By: Rishitha Chokkappagari, Department of Computer Science &Engineering, student of Computer Science & Engineering, Madanapalle Institute of Technology & Science, Angallu (517325), Andhra Pradesh. chokkappagaririshitha@gmail.com
Abstract
Cyber spam, which entails unnecessary, and at times, undesirable content transmitted through the internet, mainly in emails, is a major obstacle to digital communications. Due to a large amount of spam and constant changes in its characteristics, the use of more efficient methods for combating spam is required. Artificial Intelligence (AI) and Machine learning (ML) appear fashionable to detect, prevent and provide response. They also have inherent characteristic of learning from data and getting transformed into a pattern recognition system able to detect complex new threats. The present article aims at reviewing the use of machine learning techniques to fight against spam and the strategies including supervised learning, unsupervised learning, and deep learning. We present a set of models based on the description of the spam messages features – the text content of the messages, message headers, and user interactions with the messages, which can help to identify the spam and distinguish it from the rest of the messages and authorized messages. Thus, the findings of this study reveal that there is a potential to enhance spam detection at high levels of accuracy and efficiency with comparatively low false positive rates by using ML-based methods. The possibility of its application is the optimization of the user interface and protection of their privacy, as well as the decrease in spam’s effect on the economy.
In this article, it is also mentioned about the problem related to ML for spam detection such as the requirement of large, labelled data how to encounter problem of concept drift, and that spammers are always on the other side.
Keywords: Spam, Machine Learning, Deep Learning, Cyber Attacks
Introduction
Communication has been made easier with digital communication technology. However this comes with the issue of spam, these are unwanted messages that flood mailboxes, consume time and can be unsafe. The long-standing approaches of using rules and blacklists can easily be defeated by today’s intelligent spammers and therefore more sophisticated counter measures are required.
Current approaches consider Machine learning (ML) as a reasonable solution to fight spam because algorithms tend to improve as they learn from the information dealt with. This work deals with different types of ML ranging from supervised learning such as support vector machines and neural networks and other forms of learning such as clustering and anomaly detection. Also examine newly popularized deep learning paradigms focusing on convolutional and recurrent neural networks for their characteristic of handling complex data structures.
We are to build reliable spam models that enhance the performance and minimize the misrepresentation in terms of the project’s features including text content, meta information and user activity. We focus on issues like the requirement of big, labelled data sets, concept drift, and robustness. Thus, in this study we seek to develop better ways of filtering out spam messages by applying ML to advance spam detection systems, increases the effectiveness of users’ experiences safeguard computerised environments from spam nuisances. The fig.1 depicts the process of finding a spam mail.
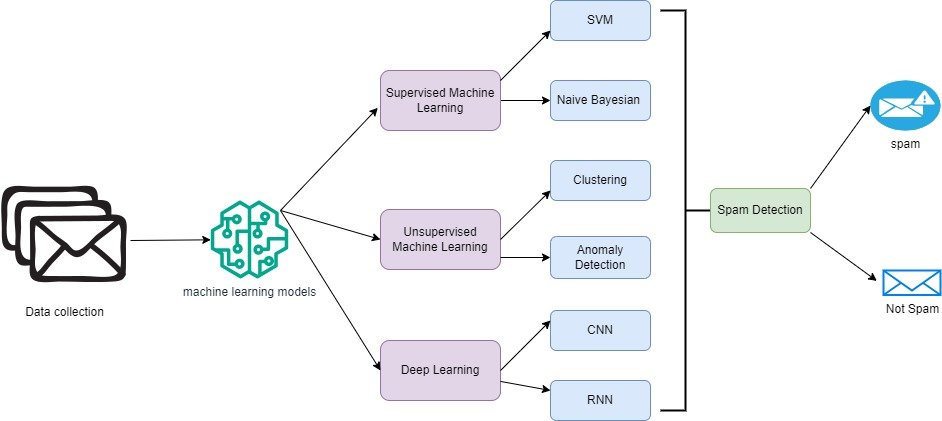
Figure 1 Recognizing spam mails using ML AND DL
- Data Processing
When dataset is considered, it contains large number of rows and columns. The dataset doesn’t need to be only in the text format it can also be in image or video format. Here comes the problem that the machine doesn’t understand the data in image or video or text formats, it can understand only in binary format (i.e., 0’s and 1’s). So, the data need to be cleaned, integrated, transformed and processed.
- Data Cleaning:
Filling Missing Values: As it can be seemed from the gaps analysis, if there is any significant amount of data missing that should be filled.
Smoothing Noisy Data: Reducing Missing Links, Oneness, Rare, Emergences, Abnormalities and Unusualness.
Removing Outliers: The procedure of excluding or leaving out of the data set those observation that are considerably different than all the other observations.
Resolving Inconsistencies: To ensure that collected data are rather specifics-oriented and sufficient and offer equal informative value[1].
- Data Integration: Dividing the information into many reports and surveys.
- Data Transformation:
Aggregation: Summarizing data.
Normalization: The process of making the values within the sets, which we deal with, to be close to one another by making the whole set larger or smaller[2].
- Data Reduction: Pivoting to reduce the amount of data they retain but at the same time, retaining useful data[3].
Table 1 process of finding a spam mail using ML
Section | Description |
Introduction | Overview of the challenge of spam detection in various data forms (text, images, audio, video). |
Data Preprocessing | Steps to prepare data for analysis, including cleaning, integration, transformation, and reduction. |
Text Processing | Techniques for handling textual data, such as stop words removal, tokenization, and the Bag of Words model. |
Classic Classifiers | Brief descriptions of common classification algorithms used for spam detection: Naive Bayes, SVM, Decision Tree, K-NN. |
Ensemble Learning | Overview of ensemble methods like Random Forest, Bagging, and Boosting, highlighting their benefits in improving model performance |
Classic Classifiers
Naïve Bayesian Classifier: Naïve Bayesian classifier is a supervised machine learning algorithm that uses features of the old data to make prediction on a target variable. It is basically used for classification tasks, solving regression problems. It is mainly used in spam detection because it doesn’t require a much of the training data. It is used for probability check weather the given data contains spam or not.
The probability can be defined as:
[3]
Support Vector Machine: Support Vector Machine is used for classification, regression and outliers detection. It performs optimal data transformations that determine boundaries between data points using hyperplane based on predefined classes, outputs, labels. It was initially designed for binary classification problems. After the rise of multi class problems several binary classifications are combined to form a support vector machine that executes multi class problems in means of binary classification. It is effective in dimensional spaces.
Decision Tree: Decision Tree is another popular machine learning techniques used for performing both the classification as well as the regression. Constructed in the tree-like structure in which an internal node is a “test” or a “decision” made concerning features of the objects in the data set, each branch is the result of a particular test, each leaf node is a class label in the case of classification problem, or a continuous value, in case of regression problem. Here’s a detailed description:
Parts of a Decision Tree
- Root Node- The initial or root node of a decision tree which contain all the records in the dataset. There on it is divided into two or more sets, all of which are homogeneous in nature.
- Decision Nodes- Mid-level nodes that correspond to the features of the data set that has been considered.
- Leaf Nodes (Terminal Nodes) – The nodes at the terminate of the tree in which outcome or decision is made
- Branches- Every branch represents a value or a possible range of the feature in the decision node which is being tested.
K-Means: K-means is one of the most common forms of unsupervised machine learning, which is most commonly used under the category of clustering, The process by which data points are divided based on the similarity and then combine in sets called clusters in such a way that an object in a cluster is more similar to other objects within the same cluster than objects within other clusters. Though it is most beneficial in exploratory data analysis to search for a structure or a pattern in data sets[4].
Key Concepts of K-means:
Centroids: Potential central points that occurred to the researcher while perceiving the centre of each cluster. Every centroid is the average of the points belonging to the corresponding cluster.
Clusters: Categories made up of sets of measurable data that are like each other. The similarity with respect to the corresponding vectors is normally determined by distance, Euclidean distance in this case[5].
Artificial Neural Networks:
Artificial neural networks (ANN-s) is a large class of algorithms applied for Supervised learning, unsupervised learning and clustering, prognosis and density forecasts. More precisely, a neural network is specific function represented perhaps by a neuron or a group of neurons in such a way that a decomposing of the function was done[5]. A processing unit and was portrayed in form of a network, neurons. Many functions could be depicted this way and hence the notion is not without merit. Never quite sure as to which of them falls under the preview of neural networks, and which do not. There are, however the two “classical” kinds of neural networks, that are most often meant when the term ANN is used: the perceptron and the multilayer perceptron[6].
Conclusion
Summing up the information concerning the application of machine learning in the fight against spam, it is possible to note the growing role of this technique in enhancing the quality of online intercommunication and preventing malicious activity. The use of ML helps in properly filtering out spam through recognition of invariant patterns, behaviours as well as other characteristics of spam. These systems evolve to become better at optimizing between recognition of spam and non-spam and the tactics spammers invent. The main advantages of machine learning applications include the general performance, adaptability, ability to learn from a massive number of emails. These are the capabilities that enabled a more accurate and real-time filtering, took the burden from users’ hands and subdued spam. But it is necessary to enhance such models from time to time to respond to new spam approaches and to avoid filtering of useful materials. In conclusion, this article has shown that the use of machine learning in spam reduction is a reliable, self-learning and efficient method of controlling unwanted emails making the digital environment more secure to use.
References
- T. Toma, S. Hassan, and M. Arifuzzaman, “An Analysis of Supervised Machine Learning Algorithms for Spam Email Detection,” in 2021 International Conference on Automation, Control and Mechatronics for Industry 4.0 (ACMI), Jul. 2021, pp. 1–5. doi: 10.1109/ACMI53878.2021.9528108.
- F. Hossain, M. N. Uddin, and R. K. Halder, “Analysis of Optimized Machine Learning and Deep Learning Techniques for Spam Detection,” in 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Apr. 2021, pp. 1–7. doi: 10.1109/IEMTRONICS52119.2021.9422508.
- N. Kumar, S. Sonowal, and Nishant, “Email Spam Detection Using Machine Learning Algorithms,” in 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Jul. 2020, pp. 108–113. doi: 10.1109/ICIRCA48905.2020.9183098.
- C.-C. Lai, “An empirical study of three machine learning methods for spam filtering,” Knowl.-Based Syst., vol. 20, no. 3, pp. 249–254, Apr. 2007, doi: 10.1016/j.knosys.2006.05.016.
- Tabassum F, Rahaman M (2024) An Enhanced Multi-Factor Authentication and Key Agreement Protocol in Industrial Internet of Things, Available: https://insights2techinfo.com/an-enhanced-multi-factor-authentication-and-key-agreement-protocol-in-industrial-internet-of-things/
- Rahaman M (2024) Foundations of Phishing Detection Using Deep Learning: A Review of Current Techniques Available: https://insights2techinfo.com/foundations-of-phishing-detection-using-deep-learning-a-review-of-current-techniques/
- K. Tretyakov, “Machine Learning Techniques in Spam Filtering”.
- Sahoo, S. R., Gupta, B. B., Choi, C., Hsu, C. H., & Chui, K. T. (2020). Behavioral analysis to detect social spammer in online social networks (OSNs). In Computational Data and Social Networks: 9th International Conference, CSoNet 2020, Dallas, TX, USA, December 11–13, 2020, Proceedings 9 (pp. 321-332). Springer International Publishing.
- Sahoo, S. R., Gupta, B. B., Peraković, D., Peñalvo, F. J. G., & Cvitić, I. (2022). Spammer detection approaches in online social network (OSNs): a survey. In Sustainable Management of Manufacturing Systems in Industry 4.0 (pp. 159-180). Cham: Springer International Publishing.
Cite As
Chokkappagari R. (2024) Using Machine Learning to Combat Spam, Insights2Techinfo, pp.1