By: C S Nakul Kalyan, CCRI, Asia University, Taiwan
Abstract
The advancement of Artificial Intelligence has led to the development of Voice cloning, which contains Features that closely mimic the Tone, Pitch, and Style of the Target Speaker. These Voice cloning technologies have been used mainly in personalized virtual assistants, marketing, and gaming purposes. Due to this rapid development of AI, they pose a serious threat to Privacy, Security, and Digital Trust due to their misuse in Creating Deepfake audio. In this article, we will go through Voice Cloning, and techniques such as Mel-Frequency Cepstral Coefficients (MFCC) used in feature extraction, and models like MFCC-GNB XtractNet used for detecting Deepfake Voices. By using Machine Learning models and analyzing the various audio Representations, which also include Spectograms and Chromograms where we can have High accuracy in finding the Difference between Real and Fake Voices.
Keywords
Voice Cloning, Artificial Intelligence, Mel-Frequency Cepstral Coefficients (MFCC), Spectrogram, Chromagram.
Introduction
The Growth of Artificial Intelligence and Deep Learning has produced a path for advancements in Voice Spoofing, where it mimics the Voice of Real individuals they matching their Tone, Pitch, and Style of the Person [4]. By training on the datasets of the Voice Recordings, the Deepfake systems can produce audio which are same as the actual speech, where it can be applied in various ways such as dubbing, media content, and Entertainment purposes [3]. However, this technology has the ability to imitate the person’s voice, leading to the misuse of the technology such as identity theft, Fraudulent Transactions, Misinforma- tion, etc [2]. As the Deepfake voice Technology has become more advanced,
the Traditional detection methods are struggling to differentiate between Real and Fake audio [1][5]. The study introduces a model, MFCC-GNB XtractNet, which combines the Mel-Frequency Cepstral Coefficient, which includes Gaus- sian Naive Bayes (GNB) for the feature extraction, and the Non-Negative Matrix Factorisation (NMF) to detect the Deepfake voices [4]. The K-fold Validation is used to evaluate the model’s performance in which it can perform in real-world Scenarios [5]. In this article, we will go through voice cloning and the proposed model for Deepfake voice detection methodologies.
Literature Analysis
The Proposed Methodology contains 2 core components: Voice cloning and Fake audio detection, where each method is built upon the Deep learning techniques and signal processing algorithms that can be used to detect Fake voices [3][4].
Voice Cloning
The voice cloning process uses Neural Network architectures such as Tacotron and waveNet for the combination of speeches. Tacotron converts the textual input to spectrograms, and the work of the WaveNet is to synthesize realistic audio waveforms from these spectrograms as mentioned in (Figure 1).To support the multi-speaker models, transfer learning is used to enhance flexibility and adaptability, which clones the different voice types and emotional tones [4]. Here the parameters like pitch, tone, and emotions can be modified by the users through the interactive interface.
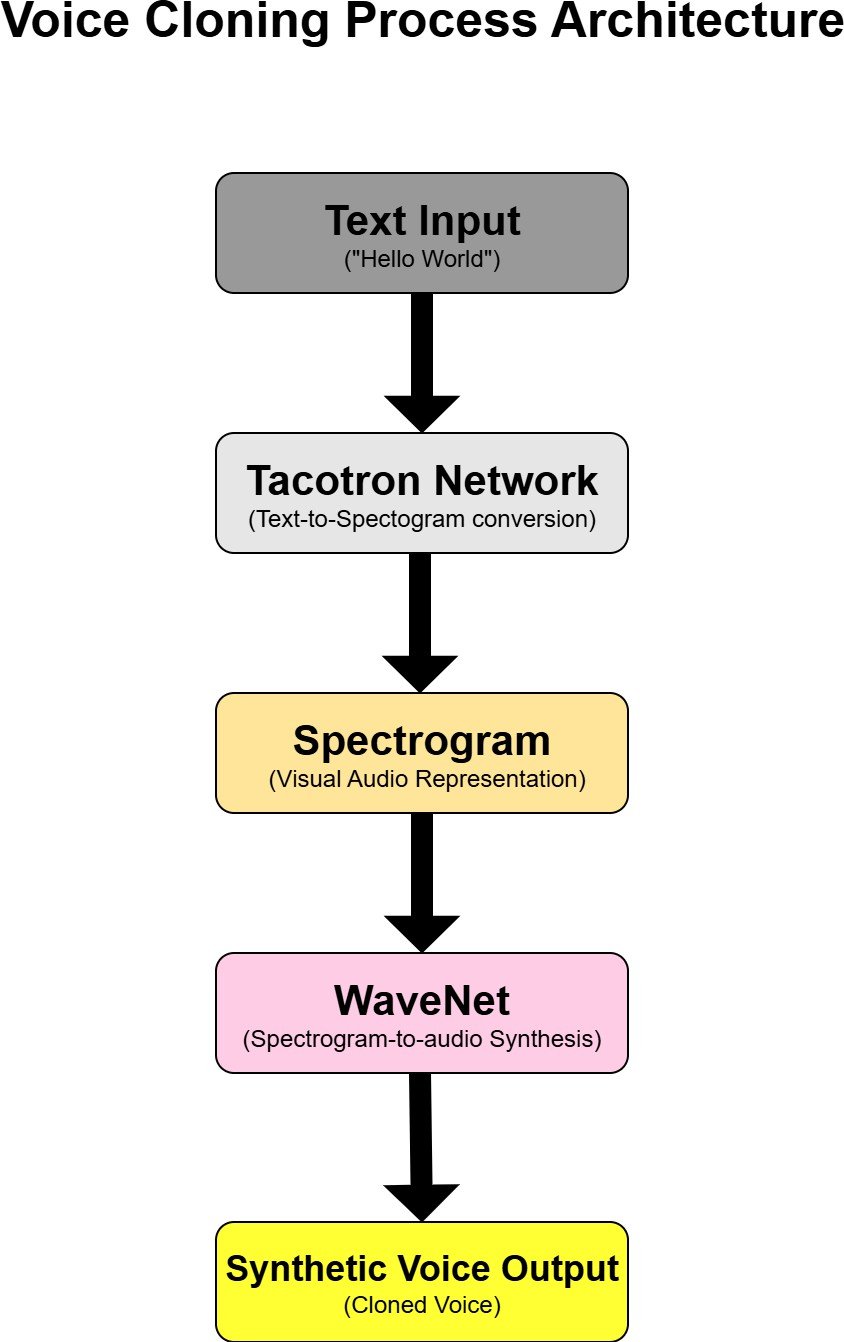
Fake Audio Detection
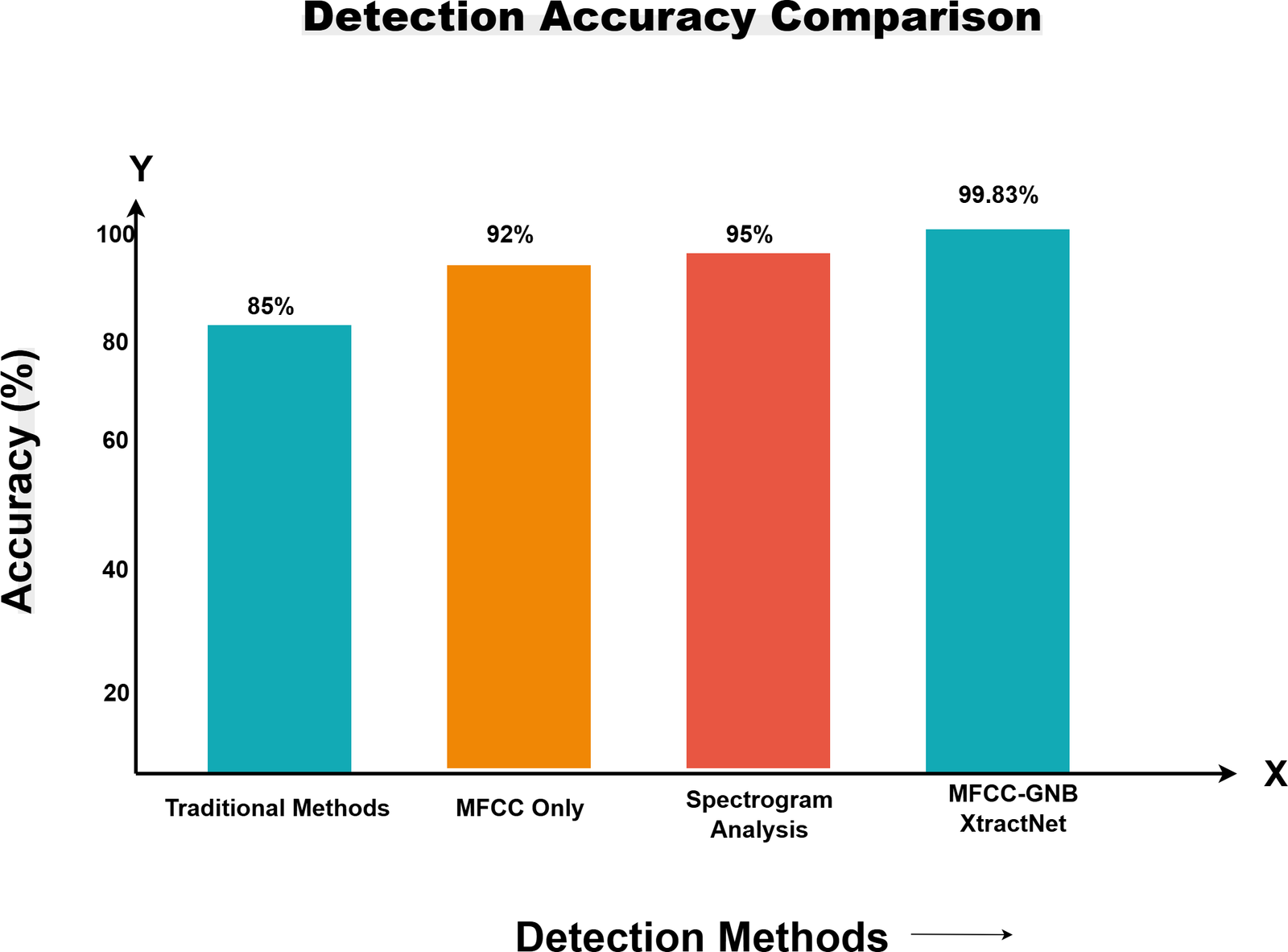
To act against the misuse of synthetic voices, the system contains a detection method that uses machine learning algorithms which is trained on both real and manipulated audio [2][5]. The audio features, such as Mel-frequency cep- stral coefficients (MFCCs), Spectrograms, and linguistic patterns, have been extracted and analyzed [1][3]. The hybrid models, such as the MFCC-GNB XtractNet, which combines the Gaussian Naive Bayes (GNB) with the deep learning based Feature extraction and the dimensionality Reduction techniques like Non-negative Matrix Factorization (NMF), are included in the Detection Framework [2][4] as mentioned in (Table 1) as well as mentioned as (Figure 2).
Table 1: Comparison of Audio Feature Extraction Techniques
FEATURE TYPES | APPLICATION | ADVANTAGES | DETECTION ACCURACY |
MFCC | Voice Cloning Detection | Captures Spectral Characteristics | High |
Spectograms | Real time analysis | Visual Representation of frequencies | Moderate |
Chromograms | Pitch-Based Detection | Tonal Analysis | Moderate |
Linguistic Patterns | Semantic Analysis | Context-Aware Detection | Variable |
Hybrid (MFCC-GNB) | Comprehensive Detection | Combines Multiple Approaches | 99.83 percentage |
Model Deployment
The performance and the scalability of the system are optimised [3]. With the usage of parallel computing and Distributed processing, the model provides a low-latency interface, and it can handle large-scale datasets efficiently [1]. This system can be deployed at various platforms such as the Cloud platforms, Edge devices, and mobile applications [5].
Ethical Considerations
This method has a Privacy-preserving mechanism to keep the sensitive data safe and follows all ethical guidelines, and it follows the usage limitations of the Voice cloning to prevent misuse [2][3].
Conclusion
This article consists of the advancement in voice Technology through developing a voice cloning system and a deepfake audio detection framework using mod- els like Tacotron and WaveNet for synthesizing speech, and the MFCC-GNB XtractNet model used to detect Deepfake voices by having a great accuracy of
99.83. By using these approaches, the model can identify the Synthetic audio
in real-time. These Technologies will face the issues in disinformation, voice authentication, and the integrity of the content, where it focuses on ethical development and comes forward to secure the future of the synthetic speech Technology.
References
- Jordan J Bird and Ahmad Lotfi. Real-time detection of ai-generated speech for deepfake voice conversion. arXiv preprint arXiv:2308.12734, 2023.
- Ali Javed, Khalid Mahmood Malik, Hafiz Malik, and Aun Irtaza. Voice spoofing detector: A unified anti-spoofing framework. Expert Systems with Applications, 198:116770, 2022.
- Mvelo Mcuba, Avinash Singh, Richard Adeyemi Ikuesan, and Hein Venter. The effect of deep learning methods on deepfake audio detection for digital investigation. Procedia Computer Science, 219:211–219, 2023.
- G Tamilselvan, Manas Biswal, et al. Voice cloning & deep fake audio detec- tion using deep learning. International Journal of Advanced Research and Interdisciplinary Scientific Endeavours, 2(1):415–419, 2025.
- Muhammad Usama Tanveer, Kashif Munir, Madiha Amjad, Atiq Ur Rehman, and Amine Bermak. Unmasking the fake: Machine learning ap- proach for deepfake voice detection. IEEE Access, 2024.
- Gupta, B. B., Gaurav, A., Arya, V., & Alhalabi, W. (2024). The evolution of intellectual property rights in metaverse based Industry 4.0 paradigms. International Entrepreneurship and Management Journal, 20(2), 1111-1126.
- Zhang, T., Zhang, Z., Zhao, K., Gupta, B. B., & Arya, V. (2023). A lightweight cross-domain authentication protocol for trusted access to industrial internet. International Journal on Semantic Web and Information Systems (IJSWIS), 19(1), 1-25.
- Jain, D. K., Eyre, Y. G. M., Kumar, A., Gupta, B. B., & Kotecha, K. (2024). Knowledge-based data processing for multilingual natural language analysis. ACM Transactions on Asian and Low-Resource Language Information Processing, 23(5), 1-16.
- Choi, K., Lee, J. L., & Chun, Y. T. (2017). Voice phishing fraud and its modus operandi. Security Journal, 30(2), 454-466.
- Kim, J., Kim, J., Wi, S., Kim, Y., & Son, S. (2022, June). HearMeOut: detecting voice phishing activities in Android. In Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services (pp. 422-435).
- Lee, M., & Park, E. (2023). Real-time Korean voice phishing detection based on machine learning approaches. Journal of Ambient Intelligence and Humanized Computing, 14(7), 8173-8184.
Cite As
Kalyan C S N (2025) Voice Cloning with AI: The Rise of Synthetic Speech, Insights2Techinfo, pp.1