By: ESHMEET SINGH BHACHU, Department of CSE, Chandigarh College of Engineering and Technology, Panjab University, Chandigarh, Email- MCO23377@ccet.ac.in
Abstract
The advent of Large Language Models (LLMs) has led to the creation of advanced models that can produce coherent and context-appropriate text outputs. Despite being intelligent in nature, however, the models lack any form of memory persistence and exist in a limited contextual environment. The paper considers the idea of memory in LLMs by considering the use of context windows in terms of their ability to store information temporarily and limitations, as well as newer concepts like RAG and vector memory systems. It concludes that the development of AI is progressing towards more context-oriented and persistent models despite remaining architecturally limited.
Keywords
Large Language Models, Context Window, AI Memory, RAG, Vector Databases, Tokenization
Introduction
The quick evolution of Large Language Models has resulted in substantial changes for both natural language processing and human-computer communication. The applications using transformer-based architecture exhibit their capacity to produce human-like messages, perform reasoning and even help to implement complex workflow [1], [2]. However, despite all these features, one essential issue still exists the absence of memory.
While traditional software solutions retain the current state between sessions, LLMs lack this feature. They are completely stateless models that treat each entry independently without any context until it is supplied explicitly [2]. Thus, it poses a crucial question of how LLMs work with memory and what the limits of this process are.
In this article, we discuss the methods of dealing with context information within LLMs, as well as their limits and new approaches developed to expand memory [9]–[11].
Memories in Large Language Models
In biological beings, memories refer to the retention and recall of knowledge. However, LLMs utilize contextual representations, wherein all necessary information should fit within the input sequence. The basic building blocks of this context consist of tokens, pieces of text handled by the machine learning model [4], [7]. All tokens combined constitute the context window, which acts as the temporary working memory for the model. LLMs lack any form of permanent memory other than the context window. After completing a session or when the context limit has been reached, any information preceding that will be forgotten. Hence, the perception of memory in LLMs is more accurately described as a form of short-term contextual consciousness.
Foundations of Memory in Architectures Used by Transformer Models
Transformer-based Large Language Models (LLMs) make use of a self-attention mechanism as a key building block that enables the analysis of input sequences without requiring any explicit storage. Unlike memory-based models, transformers do not store data directly but rather derive relations between tokens while performing inference [1]. The self-attention mechanism allows each token in a sequence to focus on every other token in the same sequence, enabling the analysis of contextual dependencies and semantic relations [1][4]. This constitutes the underlying principle of memory simulation for LLMs as they can only make use of information contained within an input sequence. Conversely, the self-attention mechanism entails some computational limitations due to quadratic growth in the number of computations performed during attention. This implies that the notion of memory in LLMs is closely associated with efficient and scalable attention mechanisms[6].
Context Window: The Natural Memory System of the Model
The context window determines the largest amount of tokens that can be processed by the LLM at any point in time. The context window serves as the memory space where the model carries out its attention operations [5], [6].
The context window size in contemporary LLMs is becoming larger, with some models having context windows that hold over 100,000 tokens. This development has resulted in:
- The ability to conduct long conversations
- Better document analysis capabilities
- Better coherence when processing long texts
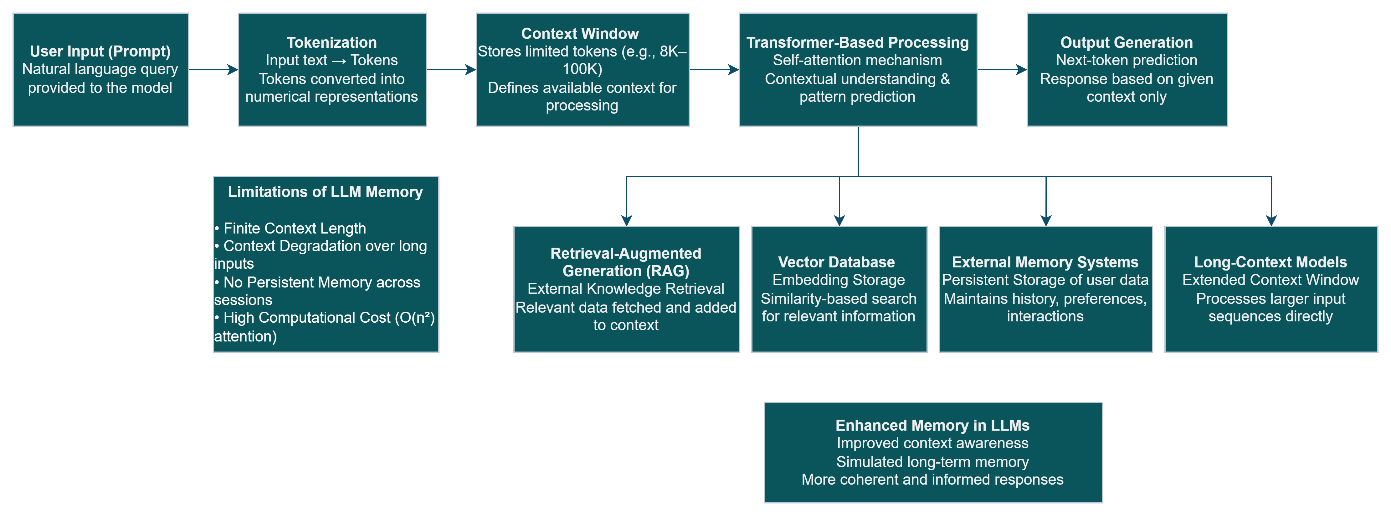
Memory Limitations of LLMs
- Restricted Context Window Size
The primary constraint is the fixed window size. Once it exceeds its capacity, it becomes impossible for the model to retain prior information [1].
- Degradation of Contextual Attention
With increasing input length, the capacity of the model to pay equal attention to each token decreases. This implies a degradation in remembering the initial part of the input.
- No Built-In Persistence
Inherently, large language models cannot remember information between sessions. They have to be reminded in each instance of their interaction.
- Heavy Computation
Attention mechanisms are computationally intensive and have quadratic time complexity. Therefore, larger window sizes would require more computation.
Novel Enhancements for Memory Support
- RAG Systems (Retrieval-Augmented Generation)
The RAG architecture allows for the retrieval of useful external information prior to responding with a generated message, which means the system has access to large amounts of information to work with, acting as long-term memory, but without expanding the model [3].
- Vector Databases and Embeddings
With vector databases, high-dimensional representations (or embeddings) of text data are used. With similarity searches, the LLM systems may retrieve relevant contextual information [7].
- External Memory Models
In modern AI systems, external layers for storing user interactions and other historical data are implemented, providing the system with a memory feature that does not rely solely on the model itself [9].
- Models with Extended Context Window
The trend among researchers at present revolves around extending the model’s context window and making it able to process large amounts of information, despite its inefficiency.Future Directions
Directions for the Future
The development of memory for large language models seems to be developing into architectures that will allow for internal contextual understanding alongside external memory. Some future trends can be:
- AI memory for the individual user
- Efficient attention models for contextual understanding
- Symbolic and neural memories
Such developments attempt to fill the void between contextual inference and long term knowledge acquisition.
Conclusion
Large Language Models are indeed a major milestone in the development of artificial intelligence technology; however, the absence of inherent memory is an important deficiency to address. With the help of context windows, Large Language Models mimic short-term memory; however, this process still faces limitations due to the limited nature of its storage and non-permanent nature [9]–[11]. RAG and vectorized memory models are becoming increasingly popular in the realm of AI technologies [3]. Moving forward, the implementation of scalable memory architectures can be considered an important element in developing more advanced AI solutions.
References
- A. Vaswani et al., “Attention Is All You Need,” Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017.
- T. B. Brown et al., “Language Models are Few-Shot Learners,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1877–1901, 2020.
- P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 9459–9474, 2020.
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” Proceedings of NAACL-HLT, pp. 4171–4186, 2019.
- OpenAI, “GPT-4 Technical Report,” 2023.
- Google Research, “PaLM: Scaling Language Modeling with Pathways,” 2022.
- J. Pennington, R. Socher, and C. D. Manning, “GloVe: Global Vectors for Word Representation,” Proceedings of EMNLP, pp. 1532–1543, 2014.
- S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- Singla, V., Singh, S. K., Kumar, S., Chhabra, A., Gill, S. S., Arya, V., & Jain, A. (2025). Challenges and Opportunities in Sustainable AI and Information Systems. In B. Gupta, D. Pramod, & M. Moslehpour (Eds.), Sustainable Information Security in the Age of AI and Green Computing (pp. 73-96). IGI Global Scientific Publishing.
- Chopra, M., Singh, S. K., Sharma, S., & Mahto, D. (2021). Impact and Usability of Artificial Intelligence in Manufacturing workflow to empower Industry 4.0. CEUR Workshop Proceedings, 3080.
- H. Vashisht, Singh, S. K., S. Kumar, N. Singh, V. Arya, K. T. Chui, and B. B. Gupta,
- “IoT-XPLAIN: Intelligent Fault Detection and Natural Language Explanation for IoT Systems Using ML and LLMs,” in Proceedings of the 28th International Conference on Advanced Communications Technology (ICACT), 2026, pp. 1–6.
- Ho, G. T. S., Tang, Y. M., Lam, H. Y., & Tang, V. (2023). A Blockchain-based Decision Support System for E-commerce Order Prediction. International Conference on Artificial Intelligence in Information and Communication (ICAIIC) Bali, Indonesia, pp. 041-045.
- Lam, H. Y., Tang, V., & Ho, G. T. S. (2023). A Digital Twins Model for Analyzing and Simulating Cold Chain Risks. International Conference on Artificial Intelligence in Information and Communication (ICAIIC) Bali, Indonesia, pp. 259-263.
- Wang, Y., Mo, D. Y., & Ho, G. T. S. (2023). How Choice Fatigue Affects Consumer Decision Making in Online Shopping. In 2023 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), USA, pp. 0128-0132.
Cite As
BHACHU E.S., (2026) The Role of Memory in Large Language Models: Context Windows, Limitations, and Emerging Extensions, Insights2Techinfo, pp.1