By: Nicko Cajes; Northern Bukidnon State College, Philippines
Abstract
Phishing done using SMS or “smishing” is a cyber-attack which utilizes the SMS to send fraudulent messages that aims to steal the victims’ credentials. Machine learning techniques were an effective countermeasure in this scenario as they effectively classify fraudulent and legitimate messages. Process in development and detection involves feature extraction, model training, and evaluation of the model performance with the use of the common evaluation metrics like the accuracy and confusion matrix. However, a specific challenge that plays a crucial role in the model development is present which is the dataset imbalance, techniques such as the random oversampling can help solve this issue. This study highlights the role of ML to improve the cybersecurity landscape against the smishing attack.
Introduction
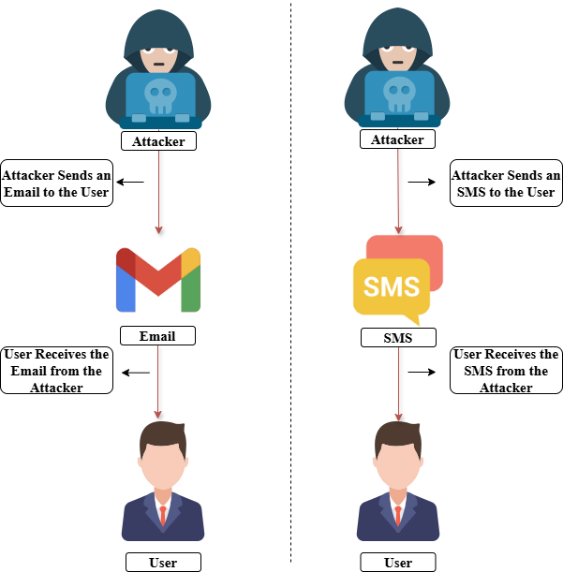
The widespread use of mobile communication in modern time has unintentionally made room for SMS phishing, often known as “smishing”, which is a deceitful tactic of scammers where they send fake messages to obtain confidential data from unaware victims [1] just as shown in figure 1. Smishing aims to obtain confidential data like bank card numbers, login credentials, or account details and if a victim becomes the target of this assault, it could result in a loss of money, stolen identity, and the access of private data without authorization [2]. Considering this, it is obvious that sophisticated detecting techniques are necessary. Because of the efficiency of implementing cutting edge technology to improve security, safeguarding users against smishing attacks has been crucial [3]. The capability of AI and machine learning techniques to distinguish between authentic and fake messages in a huge number of datasets makes them a useful method for helping to stop the increasing danger of smishing attempts [4, 5]. This article will discuss the usefulness of machine learning against the constantly evolving smishing attacks with the help of its classification algorithm.
How Classification Algorithm Detects Smishing
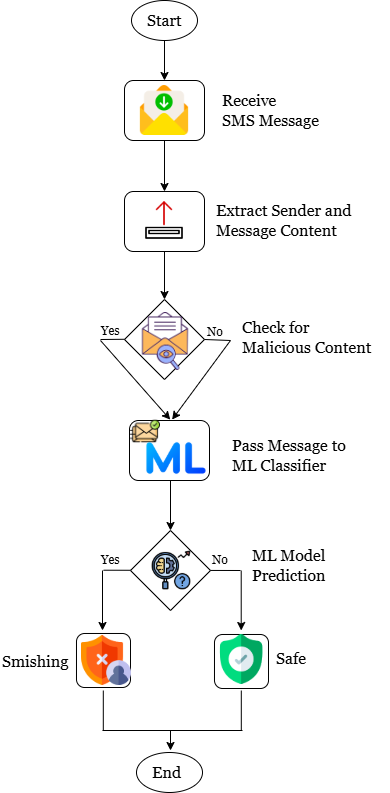
Machine Learning (ML) offers a straightforward and efficient method for analyzing data, its primary advantage is its capability to create flexible models for particular tasks such as detecting smishing attacks and since smishing presents as a categorization issue, ML models could serve as a helpful tool to solve this problem [6]. The following are the common ML algorithms used to detect smishing attacks.
Naïve Bayes: By presuming that characteristics are distinct from class, the Naive Bayes classifier facilitates learning easier, since certain generally operational features requirements are efficiently served by it. As anticipated, this classifier performs exceptionally well under two entirely independent feature conditions and performs surprisingly well in functionally related features [7].
Logistic regression: Logistic regression is utilized to allocate information within a set of separate categories, unlike linear regression, which yields constant quantity of values, LR uses the logistic sigmoid function to convert its output into probability values that could potentially translate to multiple distinct groups [8].
Random Forest: Multiple varieties of decision trees are combined by the Random Forest algorithm to produce the result. The type of tree that had been accurately predicted within the current situation represents the result, and every one of the trees provides an explanation for the class prediction [9]. Several additional trees are going to correct the final prediction, guaranteeing that the whole pattern of the trees is true, even though it is possible that certain trees might have predicted the incorrect outcome [10].
Key Steps in Building Smishing Detection Model
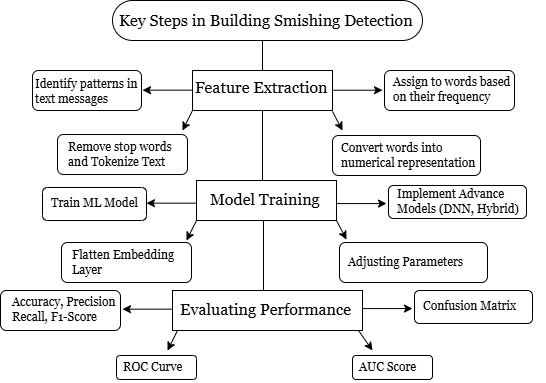
To have an accurate and reliable smishing detection using machine learning classifiers, key steps in building needs to be prioritized, this includes feature extraction, model training, and evaluation of model performance.
Feature Extraction: For improved categorization, feature extraction out of SMS data are essential [4]. Most methods start with textual content feature extraction and then move on to machine learning or deep learning classification. Although feature generation offers organizational findings, the possibilities of the dataset might not be completely realized [11]. A most common feature extraction technique is the Term Frequency-Inverse Document Frequency (TF-IDF) to determine how much weight each word in a text message should have. It is frequently utilized to assess the significance of words in documents in text analysis along with data extraction [12].
Model Training: Training the model is one of the important parts in building a detection model, in this way you will teach your system to learn from the data you feed it into. A great example for the scenario of the training process, is a basic neural network is trained, followed by the implementation of a dense layer, flattening of the embedding layer, and training [2].
Evaluating Model Performance: Evaluation the model performance serves the purpose to efficiently detect and classify fraudulent messages. In the context of ML algorithms, the most common evaluation metrics utilized are the Accuracy, confusion matrix, ROC, and AUC. Accuracy is a measurement parameter used to assess how well various machine learning models performed [3]. Because it offers comprehensive information regarding the efficiency of the model, the confusion matrix is essential to the evaluation of classification models. True positives, true negatives, false positives, and false negatives are the four classifications into which it separates the model’s predictions and actual results [4]. The other two is the utilization of ROC and AUC which are the couple of practical techniques for measuring the model performance, in ROC the curve should ideally be closest to the upper left corner of the graph and in the AUC is a crucial indicator of classifier efficacy [5].
Imbalance Dataset in Smishing Detection with Machine Learning
Development of a robust security system related to smishing is not an easy task, it has a lot of challenges that needs to be solved as it plays a crucial role in the performance of the model. One of the most crucial parts is the acquisition of the dataset as this is where the model will train from. There are a number of publicly available dataset, but it has the common issue, this is the dataset imbalance. This has been mentioned a lot by numerous researchers conducting studies in this field just like [1] and [2], which was later solved by using a balancing technique. A balanced dataset is necessary for training ML models, particularly when classes distribution is not equal. The most popular method used in research studies to accomplish dataset balance is Random Oversampling (ROS), involving randomly copying samples from the minority class to match the total number of the majority class [11].
Conclusion
The increasing threat of smishing remains an important matter as they can steal sensitive data from the victim. ML algorithms such as Logistic Regression, Naive Bayes, and Random Forest can effectively detect fraudulent messages, together with the key process in developing the model like feature extraction, model training, and evaluation metrics. However, inevitable challenges like dataset imbalance are present requiring techniques like random oversampling to solve the issue. The emergence of ML model has been the spotlight in effectively mitigating smishing attacks, by utilizing it effectively it can help in improving mobile security.
References
- Saidat, M. R. A., Yerima, S. Y., & Shaalan, K. (2024). Advancements of SMS Spam Detection: A Comprehensive survey of NLP and ML techniques. Procedia Computer Science, 244, 248–259. https://doi.org/10.1016/j.procs.2024.10.198
- Kohilan, R., Warakagoda, H. E., Kitulgoda, T. T., Skandhakumar, N., & Kuruwitaarachchi, N. (2023, November). A Machine Learning-based Approach for Detecting Smishing Attacks at End-user Level. In 2023 IEEE International Conference on e-Business Engineering (ICEBE) (pp. 149-154). IEEE.
- Kumarasiri, W. L. T. T. N., Siriwardhana, M. K. J. C., Suraweera, S. A. D. S. L., Senarathne, A. N., & Harshanath, S. M. B. (2023, October). Cybersmish: A Proactive Approach for Smishing Detection and Prevention using Machine Learning. In 2023 7th International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC) (pp. 210-217). IEEE.
- Samad, S. R. A., Ganesan, P., Rajasekaran, J., Radhakrishnan, M., Ammaippan, H., & Ramamurthy, V. (2023). SmishGuard: Leveraging Machine Learning and Natural Language Processing for Smishing Detection. International Journal of Advanced Computer Science & Applications, 14(11).
- Rahaman, M., Pappachan, P., Orozco, S. M., Bansal, S., & Arya, V. (2024). AI Safety and Security. In Challenges in Large Language Model Development and AI Ethics (pp. 354-383). IGI Global.
- Patra, C., Giri, D., Obaidat, M. S., & Maitra, T. (2023). SMSDECT: A prediction model for smishing attack detection using machine learning and text analysis. GLOBECOM 2022 – 2022 IEEE Global Communications Conference, 3837–3842. https://doi.org/10.1109/globecom54140.2023.10437712
- Rish, Irina. “An empirical study of the naive Bayes classifier.” IJCAI 2001 workshop on empirical methods in artificial intelligence. Vol. 3. No. 22. 2001.
- Hosmer Jr, David W., Stanley Lemeshow, and Rodney X. Sturdivant. Applied logistic regression. John Wiley & Sons, 2013.
- Vajrobol, V., Saxena, G. J., Pundir, A., Singh, S., B. Gupta, B., Gaurav, A., & Rahaman, M. (2024). Identify spoofing attacks in Internet of Things (IoT) environments using machine learning algorithms. Journal of High Speed Networks, 09266801241295886.
- Tin Kam Ho. Random decision forests. In Proceedings of 3rd International Conference on Document Analysis and Recognition, volume 1, pages 278–282, Montreal, QC, Canada, 1995.
- Samad, S. R. A., Ganesan, P., Thangam, S., Balasubramaniyan, S., Rajiakodi, S., & Al Kaabi, A. S. R. (2024, May). SMS-Shield: A Lightweight Approach for Smishing Detection using Machine Learning. In 2024 1st International Conference on Innovative Engineering Sciences and Technological Research (ICIESTR) (pp. 1-6). IEEE.
- Chen, S. S., Sun, C. Y., & Pai, T. W. (2023, July). Using machine learning for efficient smishing detection. In 2023 International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan) (pp. 207-208). IEEE.
- Xu, M., Peng, J., Gupta, B. B., Kang, J., Xiong, Z., Li, Z., & Abd El-Latif, A. A. (2021). Multiagent federated reinforcement learning for secure incentive mechanism in intelligent cyber–physical systems. IEEE Internet of Things Journal, 9(22), 22095-22108.
- Mirsadeghi, F., Rafsanjani, M. K., & Gupta, B. B. (2021). A trust infrastructure based authentication method for clustered vehicular ad hoc networks. Peer-to-Peer Networking and Applications, 14, 2537-2553.
- Gaurav A. (2023) Cybersecurity in the Smart Grid: Detecting and Mitigating DDoS Attacks, Insights2Techinfo, pp.1
Cite As
Cajes N. (2025) DDoS Resilience: Building a Safer Digital Landscape with Hybrid Deep Learning, Insights2Techinfo, pp.1