By: C S Nakul Kalyan; Asia University
Abstract
In this study, we will propose a detection framework against voice-to-voice translation with lip sync in multilingual deepfakes. This is one of the advanced technologies in deepfakes, which can create a manipulation of voice translation with lip sync deepfakes. The proposed model to detect this manipulated content is a combination of three strategies, such as phoneme-viseme alignment analysis to find the inconsistencies in mouth closure, audio-visual feature extraction using Automatic speech recognition (ASR), and Visual Speech Recognition (VSR) which can be used to detect weather the audio is matching the situation, and a cross-modal transcription mismatch analysis have been used to compare the audio and video transcriptions are same and matching to the environment. By using these methods, the framework makes sure that the synchronization for multilingual voice translation is accurate, and it provides a good detection accuracy against the manipulated lip-sync deepfakes.
Keywords
Voice-to-Voice Translation, Lip-Sync Deepfakes, Multilingual speech synthesis, Phoneme-viseme alignment, Deepfake detection, audio-video speech recognition.
Introduction
The fast advancement of Artificial Intelligence (AI) in speech and video manipulation has lead a path to create a highly realistic lip-sync deepfakes where the voices can be cloned, it can be translated, and it can be merged with the facial movements in various languages. Even though lip sync deepfakes can be applied in platforms such as entertainment and education, but also pose a major risk in spreading misinformation, fraud, and identity theft, and lead to misuse of the technology. Detecting these kinds of manipulations is challenging, as lip sync deepfakes change only the mouth region, while keeping the rest of the facial parts as the original ones [3]. To counter these misuses, the study proposes a combined framework of phoneme-viseme mismatches – used to detect the inconsistencies in the mouth closure part [1], second is audio-visual feature extraction methods – uses automatic and Visual Speech recognitions (ASR) and (VSR), and uses deep architectures such as conformer and transformer networks, and detects weather the audio is matching the situation and environment of the video [5]. The third strategy is to use the cross-modal transcription, which will be used to detect the semantic agreement between the audio and lip-reading outputs [2]. By utilizing this integrated framework, this article will explore the detection of multilingual voice-to-voice lip-sync translation, and also identify whether the content is real or a deepfake. Utilizing these techniques enhances the model’s ability to detect deepfakes in multilingual contexts.
Proposed Methodology
This study proposes a detection Framework for detecting multilingual voice-to- voice translation deepfakes with manipulated lip movements, where the multi- modal methodology and the overall Framework are proposed in below Figure 1:
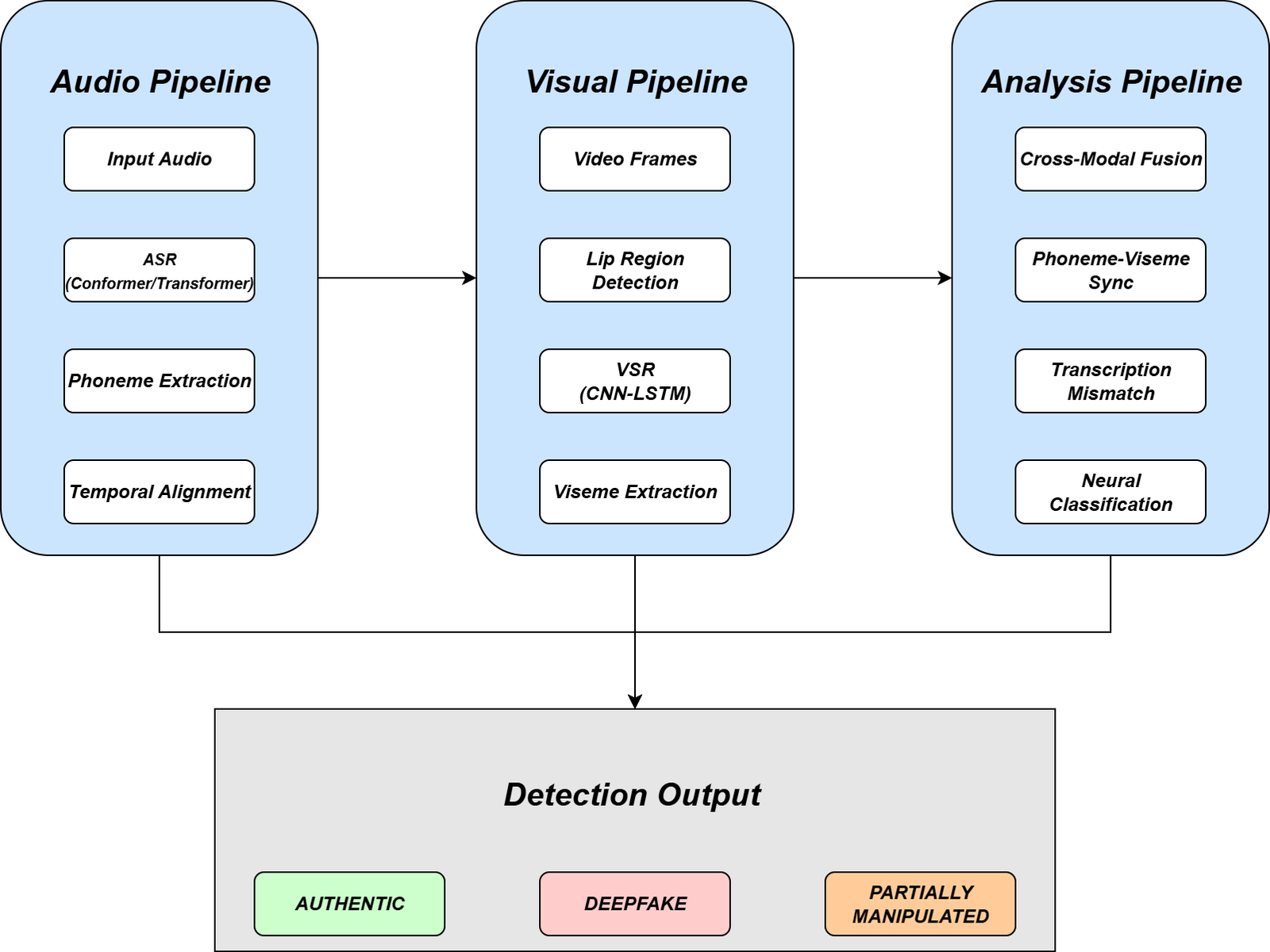
Dataset Construction and Collection
Multilingual Sources
The datasets for training have been taken from multilingual speeches such as GRID, LRS2, LRS3, TED talks, news interviews, etc., where the data contain different kinds of speakers, languages, and dialects, and these datasets contain controlled and uncontrolled scenarios.
Annotation Process
The Annotation Process is done by both human and automated tools, which will be based on:
Phoneme-Viseme Alignment:
This annotation process will be done based on the identification of the lip- closures where the (M, B, P) Sounds are analyzed here [1]. The phoneme-viseme mapping for critical sounds has been shown in Table 1 below:
Table 1: Phoneme–Viseme Mapping for Critical Sounds
Phoneme | Example Word | Expected Viseme (Mouth Shape) | Detection Relevance |
M | mother | Lips fully closed | Strong detection signal |
B | brother | Lips fully closed | Strong detection signal |
P | parent | Lips fully closed | Strong detection signal |
F/V | fun / very | Upper teeth on lower lip | Medium detection signal |
CH/JH/SH | chair / jar / she | Lips rounded, teeth visible | Medium detection signal |
Translation Accuracy:
This Translation accuracy is been annotated by evaluating the translated speech among the various languages, where it will find the accuracy based on the speeches that have been translated to other languages.
Authenticity Labeling:
The Authenticity Labeling is done by differentiating the videos as real, deepfake, or partially manipulated.
Audio Feature Extraction
speech-to-text Alignment
The Feature extraction for speech-to-text alignment is done by Automatic Speech Recognition (ASR) models, such as ResNet-18 with Conformer or Transformer- based ASR have been used to extract the features and convert the speech into Phoneme sequences with the timestamps included.
Multilingual Voice Conversion
The Multilingual Voice Conversion is used for translating Text-to-Speech (TTS) or Voice Cloning models, which are used to generate speech for the target language and have the identity of the speaker. After the generation of audio, it is mapped to phoneme units for cross-verification.
Visual Feature Extraction
Lip-Region Detection
For the process of visual feature extraction, it mainly extracts the mouth region where it is localized, cropped, and standardized for every frame by using tools like OpenFace or Mediapipe.
Lip Reading (VSR)
For capturing Lip reading, Visual Speech Recognition (VSR) models such as CNN-LSTM or Auto-AVSR have been used to predict viseme sequences from lip movements [5]. These sequences are aligned with the audio phoneme predictions, too.
Phoneme-Viseme Synchronization
The Phoneme-Viseme Synchronization has been using techniques such as those given in Figure 2 below:
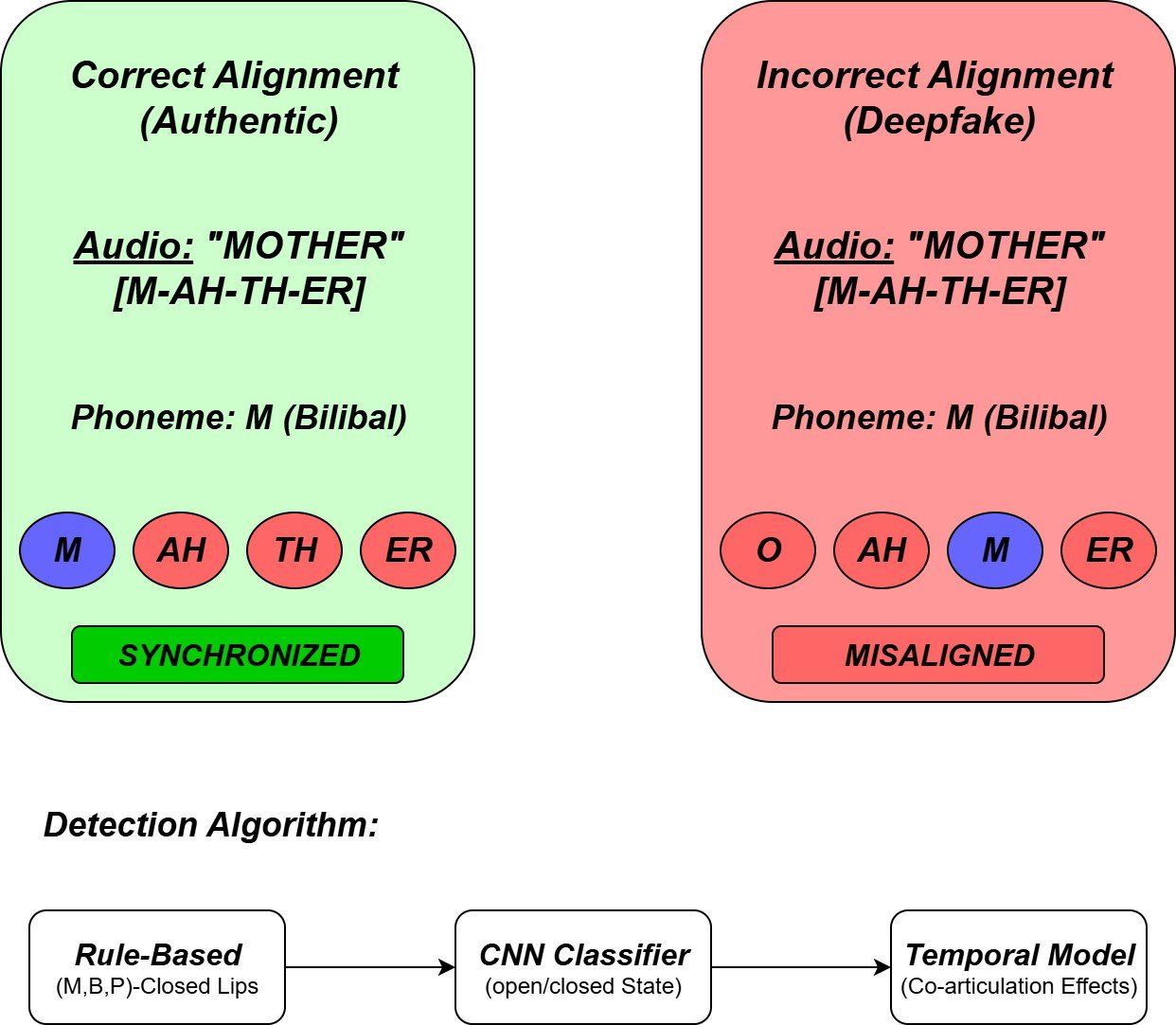
Rule-Based Detection:
In rule-based detection, the main phonemes such as M, B, and P have been analyzed to closed lip visemes [1], and any mismatches between them will be signaled for manipulation.
Neural Classifiers:
In the Neural Classifiers, a CNN model will be used to predict the open/closed mouth states, which will be done across all the frames. where the features extracted from the lip region will be used for mismatch detection [4].
temporal context model:
The temporal Context model will use transformers and conformer models to find the co-articulation effects, such as when the adjacent phonemes will be used to alter the lip shape will make sure to detect minor inconsistencies that come from the process of desynchronization [4].
Dual Transcription Mismatch Analysis
The Dual transcription mismatch analysis will be done on the audio and video transcription, and the comparison between them will be done to find the mis- matches [2]. The processes that are done here are:
Audio Transcription:
In audio Transcription, by the usage of ASR models, the audio track is being transcribed into text.
Video Transcription:
In video Transcription, the Lip reading system (VSR) is used to transcribe the content that is spoken from the speech directly from the video frames [6].
Cross-Modal Comparison:
Here the mismatches which is detected from audio and video transcriptions have been measured by tools such as Levenshtein distance and Word Error Rate (WER) [2]. The cut-off point, such as 0.5, states the difference between the real and fake content.
Multilingual Translation Synchronization
Voice-to-Voice Translation
In the voice translation, the main speech has been translated into a different language by using a machine translation tool, and then the TTS is been used to detect the cloned voice from the translated speech.
Lip-Sync Generation
In the lip-sync generation, the Lip movements are being cross-checked with the translated speech using models such as Wav2Lip [7], where the mismatched lip movements are considered as a manipulated video. The Phoneme-viseme map- ping is being used to ensure that the natural alignment across all the processes is done.
Cross-Language Evaluation
The cross-language evaluation is being done to test the durability of the lip-sync accuracy in both tonal and non-tonal languages.
Classification and Detection Framework
The Classification and detection framework was done by using the authenticity classification and Specific deepfake detection, such as:
Authenticity Classification:
In the Authenticity classification, based upon the mismatching levels, the videos will be classified as real, partially manipulated, or it’s a deepfake video.
Deepfake-Specific Detection:
In the deepfake-specific detection, the mismatches, such as delayed lip closure or unnatural viseme transitions, are being directly considered as lip-sync deepfakes [3]. This is how the deepfake-specific detection is being done.
Evaluation Metrics
Evaluation metrics are calculated by three metrics, such as standard metrics, Synchronization Metrics, and Robustness Testing, which have been explained below.
Standard Metrics
The standard metrics have been measured using the Accuracy, Precision, Recall, and F1-score.
Synchronization Metrics
The Synchronization Metrics have been measured by 2 sources such as Lip- sync Error Rate (LSER), which will be used to measure the mismatch between phoneme and viseme alignment, and the other source is Translation Consistency (TCS), which will be used to measure the accuracy of multilingual voice-to-voice synchronization.
Robustness Testing
The Performance is compared by different video lengths (15s-5min), Multiple resolutions (20-128 IPD), and multilingual contexts, and the result for finding the robustness of the model has been decided by the above details.
The detection performance across methods has been shown in Table 2 below, Table 2: Detection Performance Across Methods
Method | Accuracy (%) | Strength | Limitation |
Phoneme–Viseme Alignment | 90–97 | Linguistic consistency, explainable features | Needs clear mouth visibility |
ASR + VSR Neural Fusion | 85–95 | Captures temporal & multimodal inconsistencies | Requires large datasets, computational cost |
Cross-Modal Transcription Mismatch | 95–99 | Robust across lengths & resolutions | May degrade on very short clips |
Conclusion
This study proposed an integrated method for detecting lip-to-voice translation with lip synchronization in multilingual deep-fakes. This integrated framework ensures an accurate detection against the multilingual deepfakes and provides a strong defense against the manipulated lip-sync content by combining features such as phoneme-viseme analysis, audio-visual feature fusion by ASR and VSR encoders, and cross-modal transcription to evaluate the mismatches using WER and normalized Levenshtein distance. The future work for this detection frame- work can be done to detect the deepfake from low-resource languages, real-time detection, and adaptive adversarial settings to further build trust in people to utilize multilingual speech and video synthesis.
References
- Shruti Agarwal, Hany Farid, Ohad Fried, and Maneesh Agrawala. Detect- ing deep-fake videos from phoneme-viseme mismatches. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition work- shops, pages 660–661, 2020.
- Matyas Bohacek and Hany Farid. Lost in translation: Lip-sync deepfake detection from audio-video mismatch. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4315–4323, 2024.
- Soumyya Kanti Datta, Shan Jia, and Siwei Lyu. Exposing lip-syncing deep- fakes from mouth inconsistencies. In 2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024.
- Soumyya Kanti Datta, Shan Jia, and Siwei Lyu. Detecting lip-syncing deepfakes: Vision temporal transformer for analyzing mouth inconsisten- cies. arXiv preprint arXiv:2504.01470, 2025.
- Sahibzada Adil Shahzad, Ammarah Hashmi, Yan-Tsung Peng, Yu Tsao, and Hsin-Min Wang. Av-lip-sync+: Leveraging av-hubert to exploit multimodal inconsistency for video deepfake detection. arXiv preprint arXiv:2311.02733, 2023.
- G Sornavalli and Priyanka Vijaybaskar. Deepfake detection by prediction of mismatch between audio and video lip movement. In 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), pages 01–08. IEEE, 2024.
- Abhijit Thikekar, Riya Menon, Saurav Telge, Gauravi Tolamatti, et al. Gen- erative adversarial networks based viable solution on dubbing videos with lips synchronization. In 2022 6th International Conference on Computing Methodologies and Communication (ICCMC), pages 1671–1677. IEEE, 2022.
- Panigrahi, R., Bele, N., Panigrahi, P. K., & Gupta, B. B. (2024). Features level sentiment mining in enterprise systems from informal text corpus using machine learning techniques. Enterprise Information Systems, 18(5), 2328186.
- Gupta, B. B., Gaurav, A., Chui, K. T., & Arya, V. (2024, January). Deep learning-based facial emotion detection in the metaverse. In 2024 IEEE International Conference on Consumer Electronics (ICCE) (pp. 1-6). IEEE.
- Gaurav, A., Gupta, B. B., & Chui, K. T. (2022). Edge computing-based DDoS attack detection for intelligent transportation systems. In Cyber Security, Privacy and Networking: Proceedings of ICSPN 2021 (pp. 175-184). Singapore: Springer Nature Singapore.
Cite As
Kalyan C S N (2025) Voice-to-Voice Translation with Lip Sync: A New Era in Multilingual Deepfakes, Insights2Techinfo, pp.1