By: C S Nakul Kalyan; Asia University
Abstract
In the world of advanced digital technology, Meme culture and satirical Deep- fakes are a unique combination that can be used for fun and they contain potential harm. While memes can be used as a creative tool to express our feelings and for entertainment purposes, their nature of having a combination of text, images, and satire makes it difficult to detect the harmful and offensive content that is being circulated as a meme. Recent research states that Large Language Models (LLMs) will be used to detect the emotions in memes, and Multi-modal fusion that contains image and text features will be used to improve the classification accuracy, and the sentiment analysis will be used to detect the unwanted and offensive textual content. By building a model for these approaches, this study proposes a combined framework for detecting satirical deepfakes and un- wanted memes to balance the humor and responsible content generation for meme purposes.
Keywords
Meme Culture, Satirical Deepfakes, Large Language Models (LLMs), Multi- Modal learning, Artificial Intelligence (AI).
Introduction
In recent days, memes have been emerging as an important form of online com- munication, where they provide information that is a combination of text and image, which is used to convey satire and comments [5]. Apart from the en- tertainment purposes, the memes and the Satirical Deepfakes poses a major concern of spreading offensive content, spreading misinformation, or spreading any fake news as a meme [3]. Their nature of having a combination of im- ages and texts will create a problem for automated models to detect whether they are offensive or not. LLMs can recognize the emotions in the meme con- tent [6], such as difficulties, such as irony, puns, and sarcasm. Additionally, combining methods such as OCR, Convolutional Neural Networks (CNNs), and sentiment analysis tools such as VADER can detect the harmful textual con- tents [3]. In this article we will go through the combined developments of the above-mentioned techniques, and we will go through how the meme culture and Satirical Deepfakes creation affect the digital media [1].
Proposed Methodology
To study the combination of meme culture, satirical deepfakes, and their potential to harm others, a multimodal methodology is proposed to detect the offensive meme content as follows [1]. The complete processing workflow pipeline is provided in Figure 1 below:
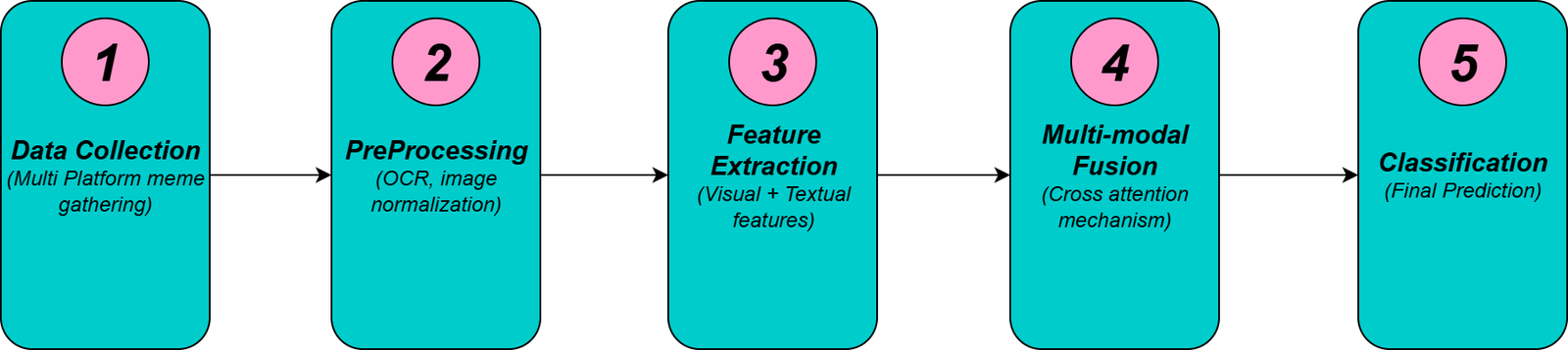
Dataset construction and Collection
Meme Sources
The datasets for memes have been collected from social media platforms such as Instagram, twitter, Facebook, WhatsApp, Weibo, ImgFlip. These datasets have all kinds of data, such as meme genres, political satire, cultural humor, and offensive deepfake-based meme content.
Annotation Process
The Human analysts label the memes based on :
Emotion:
The Emotions can be Positive, Negative, and neutral [6].
Humor/Satire Type:
The humor Satire type can be of Sarcasm, irony, dark humor, etc.
Offensiveness:
The offensiveness-based annotations can be done by the offensive and harmful meme content [3].
Image Feature Extraction
CNN-based Visual Models
In the CNN-based models, the feature extraction is done by the pre-trained models, such as VGG-16, ResNet, and Vision Transformers have been used to extract the visual features of the meme, such as faces, symbols, and deep-fake content [2].
Deepfake Detection Signals
It focuses on the mismatches in face-swap memes, or mismatched lightning, to find the manipulated satire-based Deepfakes.
OCR Integration
The Optical Character Recognition (OCR) will be used to extract the face captions, where it will capture both the text and images concurrently [3].
Textual Feature Extraction
Transformer-Based NLP Models
To analyze the meme captions, overlay texts, and grouped conversations, the NLP models such as BERT and ROBERTa have been used [1].
Sentiment Analysis
To detect the sentiment in short memes, the VADER algorithm is used, which can easily detect the sentiment [3].
Semantic and Cultural Markers
The semantic and cultural markers will be focused on the slang, references, and cultural idioms such as puns in Chinese or Western Satire [4].
Multi-modal Fusion Approaches
Early Fusion
In the early fusion, the extracted image and textual embeddings will be combined at the feature level, before the categorization process, which will allow us to make deeper cross-modal interactions [1].
Late Fusion
The late fusion will independently process the image and the text, where it merges the classification outputs at a decision level. This will be useful to detect the differences when the modalities differ in intensity or clarity [1].
Cross-Modal Attention
Advanced modals such as Qwen2.5 and CLIP-like architectures use attention mechanisms to align the cultural humor cues across various modalities.
Classification and Detection Framework
Emotion and Humor Classification
To identify the humor types (such as satire, sarcasm, and dark humor) and sentiment polarity, an LLM-based multi-model has been used [6].
Offensive and Harmful Content Detection
This content detection will use a binary or multiclass classifier to segregate the memes as harmless, offensive, or harmful ones [3].
Deepfake-Specific Detection
Here, the Classifiers will be used to detect the small alterations in facial memes, in which they will differentiate between harmless and deepfake content memes.
Evaluation Metrics
Standard Metrices
The Standard evaluation metric will evaluate and produce the accuracy, precision, recall, and F1 Score [1].
Content Specific metrices
The content-specific evaluation metrices will provide a detection and classification rate, such as:
Cultural Mis-classification Rate:
The Cultural Mis-classification Rate will be used to produce the errors caused by the failure to recognize the culturally embedded humor [4].
Satire Detection Rate:
The Satire Detection rate will be used to produce the success rates in differentiating the Satire from the Direct offense. The Experimental results of the proposed Model across all the metrics compared to baseline approaches are given is below Figure 2.
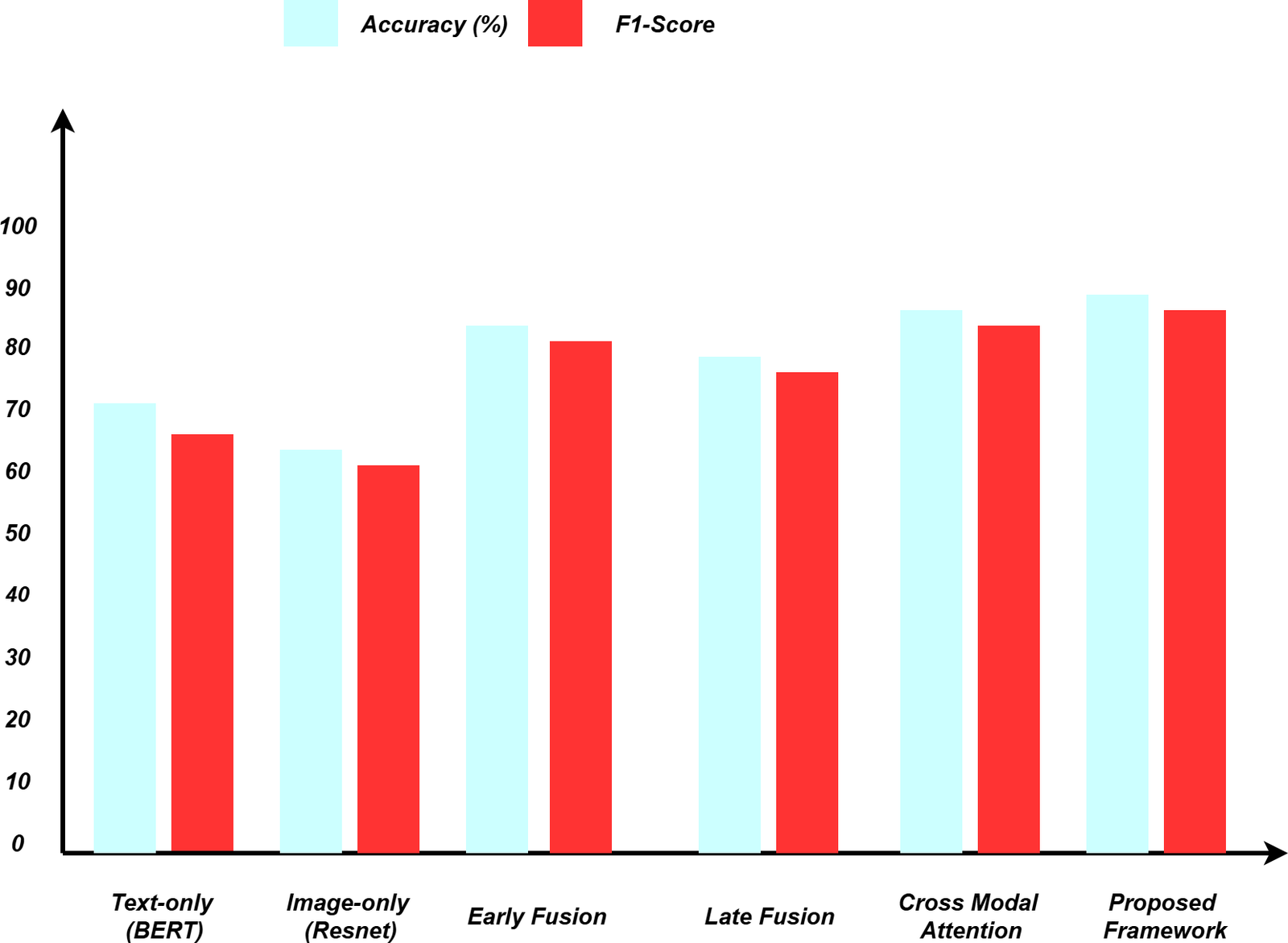
Cross Linguistic comparisons
The Cross-Linguistic Comparisons will be used to evaluate the performance of the memes with various languages to test the robustness across contexts [4]. The performance comparisons of different tables have been shown in Table 1 below:
Table 1: Deep Learning Modal Architecture and Performance
Approach | Accuracy | Precision | Recall | F1-Score | Offensive Detection Rate |
Text-only (BERT) | 72.4 | 71.8 | 69.3 | 70.5 | 68.2 |
Image-only (ResNet) | 68.9 | 67.2 | 65.8 | 66.5 | 63.4 |
Early Fusion | 84.2 | 83.7 | 81.9 | 82.8 | 79.6 |
Late fusion | 81.6 | 80.9 | 79.4 | 80.1 | 77.3 |
Cross-Modal Attention | 87.3 | 86.8 | 85.2 | 86.0 | 83.7 |
Proposed Framework | 89.1 | 88.4 | 87.6 | 88.0 | 85.9 |
Conclusion
The Meme culture and Satirical Deepfakes represent the dual nature of digital creativity, where humor promotes cultural engagement and as well as it can create offense, misinformation, and social harm. This study shows that Large Language Models (LLMs) can detect the meme emotion by capturing simple comedy. The multi-modal combination of image and text will be used to detect the classification accuracy, and the sentiment analysis can be used to detect the offensive content. By combining these approaches, we can see the importance of adaptable, multimodal frameworks that can be capable of detecting against the emerging complexity of memes and deepfakes. To make sure that the digital hu- mour continues to function without getting negative impacts, it will be essential to combine these techniques and use them against the Satirical deepfakes.
References
- Stephanie Han, Sebastian Leal-Arenas, Eftim Zdravevski, Charles C Caval- cante, Zois Boukouvalas, and Roberto Corizzo. Multimodal deep learning for online meme classification. In 2024 IEEE International Conference on Big Data (BigData), pages 3273–3276. IEEE, 2024.
- Lamia Iftekhar, Mirza Sarwar Kamal, and Mehrab Hossain Likhon. Memes- in-the-loop: Utilizing digital culture humour to engage students in under- graduate control engineering course. In 2024 IEEE International Conference on Teaching, Assessment and Learning for Engineering (TALE), pages 1–8. IEEE, 2024.
- R Kiruthika, G Santhosh, R Santhosh, SB Surya, and K Thamizh Amudhan. Ai-powered system for detecting offensive meme texts on social media. In 2025 3rd International Conference on Artificial Intelligence and Machine Learning Applications Theme: Healthcare and Internet of Things (AIMLA), pages 1–5. IEEE, 2025.
- Maricarmen Patricia Rodriguez-Guillen, Ana Carolina Zavala-Parrales, and Gabriel Valerio-Uren˜a. Integrating memes: Enhancing education with pop culture a systematic literature review. In 2024 International Conference on Emerging eLearning Technologies and Applications (ICETA), pages 538–545. IEEE, 2024.
- Mira B Rotanova and Marina V Fedorova. Internet meme as the cyber laughter culture phenomenon in modern russian digital society. In 2019 Communication Strategies in Digital Society Workshop (ComSDS), pages 65–69. IEEE, 2019.
- Yizhou Xu and Riki Lin. Large language model based emotion recognition of memes. In 2025 International Conference on Sensor-Cloud and Edge Computing System (SCECS), pages 284–290. IEEE, 2025.
- Gupta, B. B., Gaurav, A., Arya, V., & Alhalabi, W. (2024). The evolution of intellectual property rights in metaverse based Industry 4.0 paradigms. International Entrepreneurship and Management Journal, 20(2), 1111-1126.
- Zhang, T., Zhang, Z., Zhao, K., Gupta, B. B., & Arya, V. (2023). A lightweight cross-domain authentication protocol for trusted access to industrial internet. International Journal on Semantic Web and Information Systems (IJSWIS), 19(1), 1-25.
- Jain, D. K., Eyre, Y. G. M., Kumar, A., Gupta, B. B., & Kotecha, K. (2024). Knowledge-based data processing for multilingual natural language analysis. ACM Transactions on Asian and Low-Resource Language Information Processing, 23(5), 1-16.
Cite As
Kalyan C S N (2025) Meme Culture and Satirical Deepfakes: Where Humor Meets Harm, Insights2Techinfo, pp.1