By: Mridul Sharma
![]() , Diksha Malhotra
, Diksha Malhotra
![]() , Poonam Saini
, Poonam Saini
![]()
Introduction
Scientific research is difficult, and it can be traumatic at times. To develop a state-of-the-art solution, it is necessary to conduct experiments and develop procedures. The literature review, however, is the most time-consuming aspect of the study. A solid research foundation on which a researcher can build and expand his ideas is provided by a comprehensive literature review. A terrible one can led to a detour in research. For the literature review, we only consider the most recent and up-to-date research; the number of relevant publications that the researchers must read is in the thousands. For scholars, this is a continuous difficulty. We now have a solution to this problem TLDR, thanks to AI (particularly NLP).
TLDR is a concise summary of a work that is generated automatically. It stands for “Too Long; Didn’t Read”. In this context, a subtype of text summarization, i.e., extreme summarization which deals with shortening of whole document into single sentence can be exploited. The advanced NLP techniques use deep learning-based models such as transformers for automatic abstractive summarization. This document introduces the reader to extreme text summarization and pre-trained models for abstractive text summarization. Hence, a reader can utilize the knowledge gained for developing abstractive summarization modules.
What is Text Summarization?
Automatic text summarization is a technique which shortens lengthy texts and provides summaries to convey the desired content. It’s a widespread challenge in natural language processing (NLP) and machine learning. The process of constructing a concise, cohesive, and fluent summary of a lengthier text document, which includes highlighting the text’s important points, is known as text summarization. Text summarising presents a number of issues, including text identification, interpretation, and summary generation, as well as analysis of the resulting summary. Identifying important phrases in the document and exploiting them to uncover relevant information to add in the summary are critical jobs in extraction-based summarising.
Type of summarization
- Extractive summarization: The extractive text summarization technique entails extracting essential words from a source document and combining them to create a summary. Without making any changes to the texts, the extraction is done according to the defined measure.
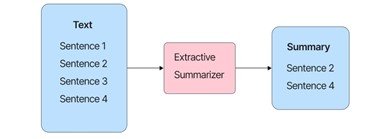
Abstractive summarization: Abstractive text summarization is the process of creating a short and concise summary of a source text that captures the main points. The generated summaries may include additional phrases and sentences not found in the original text. It mainly uses deep learning-based techniques for generation of summaries. Here, the sentences generated may or may not be accurate.

Scientific TLDR (SciTLDR) Dataset
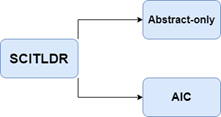
In order to understand extreme summarization, its beneficial to first understand the dataset which can be used. The researchers at the Allen Institute for AI wanted a dataset that met their needs in order to execute extreme summarization. Hence, they created SciTLDR, a dataset containing 5,411 one-sentence summaries of 3,229 scientific papers. The researchers [1] collected more than one short summary for each manuscript to verify the performance of TLDR creation. The author of the paper penned one of the summaries. The other summary was based on peer-review comments and prepared by computer science students. Further, to generate a one-sentence summary, the TLDR model only looks at the abstract, introduction, and conclusion of a publication.
Pretrained models for abstractive summarization
A deep learning model that has already been trained on a generalised task is referred to as a pre-trained model. It is not necessary to train the model from scratch in order to use it for a downstream task. It can be fine-tuned on the downstream job instead. The current state-of-the-art pretrained models for abstractive extreme summarization are discussed in this section. Such models, it should be highlighted, are based on transformers.
T5 Transformer for Text Summarization
T5 transformer is a encoder decoder pre-trained model which takes input as text to provide text based output. It requires the task name to be applied at the beginning of the input to help the model identify the precise task to perform[10]. T5 model can be fined tuned for various downstream task such as customized summarization, question answering, machine translation etc. T5 model can be fine-tuned on SciTLDR for extreme abstractive summarization of long scientific articles.

BART Transformer for Text Summarization
BART [3] is a pretrained denoising autoencoder for sequence-to-sequence models. It is taught by corrupting text with a random noise function and learning a model to reconstruct the original text. It employs a conventional Transformer [5] design (Encoder-Decoder), which is comparable to the original Transformer model for neural machine translation, but differs from BERT (which only employs the encoder) and GPT (which employs both encoder and decoder) which only uses the decoder.

GPT-2 Transformer for Text Summarization
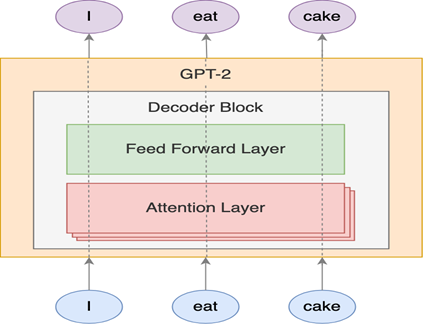
GPT-2 is made up entirely of transformer-style stacked decoder blocks. In the standard transformer architecture, the decoder receives a word embedding concatenated with a context vector, both generated by the encoder. The context vector in GPT-2 is zero-initialized for the first word embedding. In the traditional transformer architecture, self-attention is also applied to the entire surrounding context, including all of the other words in the sentence. Instead, in GPT-2, the decoder is only allowed to take information from the sentence’s earlier words, which is known as concealed self-attention. Aside from it, GPT-2 is a near-exact duplicate of the basic transformer architecture.
XLM Transformer for Text Summarization:
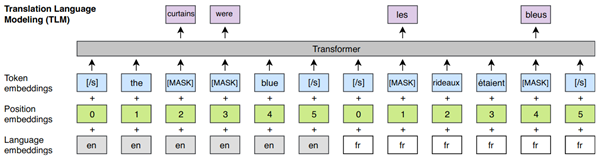
XLM uses a well-known pre-processing approach called Byte pair encoding (BPE) as well as a dual-language training mechanism called BERT to learn relationships between words in various languages. When a pre-trained model is utilised for initialization of the translation model, the model outperforms other models [6] in a cross-lingual classification challenge and enhances machine translation significantly.
The above explained pre trained transformer models can be fined tuned on SciTLDR for extreme abstractive summarization. The next section explains the concept fine-tuning.
Fine-tuning
Transfer learning and fine-tuning are indistinguishably intertwined. When we apply knowledge obtained from solving one problem to a new but related problem, we refer this transfer learning. Fine-tuning is a technique for putting transfer learning [2] into practice. It is a procedure that takes a model which has already been trained for larger task and tunes it to perform a downstream task that is similar to the first. By fine tuning the pre-trained summarization model on SciTLDR dataset long summaries generated by model can be compressed to a single line sentence which can give a lot of information clearly for scientific documents.
Different Fine-Tuning Techniques
- Train the complete architecture – On our dataset, we may train the complete pre-trained model and pass the results to a SoftMax layer. The error propagates throughout the architecture in this case, and the model’s pre-trained weights are updated to reflect the new dataset.
- Train some layers while freezing others – One more option is to partially train a pre-trained model. We can maintain the weights of the model’s early layers static while retraining only the upper levels. We can experiment with how many layers to freeze and how many to train.
- Freeze the complete architecture – We can even train a new model by freezing all of the model’s layers and attaching them with our own neural network layers. During model training, just the weights of the associated layers will be restructured.
The Hugging Face transformers [9] package is a well-known Python library that provides pre-trained models that can be used for a range of Natural Language Processing (NLP) purposes. It exclusively supports PyTorch and TensorFlow 2.
We can perform fine tuning on the SciTLDR dataset using Hugging Face transformers by:
- The HuggingFace not only has models, but it also has multiple datasets in a variety of languag s. To download and cache a dataset, use the Datasets library. The SciTLDR dataset is available for download. The training set, validation set, and test set are all contained in a dataset dictionary object. There are several columns (source, source_labels, paper_id, target, title) and a variable number of rows.
- To pre-process the dataset, we’ll use a tokenizer class present in transformers library to turn the text into numbers that the model can understand. We can provide a single sentence or a list of sentences to the tokenizer.
- The Trainer class in the Transformers library can be used to fine-tune any of the pre-trained models on your dataset. We just have to provide model name which we want to use for fine tuning.
- We must create a Training Arguments class that contains all of the hyperparameters that the Trainer will use during training and evaluation. We must provide a directory in which the trained model, as well as the checkpoints along the process, will be recorded. We can leave the rest of the settings, which should be sufficient for basic fine-tuning.
- We can define a Trainer by providing it all of the objects we’ve built so far — the model, the training arguments, the training and validation datasets and our tokenizer.
- After defining all of the parameters to the Trainer class, we simply need to use our Trainer’s train() method to fine-tune the model on the dataset.
Conclusion and Future aspects
- TLDR shows that it is possible to generate single-sentence summaries of scientific papers. Scientific articles, on the other hand, vary in complexity. Not all papers can be summed up in a single statement without losing their meaning. It’s exciting to think about a TLDR model that can handle even the most difficult research articles.
- Abstractive extreme summarization pretrained model give state of art results for computer scientific publication. For creating summaries of literature from various academic areas, a tweaked version of the TLDR model may be required.
- Generation of TLDR can be extended to more pre trained models which can be fine-tuned for generating extreme summarization of scientific papers.
References
- Cachola, D. (2020). TLDR: Extreme Summarization of Scientific Documents. In Findings of the Association for Computational Linguistics: EMNLP 2020 (pp. 4766–4777). Association for Computational Linguistics.
- Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, & Donald Metzler. (2021). Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers.
- Mike Lewis and Yinhan Liu and Naman Goyal and Marjan Ghazvininejad and Abdelrahman Mohamed and Omer Levy and Veselin Stoyanov and Luke Zettlemoyer (2019). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. CoRR, abs/1910.13461.
- Guillaume Lample and Alexis Conneau (2019). Cross-lingual Language Model Pretraining. CoRR, abs/1901.07291.
- Jesse Vig. (2019). A Multiscale Visualization of Attention in the Transformer Model.
- Shuming Ma, Jian Yang, Haoyang Huang, Zewen Chi, Li Dong, Dongdong Zhang, Hany Hassan Awadalla, Alexandre Muzio, Akiko Eriguchi, Saksham Singhal, Xia Song, Arul Menezes, & Furu Wei. (2020). XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, ., & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998–6008).
- Genest, P.E., & Lapalme, G. (2011). Framework for abstractive summarization using text-to-text generation. In Proceedings of the workshop on monolingual text-to-text generation (pp. 64–73).
- Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., & others (2019). Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771.
- Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. CoRR, abs/1910.10683.
- https://www.analyticsvidhya.com/blog/2019/06/comprehensive-guide-text-summarization-using-deep-learning-python/
- https://code.oursky.com/ai-text-generator-text-generation-with-a-gpt2-model/
Cite this article:
Mridul Sharma, Diksha Malhotra, Poonam Saini (2021) Extreme Abstractive Summarization of Scientific Documents, Insights2Techinfo, pp.1