By: OWAIS IQBAL
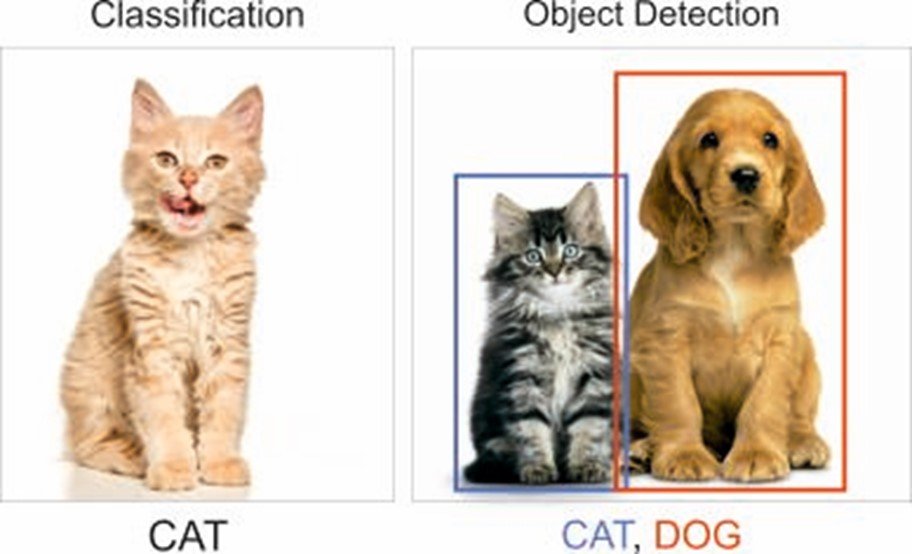
Image Classification and Detection are two wide topics in the domain of Computer Vision. Image Classification, is basically predicting the object in the image of the class it belongs to. The main objective in Classification would be to accurately derive the features of the image. As depicted in Fig. 1, first image shows us an image of a cat, hence classifying the image as Cat class.
Detection, by definition is the action or process of identifying the presence of something concealed. But limiting our outreach to Computer Vision Tasks we deal with Object Detection(OD). OD is a combination of Classification and Localization i.e. considering an image as input we output the class of the object present in the image and its location(e.g. bounding box). Second part of Fig. 1, depicts an example for OD, the red box denotes the Dog class whereas, blue box shows Cat class. To furthermore narrow our topic, I introduce the term K-way N-shot Learning which specifically means we have K-classes and N-shot means that for each class we have only N-training examples. Zero-Shot Detection(ZSD) aims at simultaneously recognizing and locating objects belonging to unseen classes (i.e. classes for which there are no instance present at the time of training). Similarly, for videos we deal with Zero-Shot Activity Detection.
Conceptual Ideas or Knowledge:
Activity Detection is the problem of identifying events in a given input video. Whereas, activity detection in continuous, uncut videos is recognition and localization of an activity in a video. This task necessitates the extraction of relevant spacio-temporal features to classify activities and accurately localizing each activity i.e determining its start and end times, which is successfully done by using Convolution Neural Networks(CNN) and Deep Learning Methods. Temporal Activity Detection is detecting activities in long untrimmed videos which would certainly contain multiple activities. Currently, Temporal Activity Detection methods use deep networks with end-to-end learning architectures which has enhanced the accuracy and speed of Temporal Activity Detection as shown in studies ([1], [2], [3]). These methods perform very well with datasets having activities annotated in large scale at training phase. But have limited real-life application because of the videos concerning to some activity classes aren’t available and the tedious job of annotating data. Long videos contain multiple activities, every activity class already tagged or annotated are uncommon, and annotating manually is costly and time consuming, thus other approaches such as weakly-supervised [4], semi-supervised, and unsupervised learning are used instead.
Challenges and Perspective Research Directions:
Challenge would be to work on a noval approach to this issue referred as Zero-Shot Learning(ZSL). ZSL means that the training and testing classes(i.e. seen and unseen classes) are different but related semantically[5].
To build a Zero-Shot Temporal Activity Detection(ZSTAD) model which would detect an activity in a video which is never seen at the training phase and address the practical challenge stated above. So far studies have been done in Zero Shot classification problems, assuming that each sample would contain only single class activity. But our aim would be to classify most of the unseen activities to unseen classes and also localizing it. This would overcome the problem and give us the access to the ocean of un-annotated videos present and increasing every second. Some of the Research Directions are discussed below.
Approach 1 : Using Label Semantics
In this approach following task would be incorporated:
- The training(i.e. seen class) and the testing(i.e. unseen class) are disjoint. Given the label embeddings of the seen classes a model would be trained which will take into account the semantic embeddings to build a relationship between the seen and unseen classes.
- The label embeddings could be accurately determined using word embedding models like [6] or [7]
- Given the label embeddings, we would put the video features learned by deep networks alongside the label embeddings in the same metric space. Using this common embedding space, we would output detection proposals by applying estimated bounding-box transformations to a set of regular twins (called “anchors”) and training would be done incorporating various losses.
- Presence of background class is very necessary so as to differentiate between foreground and background activities. Problem arises if a proposal belongs to background or the unseen class. We would make the embedding for background as far away as possible from all the activities present so segregation is possible.
- The trained model will then be used for detecting the unseen classes at testing phase.
Approach 2 : Using Generative Models
This would be a novel approach in terms of Temporal Activity Detection, we would take the label embeddings into account but the features for the unseen classes would be generated by Generative models as suggested not limited to paper like [8] but in video domain. These methods would be required to generate high quality features for unseen classes using the semantic space of the seen and unseen classes.
Given the generative model, a unified model would be used to ensure diversity in intra-class variations of the unseen classes and also localizing it. This would increase the accuracy of determining correct results at testing phase.
Conclusion:
In this article, I tried to shed some light of the topic of Object Detection, specifically Zero-Shot Temporal Activity Detection (ZSTAD). As the topic is less researched in video domain, this will be a major attraction for researchers working in the domain of Computer Vision, Deep Learning etc. One limitation working in this area would be the resources. As we know for Image processing of high quality requires a lot of high computing devices and GPU’s so, one would imagine how much more resources would be required for computing processing videos. The models generated(after training phase) would also require lots of space to execute thereby, making it difficult for individuals working with constraint in resources.
The approaches discussed above indeed are not exhaustive and as and when new cutting edge technologies are discovered, new pathways will come up.
References:
1. Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xiaoou Tang, and Dahua Lin (2017). Temporal action detection with structured segment networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), volume 2.
2. Jiyang Gao, Zhenheng Yang, Chen Sun, Kan Chen, and Ram Nevatia (2017). Turn tap: Temporal unit regression network for temporal action proposals. In Proceedings of the IEEE International Conference on Computer Vision (ICCV).
3. Huijuan Xu, Abir Das, and Kate Saenko (2017). R-c3d: region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 5794–5803.
4. Limin Wang, Yuanjun Xiong, Dahua Lin, and Luc Van Gool (2017). Untrimmednets for weakly supervised action recognition and detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), pages 4325–4334.
5. Shafin Rahman, Salman Khan, and Fatih Porikli (2018). Zero-shot object detection: learning to simultaneously recognize and localize novel concepts. In Proceedings of the Asian Conference on Computer Vision (ACCV).
6. Jeffrey Pennington, Richard Socher, and Christopher Manning (2014). Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543.
7. Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov (2016). Bag of tricks for efficient text classification. arXiv preprint 1607.01759.
8. Ishaan Gulrajani, Faruk Ahmed, Mart´ın Arjovsky, Vincent Dumoulin, and Aaron C. Courville (2017). Improved training of Wasserstein GANs. CoRR, abs/1704.00028.
Cite this article:
OWAIS IQBAL (2021) Zero-Shot Temporal Activity Detection, Insights2Techinfo, pp.1
Also Read:
- Humanoid Robots: The future of mankind
- CLASSIFICATION OF FUNGI MICROSCOPIC IMAGES – Leveraging the use of AI
- Metaverse Technologies and Its Applications