By: Dikshant Rajput; CSE, Chandigarh College of Engineering and Technology, Chandigarh, India. Email: CO22326@ccet.ac.in
Abstract
This article explores open-source Large Language Models and evaluates them on variety of datasets. LLM use an architecture which contain encoder and decoder. The encoder processes input tokens through levels like embedding, multihead listening and layer normalization, while decoder is required for tasks like completion and question answering. The article investigates open Models such as Llama, Falcon, MPT in different versions. Performance measuring is done on various tasks such as sentence completion, coherent thinking and emotional analysis using datasets such as ARC, HellaSwag, MMLU, GSM8K, TruthfulQA, Winograde. Open LLM are driven by advances in collaboration, data availability, and education. Despite the progress, hindrance persist and the biggest challenge is the absence of universally agreed-upon criteria. Benchmarking initiatives like MMLU and ARC aim to improve this situation and provide standardized frameworks for robust, fair comparisons and offer compelling alternatives to closed source models.
Introduction
There has been a shift in large language models with the imergence and proliferation of open-source models like MPT, Falcon, Llama. These are complex algorithm which are supported by massive datasets and a community effort to help redefine machine learning for mimicking human like text. The LLMs are the algorithms that simulate human like language. The difference between in open source llm is their accessibility and adaptability which allows users to build upon texisting models, fine tune them for specific task. The article take pre-trained models at it’s base sourced from hugging face. Prominent open-source LLMs like Llama, Falcon and MPT take center stage in the study, where there parameter count, and training datasets are dissected. Performance evaluation extends to various tasks, including commonsense reasoning, sentence completion, and sentiment analysis, employing standardized benchmarks like ARC and HellaSwag[1].
Architecture of Large Language Models
LLMs use an architecture called transformers to predict the upcoming word in a sentence. The architecture consists of an encoder, and decoder stack.
Encoder
It is a component responsible for the input of tokens. To elaborate further, in a typical transformer model, the encoder takes in input data (such as a sequence of words) and applies selfattention mechanisms to capture relationships between different parts of the input sequence. The transformer encoder processes the input in parallel, making it computationally efficient.
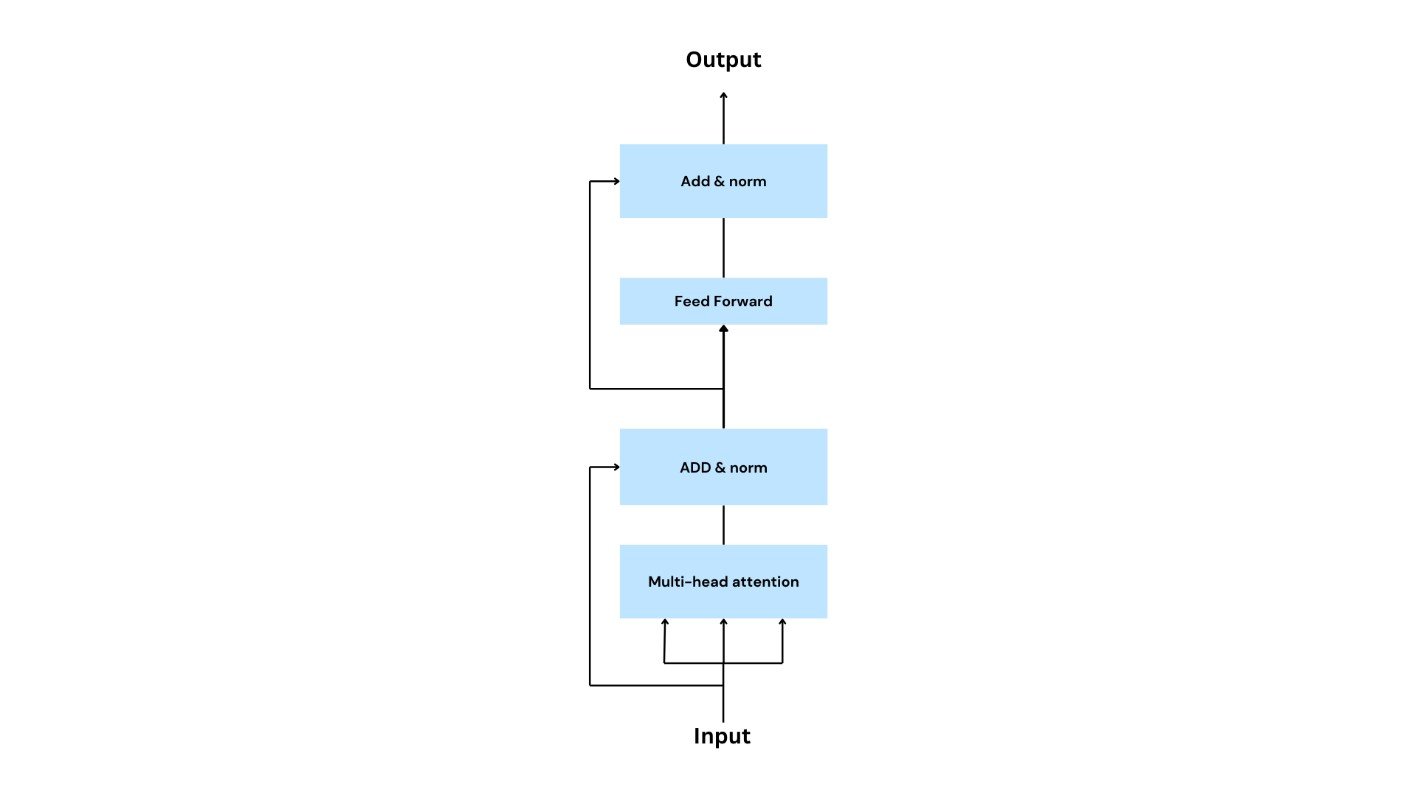 Fig1: Architecture of Encoder[5]
Fig1: Architecture of Encoder[5]
In the encoder architecture, data travels through the model in steps namely, Input Embedding, Multihead Attention, Addition and Normalization, Feedforward layer.
Input Embedding Layer
In Input Embedding the input sequence is initially converted into embeddings and every token in the sequence is represented in the form of high-dimensional vector. It serves the purpose of feeding input in to the model and is often combined with positional encodings to provide information of the token in the sequence.
Multihead Layer
The embedded sequence is then forwarded to the multiheaded attention mechanism, it computes attention score for which determines how much attention will be given to different portion in the input sequence. The mechanism is applied independently to every head, resulting in multiple sets of attention scores, then every set is linearly transformed to produce the final multiheaded attention output. The set of queries is packed together in a matrix Q. The keys and values are also packed into matrices K and V
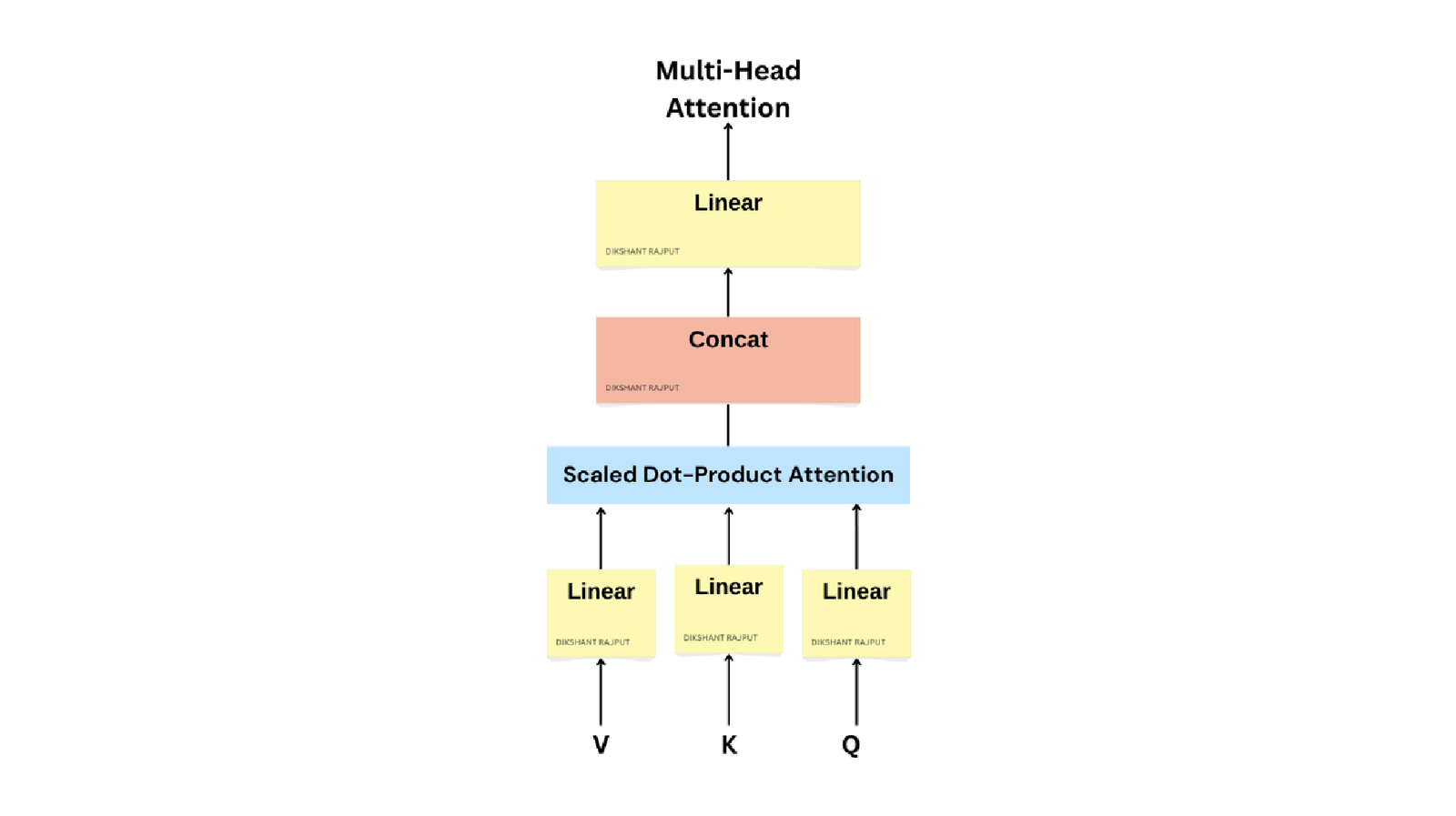
Fig2. Multi-Head Attention consists of several attention layers running in parallel[5]
𝑀𝑢𝑙𝑡𝑖𝐻𝑒𝑎𝑑(𝑄, 𝐾, 𝑉) = 𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑒𝑎𝑑1, … , ℎ𝑒𝑎𝑑ℎ)𝑤0
𝑤ℎ𝑒𝑟𝑒 ℎ𝑒𝑎𝑑𝑖 = 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄𝑊𝑖𝑄, 𝑘𝑤𝑖𝑘, 𝑣𝑤𝑖𝑣 )
Layer Normalization Layer
Layer normalization normalizes the values across the feature dimension for every example in batch, importantly it helps stabilizing the distribution of inputs and ensure it remains consistent throughout training.Then comes the feed forward layer that consists of two linear transformations with a ReLU activation function in between. This structure enables to capture complex, non-linear relationships in the data. The layer like above operates independently on each position in the sequence.
FFN(𝑥) = 𝑚𝑎𝑥(0, 𝑥𝑤1 + 𝑏1)𝑤2 + 𝑏2
Decoder
A decoder-only model lacks an encoder. It encodes the information implicitly in the hidden state and relays during the output generation, they are commonly used for text generation. The decoder only models one word in a sentence at a time, some of the prominent examples of this architecture are transformer XL and LLaMA. The models based on this can do a variety of work including text completion, and question-answering (chatbots like chatbot, Bard).

Fig3. Architecture of Decoder [5]
Open-source Large Language Models (LLMs)
LLamA:
It is a decoder-only architecture. Developed by Meta. Parameters range from 7 to 65 billion parameters, The first model (LLaMA1) was trained on 1.4 trillion tokens and LLaMA had a dataset of 2 trillion tokens. While it is better than models like MPT but still lags behind GPT-4. The Llama 1 license was designed for non-commercial purposes, whereas the Apache 2.0 license permits commercial use with certain limitations. Meta explicitly prohibits the utilization of Llama 2 for training other models. Additionally, if Llama 2 is integrated into an application or service catering to over 700 million monthly users, a distinct license from Meta AI is mandatory. This implies that the architecture is open for examination and modification, allowing the code to be employed in generating novel models. Nevertheless, the model weights, housing the learned parameters, are not accessible to the public.
Falcon :
Falcon LLM, developed by the Technology Innovation Institute in the United Arab Emirates, presents a significant contribution to the burgeoning field of open-source large language models. With a vast parameter count of 180 billion and trained on a meticulously curated dataset of 3.5 trillion tokens, Falcon demonstrates exceptional capabilities in natural language processing tasks.
MPT :
MosaicML Pretrained Transformer is an open-source decoder-only model for commercial operations developed by MosaicML. Trained upon code of 1T tokens and has a variety of tokens such as OpenLLaMA, StableLM, and Pythia. It has a context length of 8K tokens and has 6.7B parameters, having three fine-tuned versions MPT-7B Base, MPT-7B-StoryWriter-65K+, MPT-7B-Instruct, MPT7BChat(non-commercial use only).
The models are required to perform on a variety of task like being able to perform commonsense reasoning, predict the correct ending of a sentence, language understanding, question-answering, resolving ambiguous pronouns, sentiment analysis.
Datasets used for Benchmarking
- ARC: The ARC dataset includes 7,787 science exam questions sourced from various places, with a focus on English language questions spanning different grade levels. Each question is in multiple-choice format (usually with 4 answer options). The dataset is divided into a Challenge Set (2,590 ‘hard’ questions) and an Easy Set (5,197 questions). Both sets are further categorized into Train, Development, and Test sets. The Challenge Set consists of 1,119 Train questions, 299 Development questions, and 1,172 Test questions. The Easy Set includes 2,251 Train questions, 570 Development questions, and 2,376 Test questions. File format : CSV, JSON
- Hellaswag: The dataset is used to test the sentence completion capability of a language model, consisting of various. The dataset was created by the Allen Institute for Artificial Intelligence (AI2), and it includes questions that are carefully designed to be answerable only with true commonsense reasoning. Tasks in HellaSwag may involve predicting the correct ending of a sentence based on a nuanced understanding of causality, knowledge of the world, and reasoning about temporal relationships.
- MMLU (Massive Multitask language Understanding)[2] : Containing 15908 questions in total varying from elementary mathematics, computer Science, law. The dataset intends to test the model on extensive world knowledge and problem solving ability.
- TruthfulQA [3]: TruthfulQA tackles the tricky challenge of measuring how truthfully language models respond to questions, especially when faced with topics ripe for misinformation. This dataset of 817 questions, spanning diverse categories like health and law, throws curveballs like popular misconceptions and superstitions to test models’ ability to resist generating misleading information. By pushing models beyond simply regurgitating facts, TruthfulQA helps reveal their capacity for clear, honest, and responsible communication in our complex, information-rich world.
- Winograde[4]: The Winograd Schema Challenge (WSC) dataset stands as a unique proving ground. Its carefully crafted sentences, each containing a subtle ambiguity, challenge models to demonstrate their ability to grasp real-world context and common sense reasoning.
Comparison between Models
The models under consideration in this comparative analysis have undergone pre-training on diverse datasets, ensuring a comprehensive evaluation. It is pertinent to note that all models have been trained on identical hardware, thereby maintaining a fair and consistent basis for comparison. The performance metrics for Llama-2 have been obtained from a third-party source, distinct from the Hugging Face database, while all other results are sourced directly from the Hugging Face database. This approach is employed to uphold the integrity and impartiality of the assessment, fostering a robust and reliable evaluation of the models in question.
Table1. Benchmarks of Llama language model on dataset.
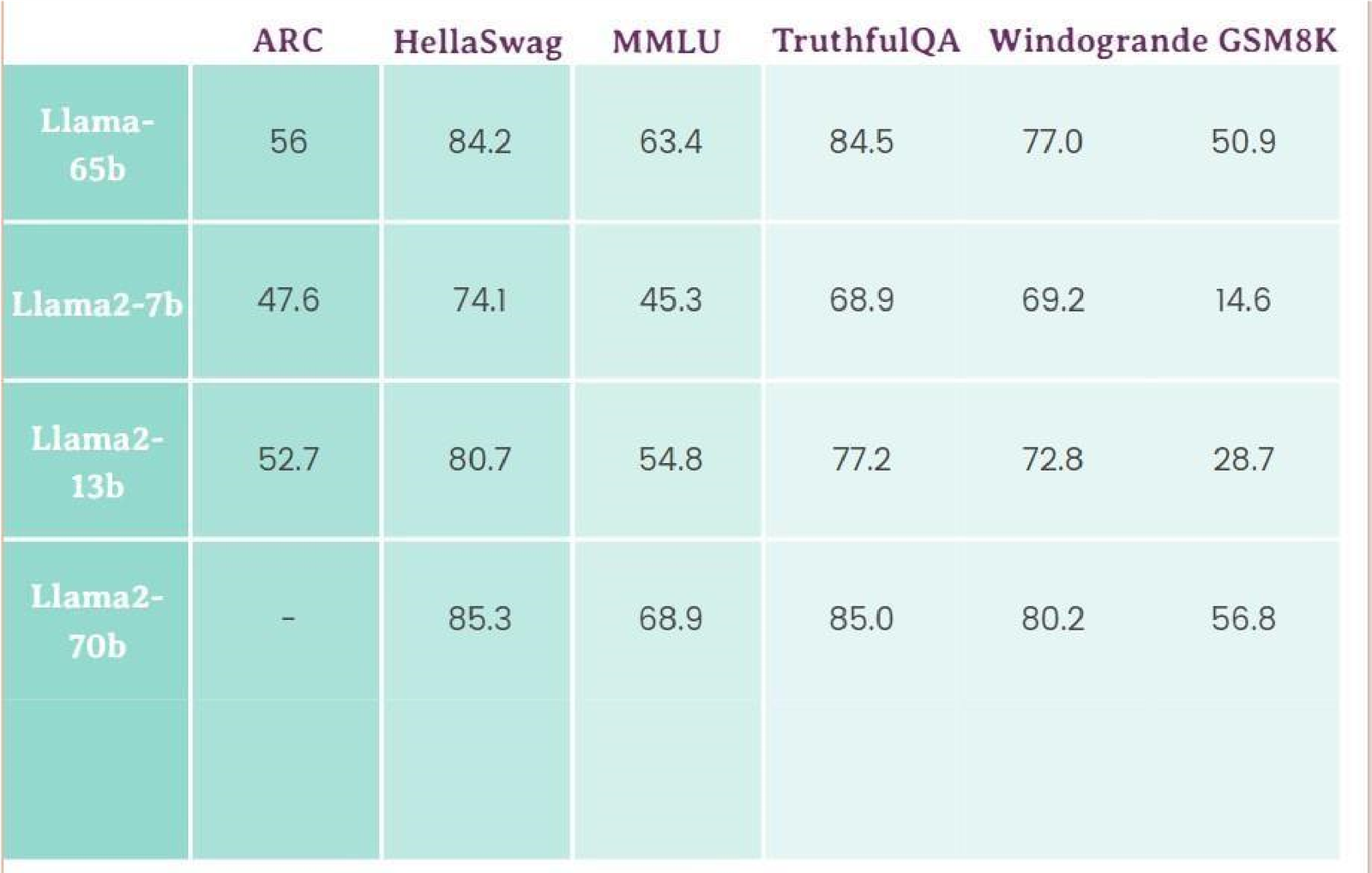
Table2. Benchmarking MPT large language model on test dataset
.
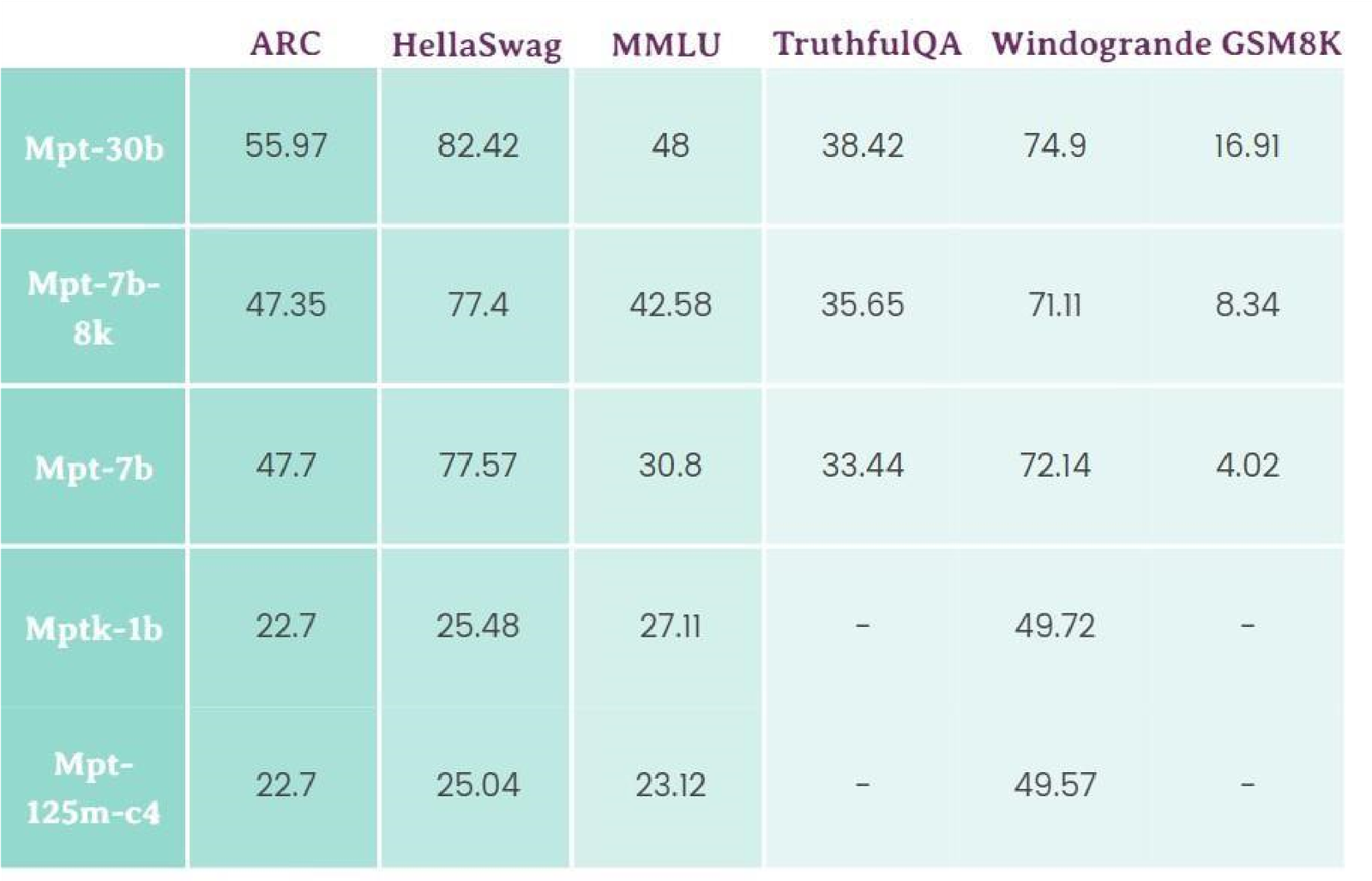
 Table3. Benchmarks of Falcon language model on dataset.
Table3. Benchmarks of Falcon language model on dataset.
Conclusion
The exploration and comparison of open-source Large Language Models (LLMs) have revealed a significant surge in their capabilities over the past year. This growth is attributed to collaborative efforts within the open-source community, driven by factors such as increased data availability, advancements in training techniques, and a growing demand for AI solutions. The transparency, accessibility, and customizability of these models position them as compelling alternatives to closed-source counterparts like GPT-4. Despite these advancements, a notable challenge in the open-source LLM landscape is the lack of universally agreed-upon evaluation criteria. This complicates the comparison and selection of models for specific tasks. However, the emergence of benchmarking techniques such as MMLU and ARC aims to address this challenge by providing standardized frameworks for evaluating the performance of opensource LLMs across various tasks.
In summary, the open-source LLM landscape is evolving rapidly, offering increased capabilities and alternatives to closed-source models. The challenges related to evaluation criteria are being addressed through benchmarking techniques, enhancing the ability to make informed decisions when selecting models for specific applications.
References
- [1] Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., & Choi, Y. (2019). HellaSwag: Can a Machine Really Finish Your Sentence? ArXiv. /abs/1905.07830
- [2] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2020). Measuring Massive Multitask Language Understanding. ArXiv. /abs/2009.03300
- [3] Lin, S., Hilton, J., & Evans, O. (2021). TruthfulQA: Measuring How Models Mimic Human Falsehoods. ArXiv. /abs/2109.07958
- [4] Levesque, Hector J., Ernest Davis, and Leora Morgenstern. “The Winograd Schema Challenge.” In Proceedings of the Thirteenth International Conference on Principles of Knowledge Representation and Reasoning, pp. 572-581. AAAI Press, 2012. (https://aaai.org/conference/aaai/aaai12/)
- [5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. ArXiv. /abs/1706.03762
- Deveci, M., Pamucar, D., Gokasar, I., Köppen, M., Gupta, B. B., & Daim, T. (2023). Evaluation of Metaverse traffic safety implementations using fuzzy Einstein based logarithmic methodology of additive weights and TOPSIS method. Technological Forecasting and Social Change, 194, 122681.
- Chaklader, B., Gupta, B. B., & Panigrahi, P. K. (2023). Analyzing the progress of FINTECH-companies and their integration with new technologies for innovation and entrepreneurship. Journal of Business Research, 161, 113847.
- Casillo, M., Colace, F., Gupta, B. B., Lorusso, A., Marongiu, F., & Santaniello, D. (2022, June). A deep learning approach to protecting cultural heritage buildings through IoT-based systems. In 2022 IEEE International Conference on Smart Computing (SMARTCOMP) (pp. 252-256). IEEE.
- Jiao, R., Li, C., Xun, G., Zhang, T., Gupta, B. B., & Yan, G. (2023). A Context-aware Multi-event Identification Method for Non-intrusive Load Monitoring. IEEE Transactions on Consumer Electronics.
- Wang, L., Han, C., Zheng, Y., Peng, X., Yang, M., & Gupta, B. (2023). Search for exploratory and exploitative service innovation in manufacturing firms: The role of ties with service intermediaries. Journal of Innovation & Knowledge, 8(1), 100288.
Cite As
Rajput D (2024) Exploring and Comparing Open-Source Large Language Models, Insights2Techinfo