By: Mosiur Rahaman, International Center for AI and Cyber Security Research and Innovation, Asia University, Taiwan
Abstract:
Utilizing the trustworthiness and conciseness of SMS messages, smishing, also known as SMS phishing, tricks users into disclosing confidential data or clicking on unsafe hyperlinks. In order to detect smishes, this study compares deep learning methods like CNNs and RNNs with machine learning algorithms including Logistic Regression, Naive Bayes, Random Forests, SVM, and K-NN. While sophisticated techniques like as CNN-LSTM hybrids are excellent at capturing complex patterns and sequential dependencies, traditional methods provide simplicity and speed. The research emphasizes the need for robust, automated solutions to counter emerging smishing threats by highlighting trade-offs in scalability, precision, and flexibility.
Introduction
The way people and businesses communicate has changed because of the widespread use of mobile communication devices. However, the growing dependence on mobile platforms has also resulted in a rise in cyberthreats, with SMS phishing, or smishing, becoming a particularly widespread threat. Smishing attacks make use of SMS communication’s widespread use and perceived reliability to trick users into disclosing private information, clicking on harmful links, or taking other actions that compromise their security [1]. Because of this, smishing affects millions of people globally and presents serious risks to money integrity, data security, and privacy.
The evolving nature of smishing attacks makes it inherently difficult to detect these attacks. Unlike traditional phishing emails, smishing messages are usually brief, lack rich context, and are frequently designed to bypass basic security safeguards. Furthermore, manual detection is ineffective and prone to errors because of the contextual unpredictability and linguistic ambiguity in SMS content. It is this context that has necessitated the adoption of machine learning (ML) techniques to provide automated, scalable, and reliable smishing detection [2].
Following the remarkable success of ML algorithms in various domains, from spam filtering to image recognition, it is increasingly being used in cybersecurity applications. Since ML models are endowed with the capacity to learn from vast datasets by identifying patterns and extracting features that distinguish legitimate messages from malicious ones, they can be used for smishing detection [3]. However, the objective of this short article is thus to conduct a comparative analysis of the different classification algorithms for smishing detection to determine which classification algorithms are best suited for smishing message detection and to assess the trade-offs between scalability, performance, and algorithmic complexity. It focuses on various classification methods, such as Neural Networks, Support Vector Machines (SVM), Naive Bayes, K-nearest neighbors (K-NN), Decision Trees, Random Forests, and Logistic Regression [4].
Literature Review
This section offers a thorough analysis of the body of research, with particular attention to (1) the smishing environment and its difficulties and (2) a review of existing literature on smishing detection. This review points out research gaps that highlight the necessity of comparing classification methods for smishing detection methodically.
Understanding smishing and its challenges
Smishing, also known as SMS phishing, is a type of targeted cyberattack in which victims are tricked into disclosing private information or carrying out harmful tasks by means of false text messages. Smishing, as opposed to traditional email phishing, takes use of the trust and brevity of SMS communication. Key challenges associated with smishing detection include the conciseness of messages, evolving threat patterns that employ tactics such as URL obfuscation and social engineering, uneven learning datasets of legitimate and malicious messages, and ambiguous language used in messages. These challenges make traditional rule-based detection inadequate, prompting the need for advanced ML-based algorithms.
Review of existing literature on smishing detection
Early smishing detection relied heavily on rule-based systems, following phishing detection, such as blacklist checks and static content analysis. However, despite their relative success, these systems had trouble identifying zero-day attacks and adjusting to quickly changing attack patterns. This drawback made it clear that more flexible and reliable methods were required. So, with the advent of ML techniques, algorithms such as Random Forests, Support Vector Machines (SVM), and Naive Bayes gained popularity for smishing detection. Examples include studies, who analyzed different correlation algorithms to determine what are the best features to detect smishing messages, and by , who found that the Random Forest Algorithm outperformed other algorithms such as Naive Bayes and Decision Tree [5].
However, before incorporating deep learning advancements into smishing detection, it is important to have a comprehensive understanding of the various ML classification algorithms since analyzing their strengths and weaknesses will provide the foundation to make an informed decision regarding which algorithms need to be adopted for effective smishing detection. Accordingly, the rest of the short article discusses the different ML classification algorithms in detail.
Classification Algorithms in Machine Learning
Classification is a supervised learning task where the goal is to categorize input data into predefined classes or labels. It is essential to many applications, such as picture identification, fraud detection, spam detection, and medical diagnostics. However, depending on the nature of the data, the problem requirements, and the desired trade-offs between accuracy, interpretability, speed, and scalability, different classification algorithms are used. This section provides a detailed comparison of different ML classification algorithms with a special focus on their role in smishing detection [6].
Logistic Regression, despite its simplicity, is widely used for binary classification jobs. It is efficient and interpretable for linearly separable data since it uses the sigmoid function to estimate the likelihood that an instance will belong to a specific class. However, it struggles with complex, non-linear data. Another fundamental algorithm, Naive Bayes, is excellent at text-based applications like sentiment analysis and spam filtering because it assumes feature independence. The fast computation power and ability to handle small datasets and missing data make it a very popular choice. However, it struggles with complex correlated features and accuracy due to the assumed independence between features, which may not always hold [7].
A versatile classification algorithm that can handle numerical and categorical data is Decision Trees, which splits data into subsets based on feature value, creating tree structure where each internal node represents a decision based on a feature. However, these are often prone to overfitting, especially with deep trees. Another classification algorithm is an ensemble of decision trees called Random Forest, which is robust for high-dimensional data because it reduces overfitting and increases accuracy by averaging predictions from several trees. However, the computational cost becomes a huge drawback in cases of large datasets. Support Vector Machines (SVM), a classification algorithm, perform well for both linear and non-linear classification and are efficient for high-dimensional data, when equipped with kernel functions. Yet, as dataset sizes grow, SVMs may become computationally costly [8].
Another simple and intuitive algorithm is K-Nearest Neighbors (K-NN), which groups instances according to the majority class of their nearest neighbors. It is sensitive to noise and computationally demanding during inference, despite being simple to construct and modify. To achieve high accuracy, gradient boosting machines (GBM), including well-known variations like XGBoost and LightGBM, iteratively construct models that fix mistakes from earlier iterations. However, these models are computationally intensive and need to be carefully adjusted to avoid overfitting.
Other algorithms that concentrate on class separation and dimensionality reduction include Linear Discriminant Analysis (LDA) and Quadratic Discriminant Analysis (QDA). While QDA can handle non-linear boundaries but requires more data for dependable results, LDA assumes linear bounds, which makes it effective for simpler issues. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs), two deep learning models, have become effective smishing detection methods. By automatically learning feature representations from unprocessed text, these models can spot minute patterns that conventional algorithm might overlook. As an example we consider with a small data for how to implement in the Realtime using the algorithm, to categorize new data ,classification algorithm help to learns patterns from the trained data. Here one simple example as a confusion matrix shown in figure 1 and figure 2 classification report ,model is trained by emails data which are spam and ham to determine the patterns like specific word or style for the spam detection. Very smoothly trained model evaluates its features and predict 100% the spam and ham types.
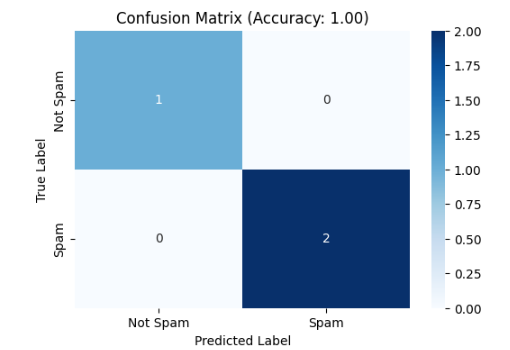
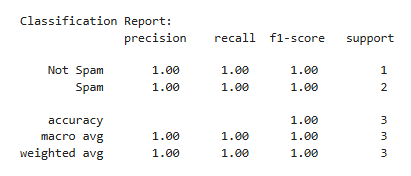
Conclusion
Classification algorithms play a vital role in smishing detection, where the goal is to identify malicious SMS messages that attempt to deceive users into revealing sensitive information or performing harmful actions. These algorithms analyze patterns in text messages, such as word frequency, message length, and the presence of suspicious links, to distinguish between legitimate and smishing messages.
Because of its ease of use and effectiveness when processing text data, logistic regression and Naive Bayes are frequently employed in preliminary smishing detection investigations. Because they can handle imbalanced datasets and catch intricate patterns in variables like URLs and linguistic structures, random forests and gradient boosting models—like XGBoost—are very useful in this field. SVMs are used to distinguish between authentic and smishing messages, particularly in high-dimensional feature spaces produced by text vectorization methods such as TF-IDF. At present, deep learning models are being integrated into smishing detection, demonstrating how hybrid techniques, like CNN-LSTM models, can effectively capture both geographical and sequential dependencies in SMS messages.
Considering the varied challenges involved in smishing detection, such as limited labeled data, linguistic diversity, and the dynamic nature of attacks, algorithms must be resilient, scalable, and able to adjust to novel attack patterns. So, by using classification algorithms effectively, smishing detection can reduce risks and shield consumers from potentially destructive intrusions.
Reference:
- T. Mahmud, M. A. H. Prince, M. H. Ali, M. S. Hossain, and K. Andersson, “Enhancing Cybersecurity: Hybrid Deep Learning Approaches to Smishing Attack Detection,” Systems, vol. 12, no. 11, Art. no. 11, Nov. 2024, doi: 10.3390/systems12110490.
- Z. Alkhalil, C. Hewage, L. Nawaf, and I. Khan, “Phishing Attacks: A Recent Comprehensive Study and a New Anatomy,” Front. Comput. Sci., vol. 3, Mar. 2021, doi: 10.3389/fcomp.2021.563060.
- I. H. Sarker, “Machine Learning: Algorithms, Real-World Applications and Research Directions,” SN COMPUT. SCI., vol. 2, no. 3, p. 160, Mar. 2021, doi: 10.1007/s42979-021-00592-x.
- A. Shinde, E. Q. Shahra, S. Basurra, F. Saeed, A. A. AlSewari, and W. A. Jabbar, “SMS Scam Detection Application Based on Optical Character Recognition for Image Data Using Unsupervised and Deep Semi-Supervised Learning,” Sensors, vol. 24, no. 18, Art. no. 18, Jan. 2024, doi: 10.3390/s24186084.
- G. Gallet, G. Guerard, and S. Djebali, “Automatic Smishing Detection System with Feedback Loops,” Aug. 12, 2024, Research Square. doi: 10.21203/rs.3.rs-4760693/v1.
- “What is Classification in Machine Learning? | IBM.” Accessed: Dec. 06, 2024. [Online]. Available: https://www.ibm.com/think/topics/classification-machine-learning
- D. Saini, T. Chand, D. K. Chouhan, and M. Prakash, “A comparative analysis of automatic classification and grading methods for knee osteoarthritis focussing on X-ray images,” Biocybernetics and Biomedical Engineering, vol. 41, no. 2, pp. 419–444, Apr. 2021, doi: 10.1016/j.bbe.2021.03.002.
- A. Singh, “Decision Tree in Machine Learning,” Applied AI Blog. Accessed: Dec. 06, 2024. [Online]. Available: https://www.appliedaicourse.com/blog/decision-tree-in-machine-learning/
- Kee S.N. (2024) Securing IoT-Based Supply Chains: Blockchain and Phishing Attack Prevention, Insights2Techinfo, pp.1
Cite As
Rahaman M. (2025) Machine Learning for Smishing Detection: A Comparative Study of Classification Algorithms, Insights2Techinfo, pp.1