By: Mamta
In today’s digital world, we can connect with billions of people around the globe, and at the same time, we are provided access to an unlimited amount of data. At the core of our digital life lies the Internet which makes this connection possible. We often produce massive amounts of data simply by going about our daily lives: scanning barcodes for consumer goods, navigating with location sensors in our smart devices, being tracked by geospatial information systems on the road, and using electricity measured by digital meters built into the power grid. We are generating so much data at such a rapid rate that 90 percent of all data has been produced in the previous two years [1]. The difficulty of storing, disseminating, and interpreting this data is so great that it has created its own area of research and industry: Big data. The majority of the digital data we create on a daily basis is either redundant or useless unless we analyse it to extract important information. This is where big data analytics comes into the picture and is one of the most important parts of big data analytics in assessing the value of digital data. Figure 1 depicts the major advantages of adopting big data analytics. According to studies, one of the biggest benefits of Big Data Analytics is that it helps organisations make better decisions. Roughly 16 percent stated they were better equipped to support the industry’s main strategic goals, and about 10% said their customer connections had improved. A greater awareness of risk and better financial performance each contributed around 9% to the benefits.
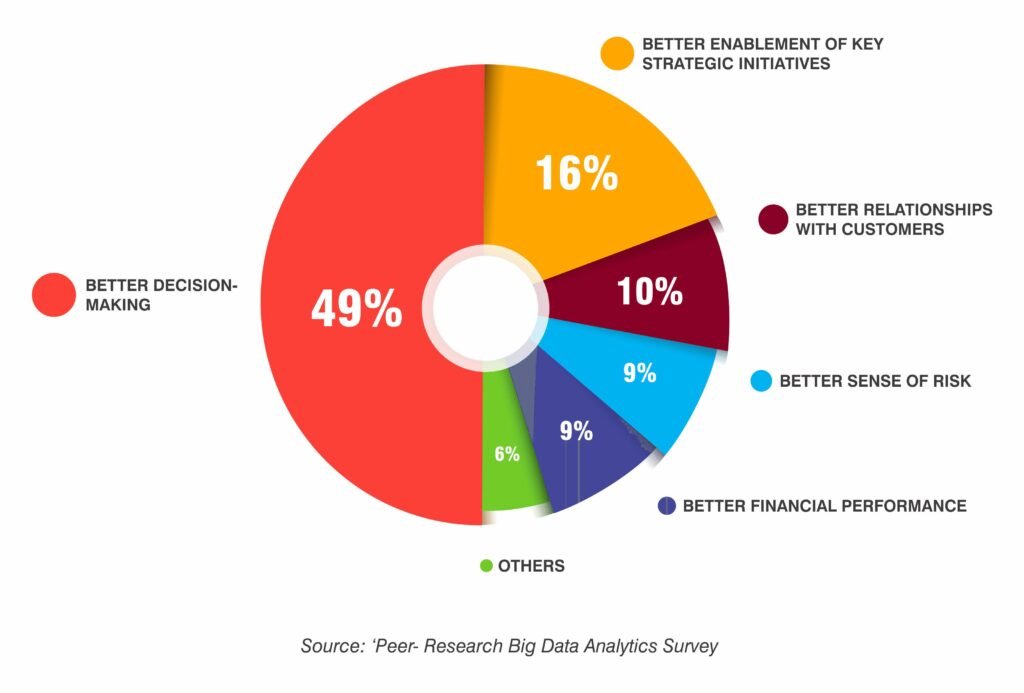
All of the other perks contained in the package were set at 6%. About 40% of the firms said they were utilising Big Data Analytics in some manner and that it was beneficial to their business. 35% of those polled thought that analytics might assist forecast many other elements of company. When it comes to recognising customer trends and patterns, about 25% believed they had a competitive advantage. It is said to have enhanced operating efficiency by additional 20%.
To further understand the picture clearly, let us take one use case in the healthcare industry because digitalization and technological advancements have entirely transformed the healthcare sector. With digitalization, the terms like E-Health, M-health becomes quite prevalent [2-3]. The use of information technology and telecommunications in healthcare is referred to as e-health. Prescription renewals, online appointments, exchanging healthcare data and medical records via a particular program, and many more features are included in this. M-health, on the other hand, is a sub-domain of e-health in which mobile devices are utilized to provide healthcare services. It involves the use of communication technologies such as smartphones, PDAs, tablets, and wearable devices such as smartwatches for health and medical records treatment and maintenance. E-health and m-health have a number of advantages, including the availability and accessibility of healthcare services, low costs of distribution, customization, and real-time treatment of patients, among others. In the healthcare domain, volume, velocity, and variety are three primary characteristics of the data.
Health-related data will be continually produced and gathered over time, culminating in an enormous amount of data. Fortunately, to handle large volumes of data, improvements in data management, particularly cloud computing and fog computing, are making it easier to build platforms for more efficient data gathering, storage, and processing. Further, the data is collected in real-time and at a high velocity. The continual flow of fresh data, which is accumulated at an unprecedented rate, poses new problems. In the same way, as the volume and variety of data gathered and stored have changed, so has the pace at which it is created, which is required for retrieving, analyzing, comparing, and making choices based on the result.
As the nature of health data has changed, so has the complexity and sophistication of analytics approaches required to handle the volume, velocity, and variety of data. To analyze the large volumes of structured and unstructured healthcare data, one can employ deep learning approaches. Deep learning is a multi-layered structure having the capability to learn from unstructured data that makes it an efficient tool for big data analytics. Self-learning, self-training, adaptive and dynamic features of deep learning make it suitable for processing and analyzing the big data with 3V’s characteristics. Deep learning in big data has many applications like patient monitoring, healthcare information technology, intelligent assistance, and diagnosis, and information analysis and collaboration. Health information is not only for storage and passing to other medical fellows. It needs to be well analyzed, for example, pattern detection by deep learning is being utilized to detect any specific symptom of a disease.
Deep learning has proved to be beneficial in analyzing big data. However, there remain many challenges in making full use of big data, due to its high dimensionality, variability, temporal dependence, and sparsity [4].
References
[1] Herschel, R., & Miori, V. M. (2017). Ethics & big data. Technology in Society, 49, 31-36.
[2] Blaya, J. A., Fraser, H. S., & Holt, B. (2010). E-health technologies show promise in developing countries. Health Affairs, 29(2), 244-251.
[3] Silva, B. M., Rodrigues, J. J., de la Torre Díez, I., López-Coronado, M., & Saleem, K. (2015). Mobile-health: A review of current state in 2015. Journal of biomedical informatics, 56, 265-272.
[4] Miotto, R., Wang, F., Wang, S., Jiang, X., & Dudley, J. T. (2018). Deep learning for healthcare: review, opportunities and challenges. Briefings in bioinformatics, 19(6), 1236-1246.
Cite this article as:
Mamta (2021) Big Data: The Part and Parcel of Today’s Digital World, Insights2Techinfo