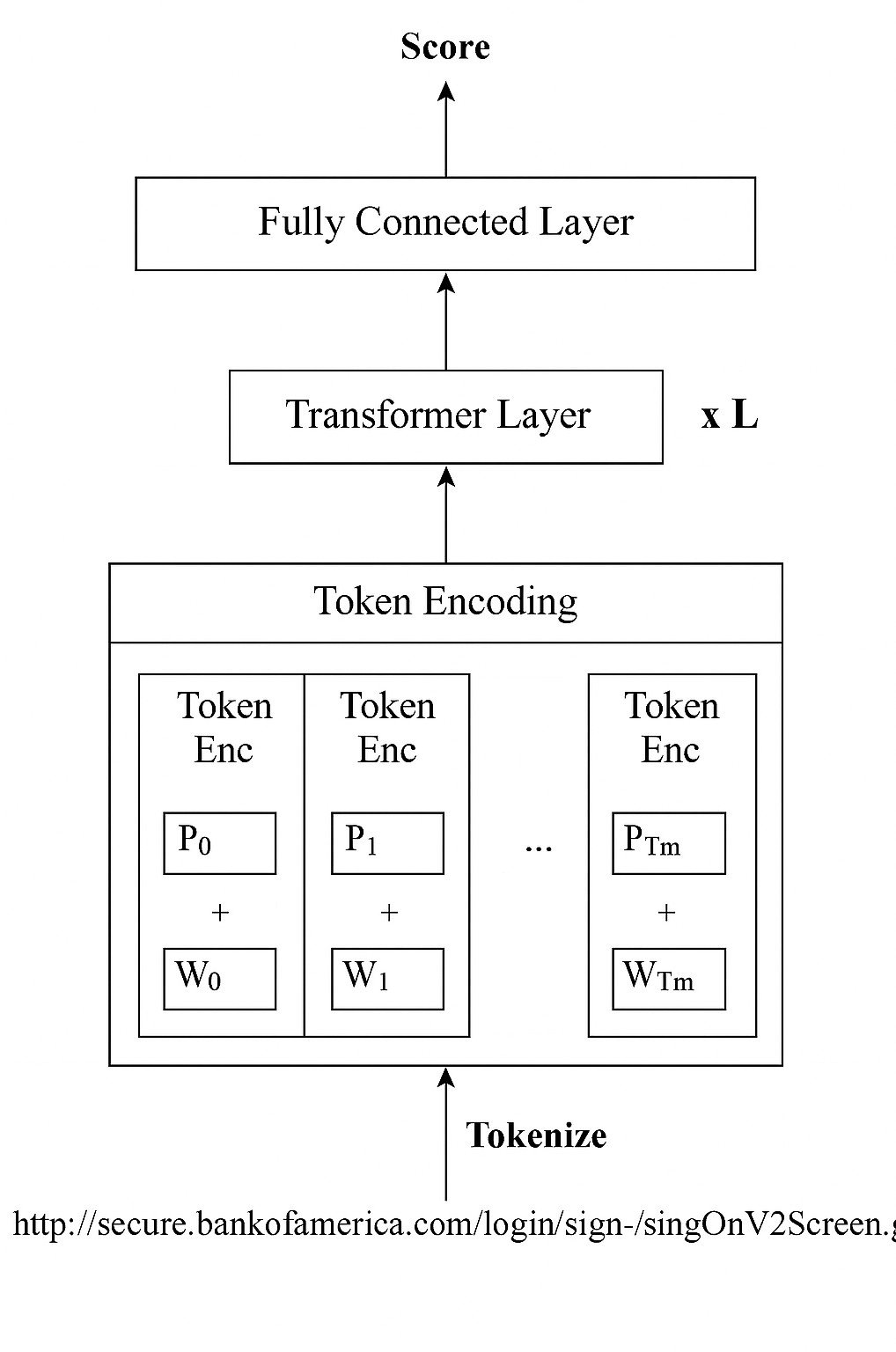
The general architecture of all the explored models takes a three stage ap- proach for inference shown in Figure 1.
-
- Tokenization
The raw input to the URLTran model is the URL, which can be viewed as a text sequence. The first step in the phishing URL detection task involves con- verting this input URL into a numerical vector which can be further processed by a classical machine learning or deep learning model.
-
- Classifier
the transformer embeddings uses for two tasks: pre-training masked language models and fine-tuning for classification of phishing URLs. For pretraining, a dense layer having vocab size classes is used for predicting the masked token for the masked language modeling task. They use two-class classification for the fine- tuning model where the two classes are 1 for a phishing URL and 0 if the URL is benign.
Training
- Masked Language Modeling (MLM):
The MLM task is commonly used to perform pre-training for transformers where a random subset of tokens is replaced by a special ‘[MASK]’ token.
- Fine-Tuning: The initial parameters for URLTran BERT and URLTran RoBERTa are derived using a large natural language corpus generated by their respective authors, were used. For URLTran CustVoc, the final learned weignts from the MLM pre-training step were used as initialization values. Next, URL- Tran’s model parameters were further improved using a second “fine-tuning” training process which utilizes the error signal from the URL classification task and gradients based on gradient descent using the Adam [1] optimizer with the cross-entropy loss.
Adversarial Attacks and Data Augmentation
Phishing URL attacks can occur on short-lived domains and URLs which have small differences from existing, legitimate domains. They simulate two at- tack scenarios by constructing examples of such adversaries based on modifying benign URLs. They also utilize a reordering-based augmentation, which is used to generate benign perturbations for evaluating adversarial attacks.
- Homoglyph Attack: We generate domains that appear nearly identical to legitimate URLs by substituting characters with other unicode characters that are similar in appearance.
- Compound Attack: An alternative way to construct new phishing URLs is by splitting domains into sub-words (restricted to English) and then concatenating the sub-words with an intermediate hyphen.
- Parameter Reordering: We extend text-aumentation approaches [6] for URL augmentation. As the query parameters of a URL are interpreted as a key-value dictionary, this augmentation incorporates permutation invariance.
- Adversarial Attack Data: The approach we use for generating data for an adversarial attack includes generating separate augmented training, validation and test datasets based on their original dataset [5]. For each URL processed in these datasets, we generate a random number. If it is less than 0.5, we augment the URL, or otherwise, we include it in its original form. For URLs which are to be augmented, we modify it using either a homoglyph attack, a compound attack, or parameter reordering with equal probability. If a URL has been augmented, we also include the original URL in the augmented dataset.
Threat Model
The threat model for URLTran allows for the attacker to create any phishing URL including those which employ domain squatting techniques. In its current form, URLTran is protected against homoglyph and compound word attacks through dataset augmentation. However, any domain squatting attacks can also be simulated and included in the augmented adversarial training, validation, and test sets. In addition, a larger number of adversarial training examples can be directed at more popular domains such as https://www.bankofamerica.com that may be a target of attackers. They assume that inference can be executed by the counter- measure system prior to the user visiting the unknown page. This can be done by the email system at scale by evaluating multiple URLs in parallel. In our evaluation, They found that URLTran requires 0.36096 milliseconds per URL on average which is a reasonable amount of latency.
The Transformer-Based Model
BERT implementation consists of two steps: pre-training and fine-tuning. The former trains the model using unlabelled data from different vocabularies, while the latter fine-tunes the model using labelled data from the downstream task (classification) [4]. Initially, website URLs were pre-processed by tokenizing the textual data into word sequences and acting as inputs to the pre-trained transformer-based model. The pre- trained model and its processor were down- loaded from the Tensorflow hub and then fine-tuned for the URL classification task using a fully-connected (FC) layer. Finally, a single neuron was used in the output layer with a Sigmoid function to decide the class label of the URLs.
Table I provides the parameter settings for different architectures of BERT models. In this table, L denotes the number of layers or transformer blocks, H refers to the hidden size, and A is the number of self-attention heads.
To evaluate the performance of the transformer-based model, a public dataset called Ebbu2017 [9] was used.
This dataset consisted of 73,575 URLs, including 36,400 malicious websites from PhishTank and 37,175 benign websites from Yandex. The dataset was split
Model | L | H | A |
BERT-Tiny | 2 | 128 | 2 |
BERT-Mini | 4 | 256 | 4 |
BERT-Small | 4 | 512 | 8 |
BERT-Medium | 8 | 512 | 8 |
BERT-Base-uncased | 12 | 768 | 12 |
BERT-Base-cased | 12 | 768 | 12 |
ALBERT-Base | 12 | 768 | 12 |
ELECTRA-Small | 12 | 256 | 4 |
ELECTRA-Base | 12 | 768 | 12 |
DistilBERT-cased | 6 | 768 | 12 |
DistilBERT-uncased | 6 | 768 | 12 |
MobileBERT | 24 | 512 | 4 |
Table 1: Parameter Settings Of Different BERT Models
into three different portions for training, validation, and testing with a ratio of 8:1:1.
Table II summarizes the experimental results obtained from various transformer- based models.
Model | Pr (%) | Rc (%) | F1 (%) | AUC (%) | Acc (%) |
BERT-Tiny | 98.30 | 97.39 | 97.85 | 99.55 | 97.85 |
BERT-Mini | 98.17 | 98.87 | 98.52 | 99.76 | 98.46 |
BERT-Small | 98.13 | 98.58 | 98.36 | 99.57 | 98.53 |
BERT-Medium | 98.55 | 98.57 | 98.56 | 99.67 | 98.55 |
BERT-Base-uncased | 98.54 | 98.43 | 98.48 | 99.65 | 98.45 |
BERT-Base-cased | 97.33 | 98.75 | 98.03 | 99.63 | 98.42 |
ALBERT-Base | 98.98 | 96.61 | 97.78 | 99.73 | 97.78 |
ELECTRA-Small | 98.74 | 97.57 | 98.15 | 99.74 | 98.15 |
ELECTRA-Base | 98.47 | 97.71 | 98.09 | 99.78 | 98.06 |
DistilBERT-cased | 97.28 | 99.20 | 98.23 | 99.83 | 98.21 |
DistilBERT-uncased | 98.01 | 98.17 | 98.09 | 99.48 | 98.10 |
MobileBERT | 98.07 | 98.74 | 98.40 | 99.73 | 98.41 |
Table 2: Evaluation Metrics Of Various Models
Conclusion
They have proposed a new transformer-based system called URLTran whose goal is to predict the label of an unknown URL as either one which references a phishing or a benign web page. In this work, They demonstrate that transformers which are fine-tuned using the standard BERT tasks also work remarkably well for the task of predicting phishing URLs.
The proposed model employed BERT to determine the class label of web- page URLs as legitimate or phishing based on the extracted features. Re- sults from various experiments showed that BERT-Medium outperformed other transformer-based models in detecting malicious URLs, achieving the highest performance accuracy of 98.55%.
References
- Kingma DP Ba J Adam et al. A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 1412(6), 2014.
- Kibreab Adane, Berhanu Beyene, and Mohammed Abebe. Ml and dl- based phishing website detection: The effects of varied size datasets and informative feature selection techniques. Journal of Artificial Intelligence and Technology, 4(1):18–30, 2024.
- Odiaga Gloria Awuor. Assessment of existing cyber-attack detection mod- els for web-based systems. Global Journal of Engineering and Technology Advances, 15(01):070–089, 2023.
- Nguyet Quang Do, Ali Selamat, Kok Cheng Lim, Ondrej Krejcar, and Nor Azura Md Ghani. Transformer-based model for malicious url classification. In 2023 IEEE International Conference on Computing (ICOCO), pages 323–327. IEEE, 2023.
- Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Sosuke Kobayashi. Contextual augmentation: Data augmentation by words with paradigmatic relations. arXiv preprint arXiv:1805.06201, 2018.
- Hung Le, Quang Pham, Doyen Sahoo, and Steven CH Hoi. Urlnet: Learn- ing a url representation with deep learning for malicious url detection. arXiv preprint arXiv:1802.03162, 2018.
- Pranav Maneriker, Jack W Stokes, Edir Garcia Lazo, Diana Carutasu, Farid Tajaddodianfar, and Arun Gururajan. Urltran: Improving phishing url detection using transformers. In MILCOM 2021-2021 IEEE Military Communications Conference (MILCOM), pages 197–204. IEEE, 2021.
- Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, and Banu Diri. Machine learning based phishing detection from urls. Expert Systems with Applications, 117:345–357, 2019.
- Farid Tajaddodianfar, Jack W Stokes, and Arun Gururajan. Texception: A character/word-level deep learning model for phishing url detection. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2857–2861. IEEE, 2020.
- Ammara Zamir, Hikmat Ullah Khan, Tassawar Iqbal, Nazish Yousaf, Farah Aslam, Almas Anjum, and Maryam Hamdani. Phishing web site detec- tion using diverse machine learning algorithms. The Electronic Library, 38(1):65–80, 2020.
- Gupta, B. B., Gaurav, A., Arya, V., & Alhalabi, W. (2024). The evolution of intellectual property rights in metaverse based Industry 4.0 paradigms. International Entrepreneurship and Management Journal, 20(2), 1111-1126.
- Zhang, T., Zhang, Z., Zhao, K., Gupta, B. B., & Arya, V. (2023). A lightweight cross-domain authentication protocol for trusted access to industrial internet. International Journal on Semantic Web and Information Systems (IJSWIS), 19(1), 1-25.
- Jain, D. K., Eyre, Y. G. M., Kumar, A., Gupta, B. B., & Kotecha, K. (2024). Knowledge-based data processing for multilingual natural language analysis. ACM Transactions on Asian and Low-Resource Language Information Processing, 23(5), 1-16.
Cite As
Rekarius (2025) Transformer-based Model For Phishing URL Classification, Insights2Techinfo, pp.1