By: Abhay Ratnaparkhi
A few weeks ago (February 7th, 2023), Microsoft announced their new AI-powered Bing search engine [1]. In the announcement, Microsoft’s Chairman and CEO stated that “AI will fundamentally change every software category, starting with the largest category of all — search.” While the use of AI techniques in the field of search and information retrieval is not new, it is becoming increasingly apparent that AI-powered models are dominating over traditional search approaches.
In this blog post, I will provide an overview of the evolution of technology in the text-based search systems field.
Lexical search / Sparse Lexical Retrieval:
One of the early methods for information retrieval is the Sparse Lexical Retrieval or Lexical Search. This approach involves creating an inverted index from the corpus, which maps terms to the documents in which they appear. The figure below illustrates the components of a typical lexical search engine.
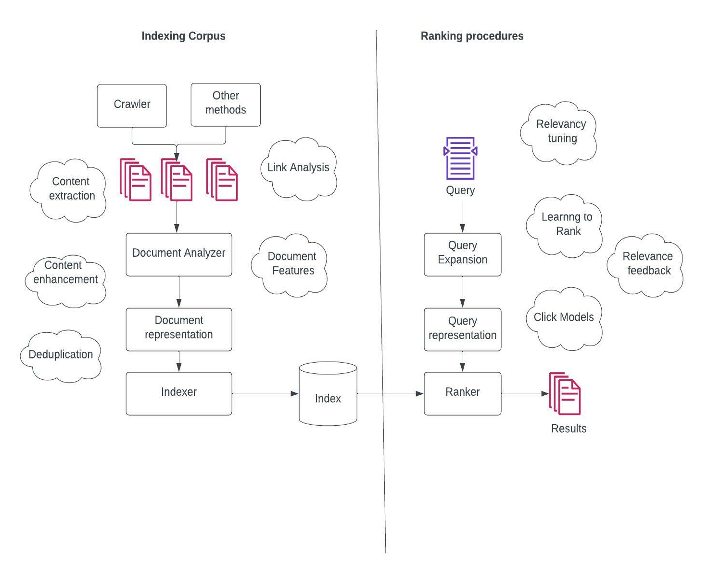
To prepare documents for retrieval, they need to be analyzed and converted into a suitable format. The resulting index contains a posting list, which points from each term to the list of documents where the term appears. The indexing process may also include configurable steps such as stemming, lemmatization, stop word removal, and synonym expansions. More details about the Lucene inverted index can be found here [2].
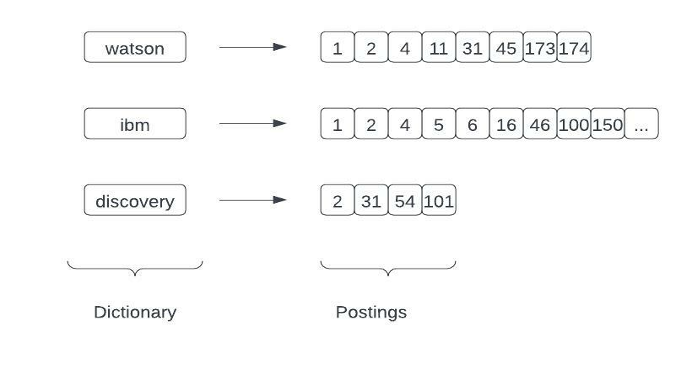
In this approach, documents are represented as Bag of Words (BOW) representations, and ranking functions like TF-IDF, Okapi BM25 [3], etc. are used to rank search results. Decades of research have gone into optimizing retrieval for sparse vectors, which are vectors with a dimension equal to the number of terms in the vocabulary. As a result, lexical search engines are highly efficient at retrieving search results. Many open-source indexing and search solutions like Lucene, Solr, ElasticSearch, Open Search, etc. use BM25 as the default ranking function, which is still one of the strongest baselines.
However, a significant drawback of the lexical search approach is that it fails to retrieve results when there is a vocabulary mismatch
Lexical search with Learning to Rank (LTR):
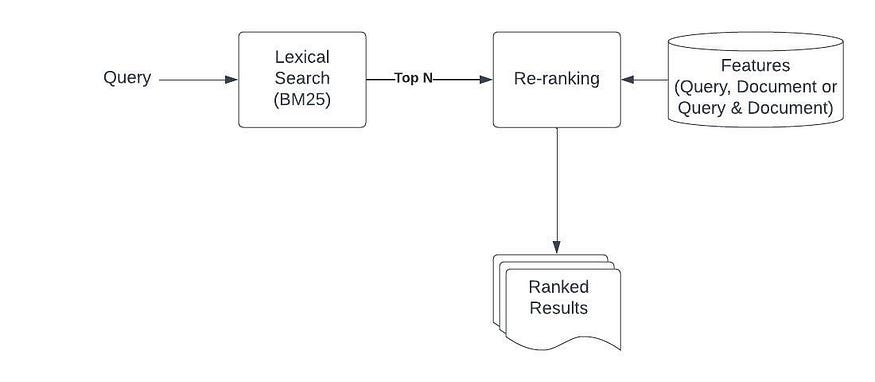
Learning to Rank (LTR) [4] methods are a class of algorithmic techniques that use supervised machine learning to solve ranking problems in search relevancy. In LTR, relevancy judgments about how relevant a document is to a given query are used as ground truth during the model training. These judgments can either be created by experts or generated by analyzing click logs using click models [5].
Compared to probabilistic TF-IDF or BM25-based ranking, LTR methods are more time-consuming, and therefore they are typically used to re-rank the top N documents. The features related to the query, documents, and the interaction between the query and document are used for supervised training. Several supervised methods, such as point-wise, pair-wise, and list-wise, are available for re-ranking documents.
Semantic Search / Dense Retrieval
Neural networks have been widely utilized for information retrieval tasks, giving rise to the field of neural information retrieval[6][7]. One popular neural architecture for this purpose is the transformer, which can be pre-trained on large corpora and fine-tuned for specific tasks. There were other neural network based architecture like using Convolutional Neural Networks (CNNs) used in the past but current state of the art is based on transformer based models. Transformer models operate on a sequence of text, with the encoder generating an abstract representation (token embeddings) for each token in the input sequence. The decoder then produces new tokens based on both the partially generated token and the encoder’s output. The self-attention mechanism used in transformer architectures allows for encoding the context of other terms in the sequence into the generated abstract representation.
Models such as BERT generate word-level embeddings (token embeddings) for input sequences, as depicted in the figure below.
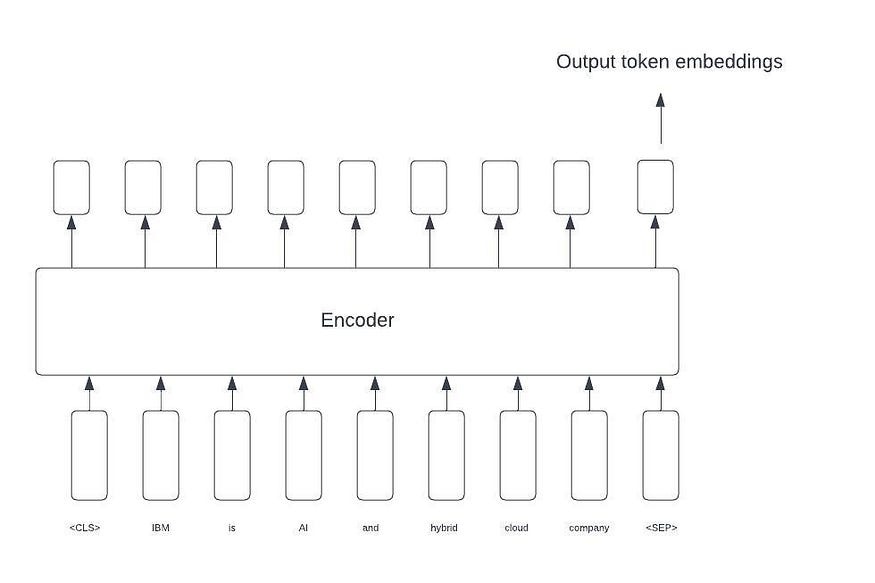
The neural representation generates a lower-dimensional embedding vector (in the case of DistillBERT, a 768-dimensional vector) for each input token.
There exist two distinct architectural approaches for utilizing this neural representation to rank documents in response to a given query. The Survey here [8] gives detailed comparisions of these architectures.
- Representation focused (Bi-Encoder) :
The focus of this architecture is on using neural networks, such as encoders, to obtain query/document representations. The obtained representations (embedding vectors) are then matched using distance measures such as cosine similarity or dot product to generate a score. One way to obtain the document or query embedding using an encoder is to obtain embeddings for each input token in a query or document, and then calculate the average embeddings. Another approach is to obtain the embeddings for the start of the sentence token (<CLS>).
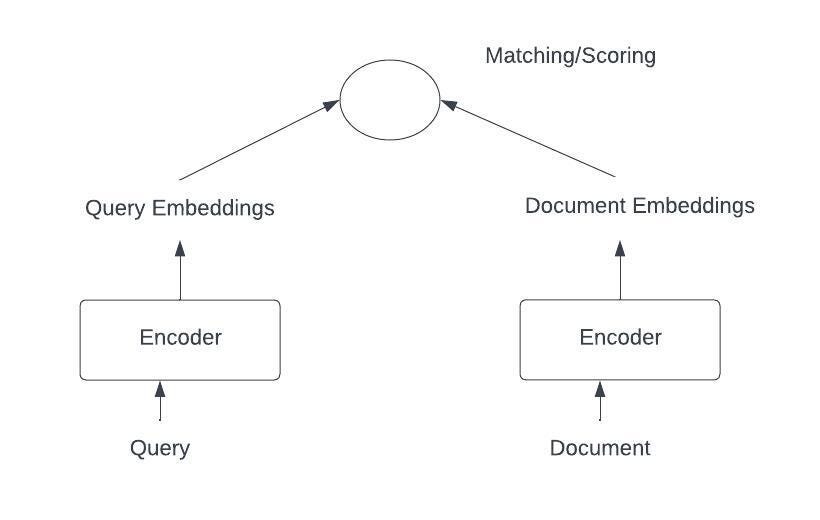
However, the problem with these embeddings is that they are token-level embeddings and not sentence/document-level embeddings. Averaging techniques do not work well in practice. Sentence Transformers (e.g., Sentence-BERT) [9] address this issue by generating suitable embeddings for slightly longer text (limited by the size of the encoder model being used, e.g., 512 WordPiece tokens for BERT large). The sentence transformers use a siamese network architecture to fine-tune a pre-trained encoder model, such as BERT. They use a labeled corpus of relevant sentences (or query/document texts) to train a feedforward network that classifies whether two sentences match each other. The output embeddings generated in this way are suitable for comparing different sentences (or query and documents).
One advantage of representation-focused architectures is that the document embeddings can be pre-computed and stored in vector databases for future retrieval. At runtime, the query vector is calculated using a similar model, and the distance is calculated with the vector of every available document in the corpus. The results are ranked by similarity (shortest distance).
However, this nearest neighbor search is not scalable for a large number of documents. Approximate nearest neighbor (ANN) search algorithms help solve this issue by sacrificing accuracy for latency. Multiple ANN indexing methods have been proposed, and their implementations are available in vector search engines like FAISS, Milvus and Waviate. As BERT can only take 512 WordPiece tokens as input, it may not be suitable for generating document embeddings for longer documents using S-BERT. One option is to use larger models that work on longer input sequences. Another option is to divide the document into paragraphs and average paragraph-level embeddings. In practice, documents are represented by facets such as title, description, content, etc., and embeddings can be generated individually or jointly (by combining to one field) for these.
2. Interaction focused (Cross-Encoder):
The neural architecture of cross-encoders works on sequences as well. However, it focuses on using a joint representation of the query and document. In this method, the query and document are combined into a single sequence, which is then passed to the encoder. A feed forward neural network layer is used to obtain the matching probability between the query and document. The pre-trained encoder can be fine-tuned with labeled query-document pairs.
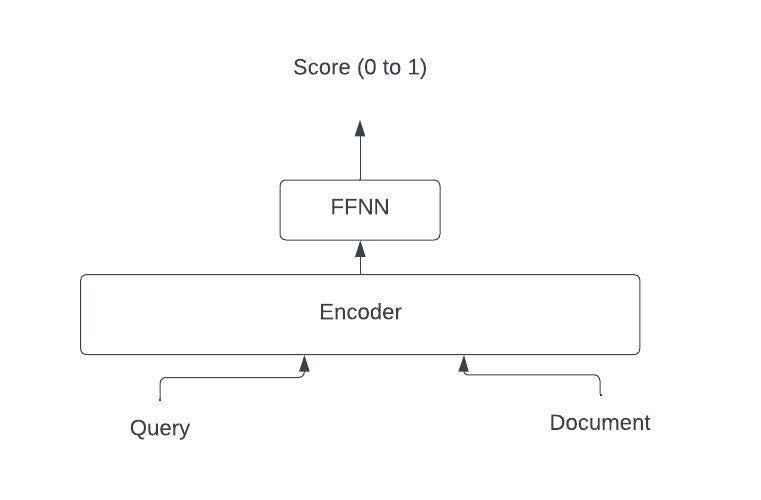
The joint query-document representation generated by cross-encoders provides more accurate results than representation-focused systems. However, cross-encoders come with a large runtime overhead as the similarity score needs to be calculated for every query-document pair at runtime. Hence, these models are typically used in the re-ranking phase with a small number of documents.
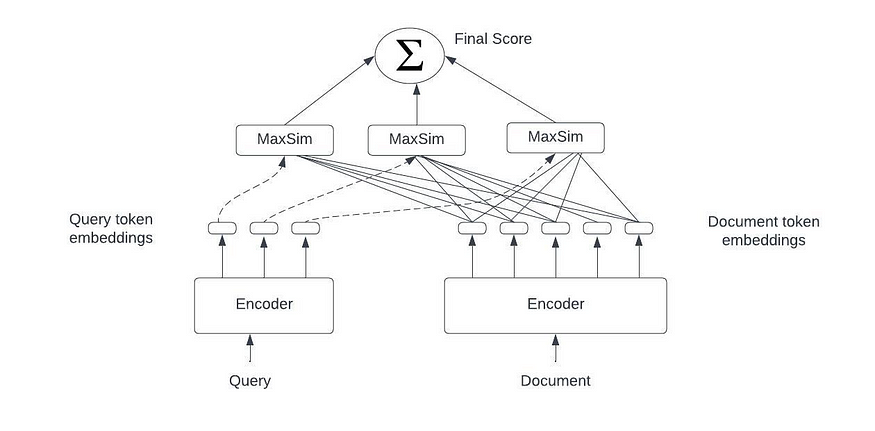
3. Late interaction retrieval models:
The idea here is to use the token embeddings generated by encoders like BERT and store those token level vectors for a document. So rather than representing a document as one vector (as done by sentence transformers) the document is represented by a list of vectors with a vector for each token. The document vector lists can be calculated at the index time and can be stored in efficient vector storage for later retrieval. The query tokens are encoded at runtime into the token level vectors and scoring is conducted via scalable yet fine-grained interactions at the level of tokens.
The models like ColBERT[10] uses this late interaction retrieval approach.
To compare different dense embedding techniques a Massive Text Embedding Benchmark (MTEB) [11] has been introduced which spans multiple tasks and uses many dataset to evaluate dense embedding approaches.
Hybrid Search
Lexical and semantic matching approaches can be combined to produce more accurate search results.
One simple method to achieve this is to compute a weighted average of dense and sparse retrieval scores, and use this score to rank the search results. Elasticsearch 9.x provides a straightforward implementation of this approach [12].
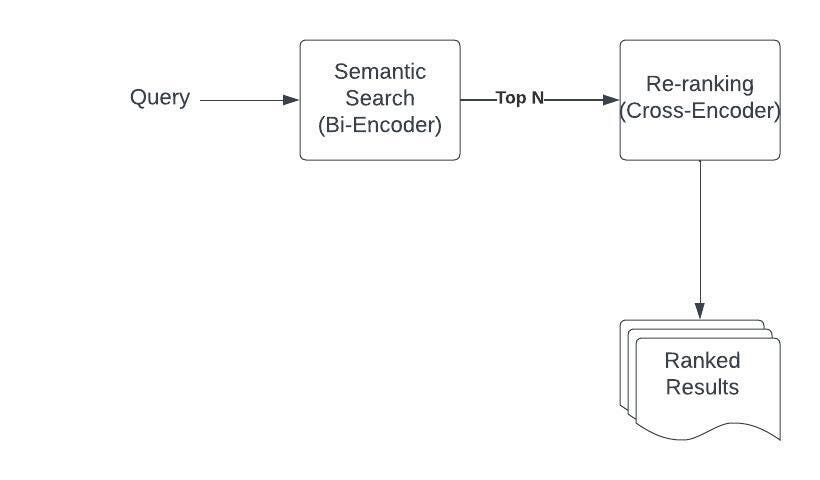
Another method involves training a reranker with multiple features in a supervised re-ranking phase [13]. However, a challenge with this approach is that some features may be disjoint between lexical and semantic results. For example, the distance metric may not be available for a lexical result that was not retrieved from semantic search. To address this issue, search results can be interleaved to generate click logs, which can be used to train the reranking model.
The pre-trained cross-encoder model can also be fine-tuned with data and used in the reranking phase.
Another approach, used in Picode’s implementation involves creating sparse-dense embeddings [14] by concatenating dense and sparse vectors, and using dot product metrics to calculate scores.
A more recent approach [15] involves integrating lexical representations with dense semantic representations by transforming high-dimensional lexical representations into low-dimensional dense lexical representations (DLRs). The nearest neighbor search is then performed over the combined dense vectors from dense embeddings and DLRs generated from lexical sparse representation.
Learned Sparse Representations:
These models aim to improve the representation capacity of traditional lexical models by generating a sparse representation of the input text in the full vocabulary space or the model vocabulary space (e.g., 30,522 for BERT WordPiece tokens) using information from pre-trained language models.
The models in this category either modify term weighing component (like DeepCT) or they enhance term expansion (doc2query–T5) or they do both (SPLADE).
The model like SPLADE [16] [17] [18] [19] [20] (Sparse Lexical and Expansion Model) uses a Masked Language Model (MLM) head to output probabilities distribution over the vocabulary.
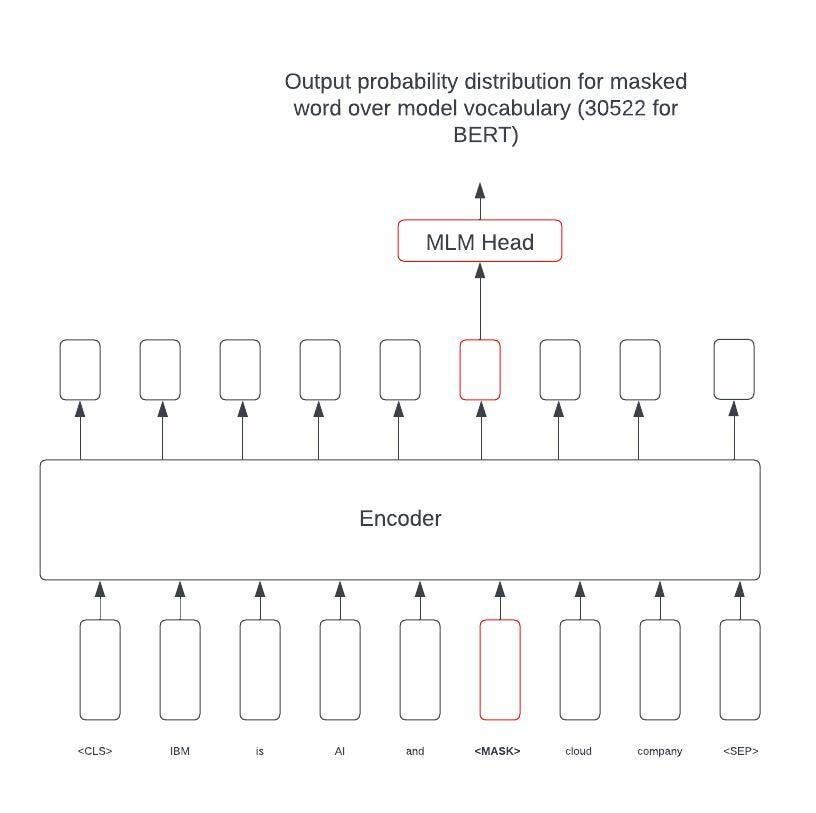
The probabilities for each input token are then aggregated to get the importance estimation vector. This gives a sparse vector of the model vocabulary size. As MLM head probability distribution involves probabilities with in-context words, the final importance estimation vector has expanded terms in it, This helps resolving the vocabulary mismatch problem of lexical sparse vectors like BM25. The existing indexing and optimization techniques can be applied to generated sparse vectors making them as efficient as lexical models.
The BEIR benchmarks [21] provides heterogeneous benchmark for diverse IR tasks. As of this writing BM25+SPLADE topped as overall raking across diverse set of tasks.
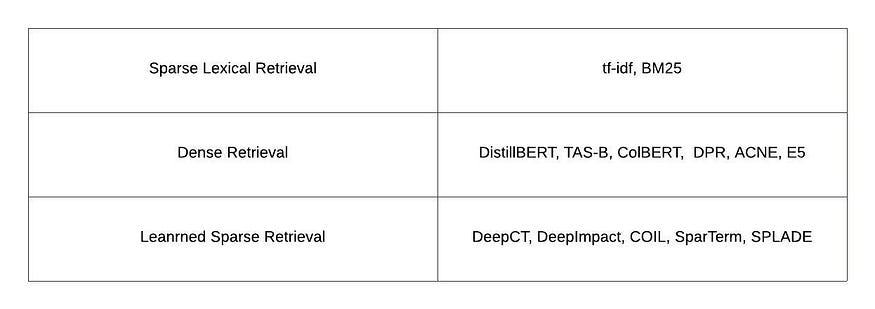
The table below shows example implementations of retrieval models.
In essence, the development of search technology has been motivated by the aim to furnish users with precise, and relevant results. With technology progressing rapidly, it is probable that we will encounter further breakthroughs in search, thereby enhancing its capability as a tool to obtain information and interact with the world.
Note: Although I attempted to provide an overview and include most of the methods in neural information retrieval, this list is not exhaustive.
References:
- The Official Microsoft Blog. “Reinventing Search with a New AI-Powered Microsoft Bing and Edge, Your Copilot for the Web,” February 7, 2023. https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/.
- “Apache Lucene — Index File Formats.” Accessed March 8, 2023. https://lucene.apache.org/core/3_0_3/fileformats.html.
- Seitz, Rudi. “Understanding TF-IDF and BM-25.” KMW Technology (blog), March 20, 2020. https://kmwllc.com/index.php/2020/03/20/understanding-tf-idf-and-bm-25/.
- Liu, Tie-Yan. “Learning to Rank for Information Retrieval.” Foundations and Trends® in Information Retrieval 3, no. 3 (2007): 225–331. https://doi.org/10.1561/1500000016.
- Chuklin, Aleksandr. “Click Models for Web Search”
- Mitra, Bhaskar, and Nick Craswell. “An Introduction to Neural Information Retrieval,” n.d.
- Tonellotto, Nicola. “Lecture Notes on Neural Information Retrieval.” arXiv, September 12, 2022. http://arxiv.org/abs/2207.13443.
- Zhao, Wayne Xin, Jing Liu, Ruiyang Ren, and Ji-Rong Wen. “Dense Text Retrieval Based on Pretrained Language Models: A Survey.” arXiv, November 27, 2022. http://arxiv.org/abs/2211.14876.
- Pinecone. “Sentence Transformers: Meanings in Disguise.” Accessed March 8, 2023. https://www.pinecone.io/learn/sentence-embeddings/.
- Khattab, Omar, and Matei Zaharia. “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.” arXiv, June 4, 2020. http://arxiv.org/abs/2004.12832.
- Muennighoff, Niklas, Nouamane Tazi, Loïc Magne, and Nils Reimers. “MTEB: Massive Text Embedding Benchmark.” arXiv, February 5, 2023. http://arxiv.org/abs/2210.07316.
- Schwartz, Noam. “‘Text Search vs. Vector Search: Better Together?’” Medium, February 28, 2023. https://towardsdatascience.com/text-search-vs-vector-search-better-together-3bd48eb6132a.
- Pinecone. “Hybrid Search and Learning-to-Rank with Metarank.” Accessed March 8, 2023. https://www.pinecone.io/learn/metarank/.
- Pinecone.”Sparse-dense embeddings” Accessed March 8, 2023. https://docs.pinecone.io/docs/hybrid-search
- S.Lin, J.Lin “A Dense Representation Framework for Lexical and Semantic Matching”, arXiv, Feb 2023. https://arxiv.org/pdf/2206.09912.pdf
- Bai, Yang, Xiaoguang Li, Gang Wang, Chaoliang Zhang, Lifeng Shang, Jun Xu, Zhaowei Wang, Fangshan Wang, and Qun Liu. “SparTerm: Learning Term-Based Sparse Representation for Fast Text Retrieval.” arXiv, October 1, 2020. http://arxiv.org/abs/2010.00768.
- Lin, Jimmy, and Xueguang Ma. “A Few Brief Notes on DeepImpact, COIL, and a Conceptual Framework for Information Retrieval Techniques.” arXiv, June 28, 2021. http://arxiv.org/abs/2106.14807.
- T. Formal, B. Piwowarski, S. Clinchant, SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking (2021), SIGIR 21
- T. Formal, C. Lassance, B. Piwowarski, S. Clinchant, SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval (2021)
- Pinecone. “SPLADE for Sparse Vector Search Explained.” Accessed March 8, 2023. https://www.pinecone.io/learn/splade/
- Thakur, Nandan, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. “BEIR: A Heterogenous Benchmark for Zero-Shot Evaluation of Information Retrieval Models.” arXiv, October 20, 2021. http://arxiv.org/abs/2104.08663.
Cite As:
A Ratnaparkhi(2023), Evolution of Search Technology: A Look Ahead, Insights2Techinfo, pp. 1